Ursprungligen postat på Serverless den 2 juli 2019

Att exponera en enkel databas via ett GraphQL API kräver mycket anpassad kod och infrastruktur:sant eller falskt?
För de som svarade "sant" är vi här för att visa att det är ganska enkelt att bygga GraphQL API:er, med några konkreta exempel för att illustrera varför och hur.
(Om du redan vet hur enkelt det är att bygga GraphQL API:er med serverlös, finns det mycket för dig i den här artikeln också.)
GraphQL är ett frågespråk för webb-API:er. Det finns en viktig skillnad mellan ett konventionellt REST API och API:er baserade på GraphQL:med GraphQL kan du använda en enda begäran för att hämta flera enheter samtidigt. Detta resulterar i snabbare sidladdningar och möjliggör en enklare struktur för dina frontend-appar, vilket resulterar i en bättre webbupplevelse för alla. Om du aldrig har använt GraphQL förut, föreslår vi att du kollar in den här GraphQL-handledningen för en snabb introduktion.
Det serverlösa ramverket passar utmärkt för GraphQL API:er:med Serverless behöver du inte oroa dig för att köra, hantera och skala dina egna API-servrar i molnet, och du behöver inte skriva några skript för automatisering av infrastrukturen. Läs mer om Serverless här. Dessutom ger Serverless en utmärkt leverantörs-agnostisk utvecklarupplevelse och en robust community som hjälper dig att bygga dina GraphQL-applikationer.
Många applikationer i vår vardagliga erfarenhet innehåller funktioner för sociala nätverk, och den typen av funktionalitet kan verkligen dra nytta av att implementera GraphQL istället för REST-modellen, där det är svårt att exponera strukturer med kapslade enheter, som användare och deras Twitter-inlägg. Med GraphQL kan du bygga en enhetlig API-slutpunkt som låter dig fråga, skriva och redigera alla enheter du behöver med en enda API-begäran.
I den här artikeln tittar vi på hur man bygger ett enkelt GraphQL API med hjälp av det serverlösa ramverket, Node.js, och någon av flera värdbaserade databaslösningar tillgängliga via Amazon RDS:MySQL, PostgreSQL och MySQL-arbetsliknande Amazon Aurora.
Följ med i detta exempelförråd på GitHub, och låt oss dyka in!
Bygga ett GraphQL API med en relationell DB-backend
I vårt exempelprojekt bestämde vi oss för att använda alla tre databaserna (MySQL, PostgreSQL och Aurora) i samma kodbas. Vi vet att det är överdrivet även för en produktionsapp, men vi ville blåsa bort dig med hur webbskala vi bygger. 😉
Men seriöst, vi överfyllde projektet bara för att se till att du skulle hitta ett relevant exempel som gäller din favoritdatabas. Om du vill se exempel med andra databaser, vänligen meddela oss i kommentarerna.
Definiera GraphQL-schemat
Låt oss börja med att definiera schemat för GraphQL API som vi vill skapa, vilket vi gör i filen schema.gql i roten av vårt projekt med hjälp av GraphQL-syntaxen. Om du inte är bekant med den här syntaxen, ta en titt på exemplen på denna GraphQL-dokumentationssida.
Till att börja med lägger vi till de två första objekten i schemat:en användarenhet och en postenhet, och definierar dem enligt följande så att varje användare kan ha flera inläggsenheter kopplade till sig:
skriv Användare {
UUID:String
Namn:String
Inlägg:[Inlägg]
}
skriv Post {
UUID:String
Text:Sträng
}
Vi kan nu se hur användar- och inläggsenheterna ser ut. Senare kommer vi att se till att dessa fält kan lagras direkt i våra databaser.
Låt oss sedan definiera hur användare av API:et ska fråga dessa enheter. Även om vi skulle kunna använda de två GraphQL-typerna User och Post direkt i våra GraphQL-frågor, är det bästa praxis att skapa indatatyper istället för att hålla schemat enkelt. Så vi går vidare och lägger till två av dessa inmatningstyper, en för inläggen och en för användarna:
mata in UserInput {
Namn:String
Inlägg:[PostInput]
}
mata in PostInput {
Text:Sträng
}
Låt oss nu definiera mutationerna - operationerna som modifierar data som lagras i våra databaser via vårt GraphQL API. För detta skapar vi en mutationstyp. Den enda mutationen vi kommer att använda för nu är createUser. Eftersom vi använder tre olika databaser lägger vi till en mutation för varje databastyp. Var och en av mutationerna accepterar ingången UserInput och returnerar en User-entitet:
Vi vill också tillhandahålla ett sätt att fråga användarna, så vi skapar en frågetyp med en fråga per databastyp. Varje fråga accepterar en sträng som är användarens UUID, vilket returnerar User-entiteten som innehåller dess namn, UUID, och en samling av alla associerade Pos``t:
Slutligen definierar vi schemat och pekar på fråge- och mutationstyperna:
schema { query: Query mutation: Mutation }
Vi har nu en fullständig beskrivning av vårt nya GraphQL API! Du kan se hela filen här.
Definiera hanterare för GraphQL API
Nu när vi har en beskrivning av vårt GraphQL API kan vi skriva koden vi behöver för varje fråga och mutation. Vi börjar med att skapa en handler.js-fil i projektets rot, precis bredvid filen schema.gql som vi skapade tidigare.
handler.js första jobb är att läsa schemat:
TypeDefs-konstanten innehåller nu definitionerna för våra GraphQL-entiteter. Därefter anger vi var koden för våra funktioner ska bo. För att hålla saker klar skapar vi en separat fil för varje fråga och mutation:
Resolverskonstanten innehåller nu definitionerna för alla våra API:s funktioner. Vårt nästa steg är att skapa GraphQL-servern. Kommer du ihåg graphql-yogabiblioteket vi krävde ovan? Vi kommer att använda det biblioteket här för att skapa en fungerande GraphQL-server enkelt och snabbt:
Slutligen exporterar vi GraphQL-hanteraren tillsammans med GraphQL Playground-hanteraren (som gör att vi kan prova vår GraphQL API i en webbläsare):
Okej, vi är klara med filen handler.js för tillfället. Nästa upp:att skriva kod för alla funktioner som kommer åt databaserna.
Skriv kod för frågorna och mutationerna
Vi behöver nu kod för att komma åt databaserna och för att driva vårt GraphQL API. I roten av vårt projekt skapar vi följande struktur för våra MySQL-resolverfunktioner, med de andra databaserna att följa:
Vanliga frågor
I Common-mappen fyller vi filen mysql.js med vad vi behöver för createUser-mutationen och getUser-frågan:en init-fråga, för att skapa tabeller för användare och inlägg om de inte finns ännu; och en användarfråga, för att returnera en användares data när man skapar och frågar efter en användare. Vi kommer att använda detta i både mutationen och frågan.
Init-frågan skapar både tabellerna Användare och Inlägg enligt följande:
GetUser-frågan returnerar användaren och deras inlägg:
Båda dessa funktioner exporteras; vi kan sedan komma åt dem i filen handler.js.
Skriva mutationen
Dags att skriva koden för createUser-mutationen, som måste acceptera namnet på den nya användaren, samt en lista över alla inlägg som tillhör dem. För att göra detta skapar vi filen resolver/Mutation/mysql_createUser.js med en enda exporterad func-funktion för mutationen:
Mutationsfunktionen måste göra följande saker, i ordning:
-
Anslut till databasen med hjälp av referenserna i programmets miljövariabler.
-
Infoga användaren i databasen med användarnamnet, som tillhandahålls som input till mutationen.
-
Infoga även eventuella inlägg som är associerade med användaren, tillhandahållna som input till mutationen.
-
Returnera den skapade användardatan.
Så här gör vi det i kod:
Du kan se hela filen som definierar mutationen här.
Skriva frågan
GetUser-frågan har en struktur som liknar den mutation vi just skrev, men den här är ännu enklare. Nu när getUser-funktionen finns i Common namespace behöver vi inte längre någon anpassad SQL i frågan. Så vi skapar filen resolver/Query/mysql_getUser.js enligt följande:
Du kan se hela frågan i den här filen.
Sammanför allt i filen serverless.yml
Låt oss ta ett steg tillbaka. Vi har för närvarande följande:
-
Ett GraphQL API-schema.
-
En handler.js-fil.
-
En fil för vanliga databasfrågor.
-
En fil för varje mutation och fråga.
Det sista steget är att koppla ihop allt detta via filen serverless.yml. Vi skapar en tom serverless.yml i roten av projektet och börjar med att definiera leverantören, regionen och körtiden. Vi tillämpar även LambdaRole IAM-rollen (som vi definierar senare här) på vårt projekt:
Vi definierar sedan miljövariablerna för databasens autentiseringsuppgifter:
Observera att alla variabler refererar till det anpassade avsnittet, som kommer härnäst och innehåller de faktiska värdena för variablerna. Observera att lösenord är ett hemskt lösenord för din databas och bör ändras till något säkrare (kanske p@ssw0rd 😃):
Vad är de där referenserna efter Fn::GettAtt, frågar du? De hänvisar till databasresurser:
Filen resurs/MySqlRDSInstance.yml definierar alla attribut för MySQL-instansen. Du hittar hela innehållet här.
Slutligen, i filen serverless.yml definierar vi två funktioner, graphql och playground. graphql-funktionen kommer att hantera alla API-förfrågningar, och playground endpoint kommer att skapa en instans av GraphQL Playground för oss, vilket är ett utmärkt sätt att testa vårt GraphQL API i en webbläsare:
Nu är MySQL-stödet för vår applikation komplett!
Du kan hitta hela innehållet i filen serverless.yml här.
Lägga till stöd för Aurora och PostgreSQL
Vi har redan skapat all struktur vi behöver för att stödja andra databaser i det här projektet. För att lägga till stöd för Aurora och Postgres behöver vi bara definiera koden för deras mutationer och frågor, vilket vi gör enligt följande:
-
Lägg till en Common queries-fil för Aurora och för Postgres.
-
Lägg till createUser-mutationen för båda databaserna.
-
Lägg till getUser-frågan för båda databaserna.
-
Lägg till konfiguration i filen serverless.yml för alla miljövariabler och resurser som behövs för båda databaserna.
Vid det här laget har vi allt vi behöver för att distribuera vårt GraphQL API, som drivs av MySQL, Aurora och PostgreSQL.
Implementera och testa GraphQL API
Det är enkelt att distribuera vårt GraphQL API.
-
Först kör vi npm install för att sätta våra beroenden på plats.
-
Sedan kör vi npm run deploy, som ställer in alla våra miljövariabler och utför distributionen.
-
Under huven kör detta kommando serverlös driftsättning med rätt miljö.
Det är allt! I utgången av implementeringssteget ser vi URL-slutpunkten för vår distribuerade applikation. Vi kan skicka POST-förfrågningar till vårt GraphQL API med den här webbadressen, och vår lekplats (som vi kommer att spela med om en sekund) är tillgänglig med GET mot samma URL.
Testa API i GraphQL Playground
GraphQL Playground, som är vad du ser när du besöker webbadressen i webbläsaren, är ett utmärkt sätt att testa vårt API.
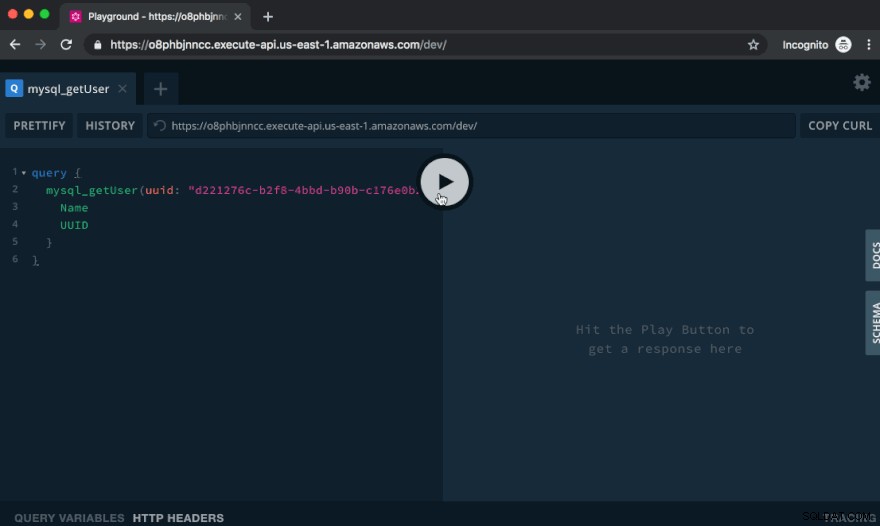
Låt oss skapa en användare genom att köra följande mutation:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
I den här mutationen anropar vi mysql_createUser API, anger texten i den nya användarens inlägg och anger att vi vill få tillbaka användarens namn och UUID som svar.
Klistra in texten ovan i den vänstra sidan av lekplatsen och klicka på knappen Spela. Till höger ser du resultatet av frågan:
Låt oss nu fråga efter den här användaren:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Detta ger oss tillbaka namnet och UUID för användaren vi just skapade. Propert!
Vi kan göra samma sak med de andra backends, PostgreSQL och Aurora. För det behöver vi bara ersätta namnen på mutationen med postgres_createUser eller aurora_createUser, och frågor med postgres_getUser eller aurora_getUser. Prova själv! (Tänk på att användarna inte synkroniseras mellan databaserna, så du kommer bara att kunna fråga efter användare som du har skapat i varje specifik databas.)
Jämföra MySQL-, PostgreSQL- och Aurora-implementeringarna
Till att börja med ser mutationer och frågor exakt likadana ut på Aurora och MySQL, eftersom Aurora är MySQL-kompatibelt. Och det finns bara minimala kodskillnader mellan dessa två och Postgres-implementeringen.
Faktum är att för enkla användningsfall är den största skillnaden mellan våra tre databaser att Aurora endast är tillgänglig som ett kluster. Den minsta tillgängliga Aurora-konfigurationen innehåller fortfarande en skrivskyddad och en skrivreplik, så vi behöver en klustrad konfiguration även för denna grundläggande Aurora-distribution.
Aurora erbjuder snabbare prestanda än MySQL och PostgreSQL, främst på grund av SSD-optimeringarna som Amazon gjort till databasmotorn. När ditt projekt växer kommer du sannolikt att upptäcka att Aurora erbjuder förbättrad databasskalbarhet, enklare underhåll och bättre tillförlitlighet jämfört med standardkonfigurationerna för MySQL och PostgreSQL. Men du kan göra några av dessa förbättringar på MySQL och PostgreSQL också om du justerar dina databaser och lägger till replikering.
För testprojekt och lekplatser rekommenderar vi MySQL eller PostgreSQL. Dessa kan köras på db.t2.micro RDS-instanser, som är en del av AWS free tier. Aurora erbjuder för närvarande inte db.t2.micro-instanser, så du kommer att betala lite mer för att använda Aurora för detta testprojekt.
En sista viktig anmärkning
Kom ihåg att ta bort din serverlösa distribution när du har provat klart GraphQL API så att du inte fortsätter att betala för databasresurser som du inte längre använder.
Du kan ta bort stacken som skapats i det här exemplet genom att köra npm run remove i projektets rot.
Lycka till med att experimentera!
Sammanfattning
I den här artikeln gick vi igenom att skapa ett enkelt GraphQL API, med hjälp av tre olika databaser samtidigt; även om detta inte är något du någonsin skulle göra i verkligheten, tillät det oss att jämföra enkla implementeringar av databaserna Aurora, MySQL och PostgreSQL. Vi såg att implementeringen för alla tre databaserna är ungefär densamma i vårt enkla fall, med undantag för mindre skillnader i syntax och distributionskonfigurationer.
Du kan hitta det fullständiga exempelprojektet som vi har använt i denna GitHub-repo. Det enklaste sättet att experimentera med projektet är att klona repet och distribuera det från din maskin med npm run deploy.
För fler GraphQL API-exempel som använder Serverless, kolla in serverless-graphql-repo.
Om du vill lära dig mer om att köra serverlösa GraphQL-API:er i stor skala kan du njuta av vår artikelserie "Köra en skalbar och pålitlig GraphQL-slutpunkt med serverlös"
Kanske är GraphQL helt enkelt inte ditt jam, och du vill hellre distribuera ett REST API? Vi har dig täckt:kolla in det här blogginlägget för några exempel.
Frågor? Kommentera det här inlägget eller skapa en diskussion i vårt forum.
Ursprungligen publicerad på https://www.serverless.com.