Ett proxylager kan vara ganska användbart för att öka tillgängligheten för din databasnivå. Det kan minska mängden kod på applikationssidan för att hantera databasfel och replikeringstopologiändringar. I det här blogginlägget kommer vi att diskutera hur man ställer in en HAProxy för att fungera ovanpå PostgreSQL.
Först till kvarn - HAProxy fungerar med databaser som en proxy för nätverkslager. Det finns ingen förståelse för den underliggande, ibland komplexa, topologin. Allt HAProxy gör är att skicka paket på ett round-robin-sätt till definierade backends. Den inspekterar inte paket och förstår inte heller protokoll där applikationer pratar med PostgreSQL. Som ett resultat finns det inget sätt för HAProxy att implementera läs/skrivdelning på en enda port - det skulle kräva analys av frågor. Så länge som din applikation kan dela läsningar från skrivningar och skicka dem till olika IP-adresser eller portar, kan du implementera R/W-delning med två backends. Låt oss ta en titt på hur det kan göras.
HAProxy-konfiguration
Nedan kan du hitta ett exempel på två PostgreSQL-backends konfigurerade i HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkSom vi kan se använder de portar 3307 för att skriva och 3308 för att läsa. I den här installationen finns det tre servrar - en aktiv och två standby-repliker. Vad som är viktigt, tcp-check används för att spåra nodernas hälsa. HAProxy kommer att ansluta till port 9201 och förväntar sig att en sträng returneras. Friska medlemmar av backend kommer att returnera förväntat innehåll, de som inte kommer att returnera strängen kommer att markeras som otillgängliga.
Xinetd-installation
När HAProxy kontrollerar port 9201 måste något lyssna på den. Vi kan använda xinetd för att lyssna där och köra några skript åt oss. Exempel på konfiguration av en sådan tjänst kan se ut så här:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Du måste se till att du lägger till raden:
postgreschk 9201/tcptill /etc/services.
Xinetd startar ett postgreschk-skript, som har innehåll som nedan:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Manusets logik ser ut som följer. Det finns två frågor som används för att detektera nodens tillstånd.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Den första kontrollerar om PostgreSQL är under återställning - det kommer att vara "falskt" för den aktiva servern och "true" för standby-servrar. Den andra kontrollerar om PostgreSQL är i skrivskyddat läge. Den aktiva servern kommer att återgå "av" medan standby-servrar kommer att återgå "på". Baserat på resultaten anropar skriptet return_ok()-funktionen med en rätt parameter ('master' eller 'slave', beroende på vad som upptäcktes). Om frågorna misslyckades kommer en "return_fail"-funktion att exekveras.
Return_ok-funktionen returnerar en sträng baserat på argumentet som skickades till den. Om värden är en aktiv server kommer skriptet att returnera "PostgreSQL master körs". Om det är ett standbyläge kommer den returnerade strängen att vara:"PostgreSQL slav körs". Om tillståndet inte är klart kommer det att returnera:"PostgreSQL körs". Det är här slingan slutar. HAProxy kontrollerar tillståndet genom att ansluta till xinetd. Den senare startar ett skript, som sedan returnerar en sträng som HAProxy analyserar.
Som du kanske minns förväntar sig HAProxy följande strängar:
tcp-check expect string master\ is\ runningför skrivbackend och
tcp-check expect string is\ running.för skrivskyddad backend. Detta gör den aktiva servern till den enda värden som är tillgänglig i skrivbackend medan på läsbackend kan både aktiva och standby-servrar användas.
PostgreSQL och HAProxy i ClusterControl
Inställningen ovan är inte komplex, men det tar lite tid att ställa in den. ClusterControl kan användas för att ställa in allt detta åt dig.
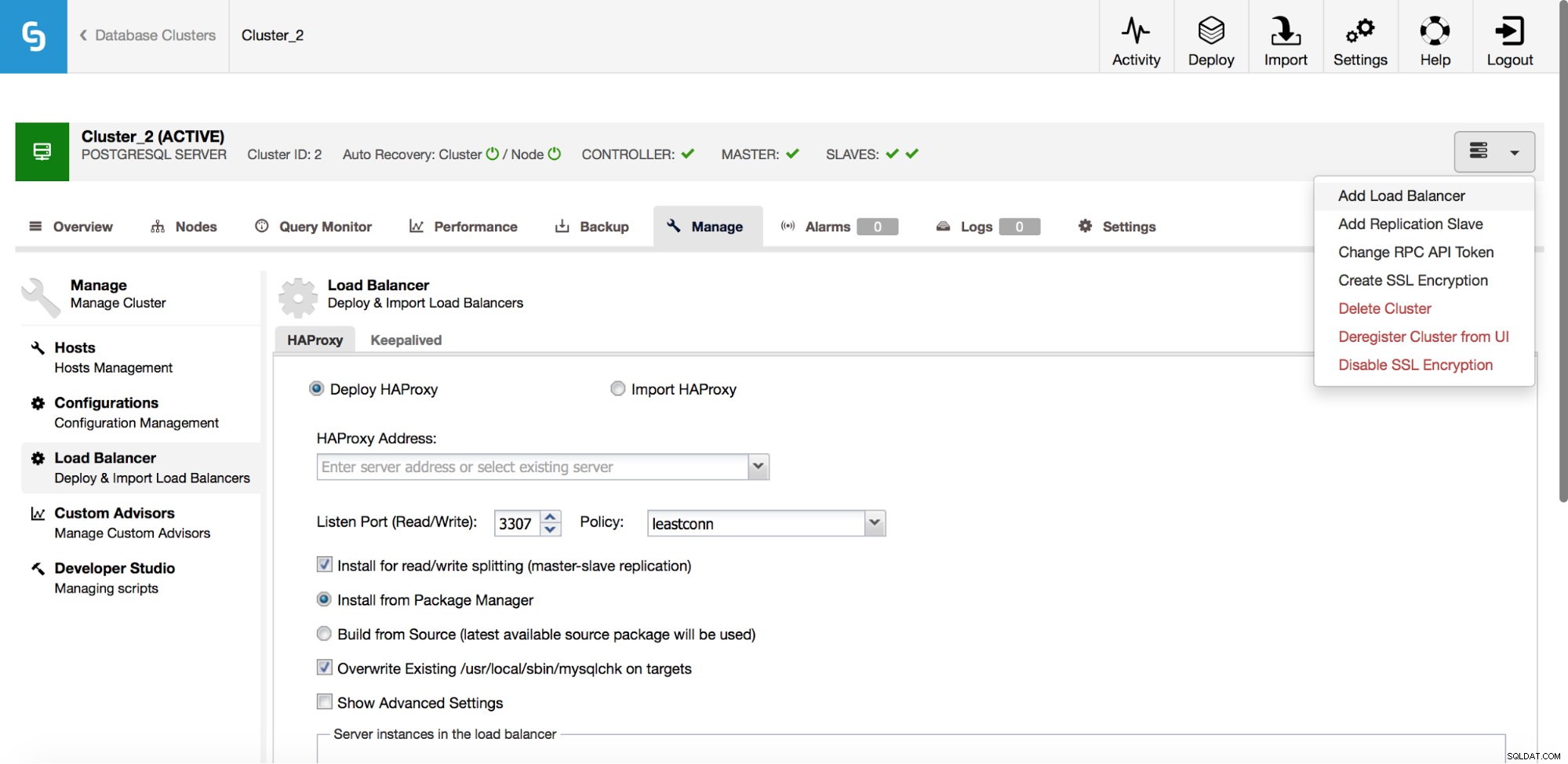
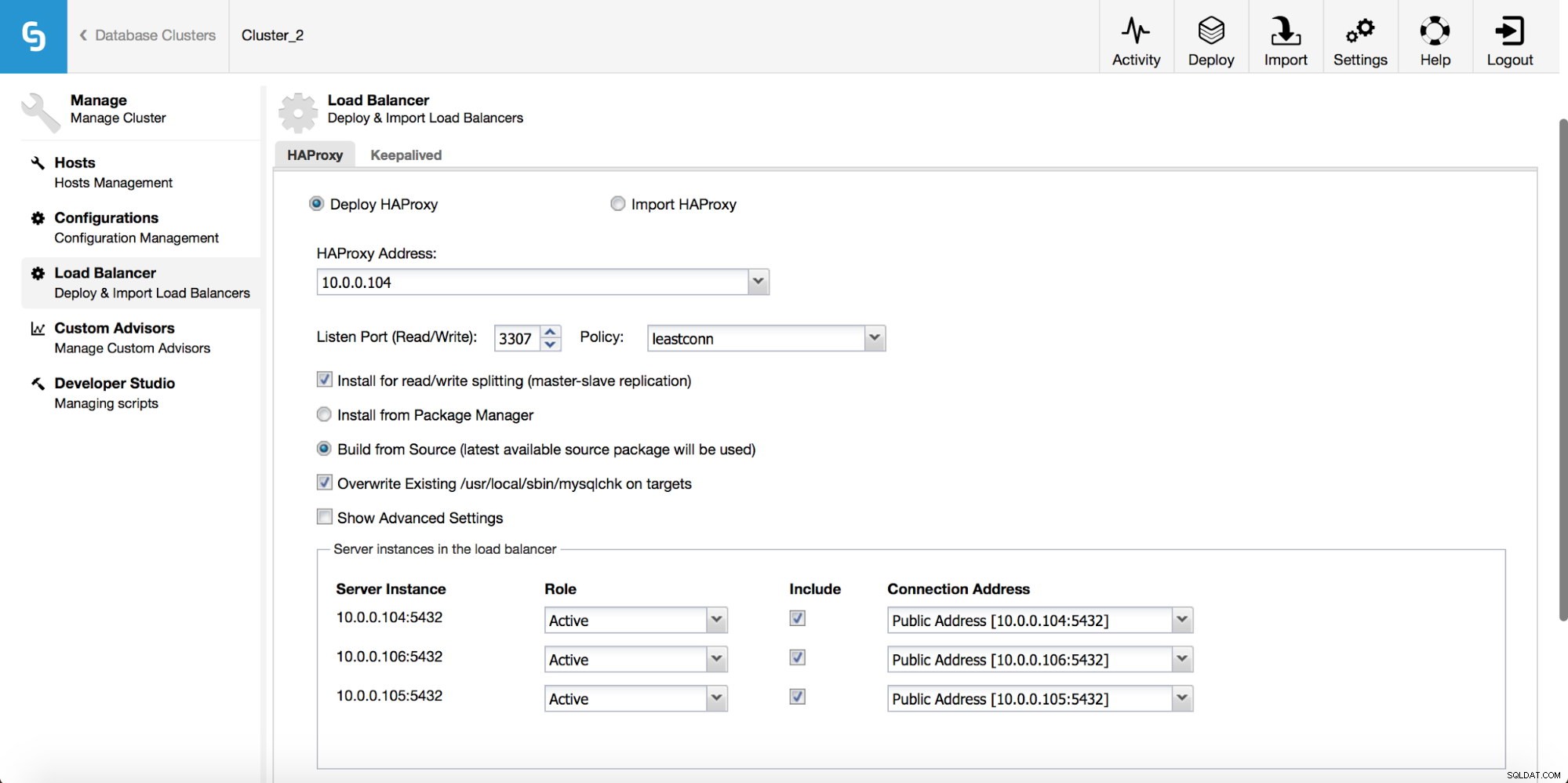
I rullgardinsmenyn för klusterjobb har du ett alternativ att lägga till en lastbalanserare. Sedan dyker ett alternativ att distribuera HAProxy upp. Du måste fylla i var du vill installera det och fatta några beslut:från de förråd som du har konfigurerat på värden eller den senaste versionen, kompilerad från källkoden. Du måste också konfigurera vilka noder i klustret du vill lägga till i HAProxy.
När HAProxy-instansen har distribuerats kan du komma åt statistik på fliken "Noder":
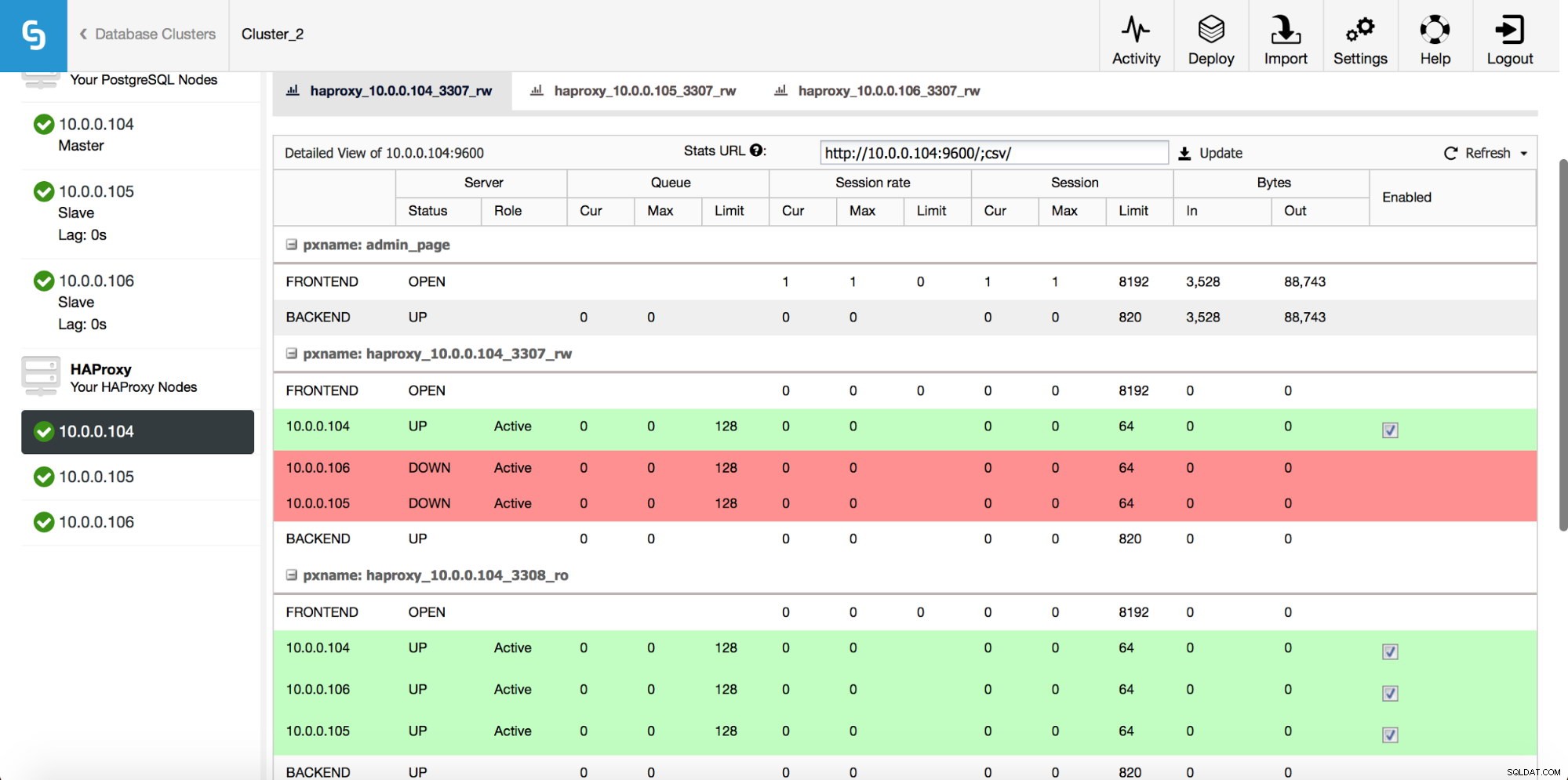
Som vi kan se, för R/W-backend, är endast en värd (aktiv server) markerad som upp. För skrivskyddad backend är alla noder uppe.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperBevaras
HAProxy kommer att sitta mellan dina applikationer och databasinstanser, så det kommer att spela en central roll. Det kan tyvärr också bli en enda felpunkt, skulle det misslyckas så finns det ingen väg till databaserna. För att undvika en sådan situation kan du distribuera flera HAProxy-instanser. Men då är frågan - hur man bestämmer sig för vilken proxyvärd man ska ansluta till. Om du distribuerade HAProxy från ClusterControl är det lika enkelt som att köra ytterligare ett "Add Load Balancer"-jobb, den här gången med Keepalved.
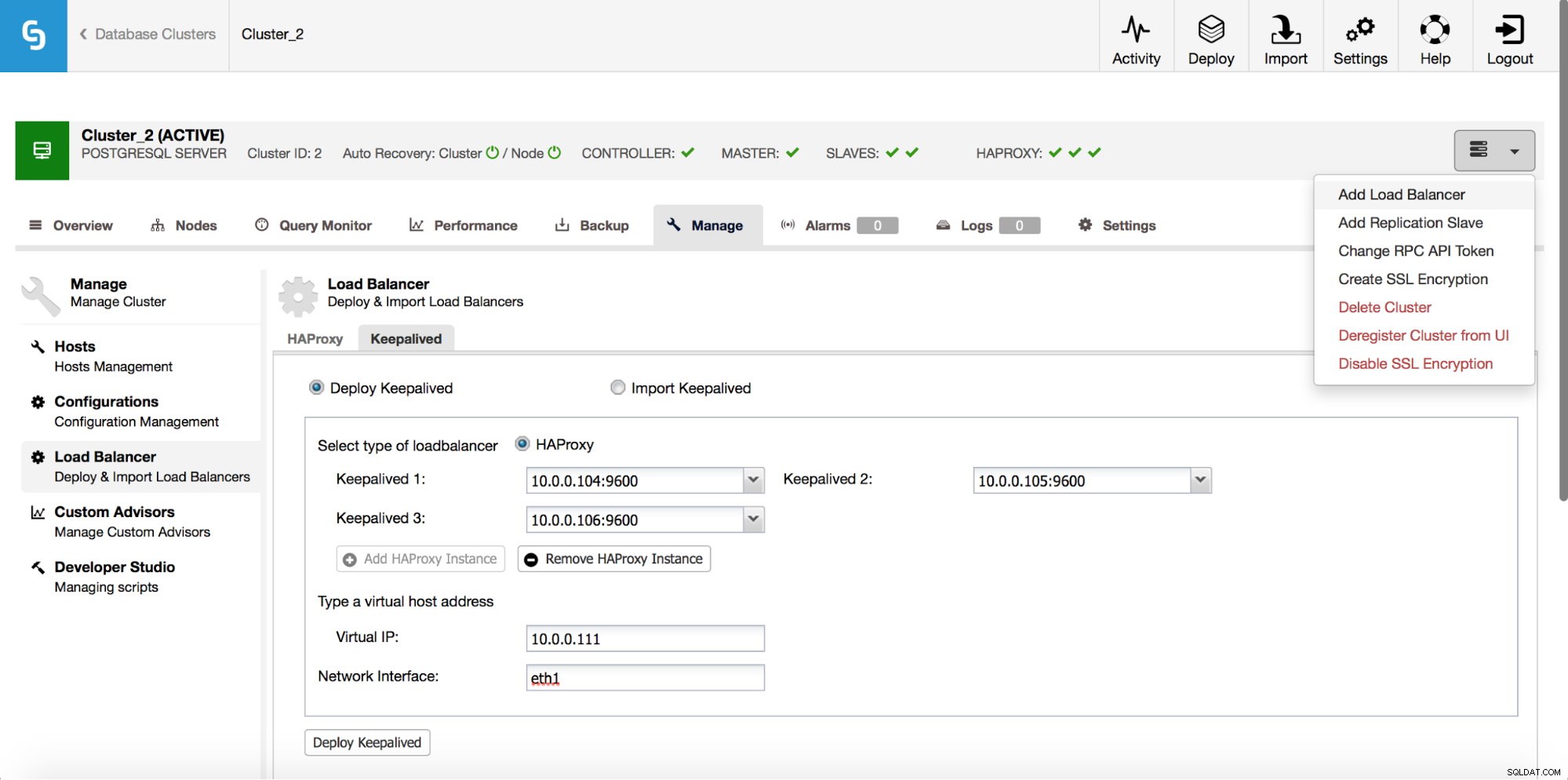
Som vi kan se i skärmdumpen ovan kan du plocka upp till tre HAProxy-värdar och Keepalved kommer att distribueras ovanpå dem och övervaka deras tillstånd. En virtuell IP (VIP) kommer att tilldelas en av dem. Din applikation bör använda denna VIP för att ansluta till databasen. Om den "aktiva" HAProxyn blir otillgänglig kommer VIP att flyttas till en annan värd.
Som vi har sett är det ganska enkelt att distribuera en full hög tillgänglighetsstack för PostgreSQL. Prova det och låt oss veta om du har feedback.