Till skillnad från andra databashanteringssystem som har sin egen inbyggda schemaläggare (som Oracle, MSSQL eller MySQL), har PostgreSQL fortfarande inte den här typen av funktion.
För att tillhandahålla schemaläggningsfunktionalitet i PostgreSQL måste du använda ett externt verktyg som...
- Linux crontab
- Agent pgAgent
- Tillägg pg_cron
I den här bloggen kommer vi att utforska dessa verktyg och belysa hur man använder dem och deras huvudfunktioner.
Linux crontab
Det är den äldsta, men ett effektivt och användbart sätt att utföra schemaläggningsuppgifter. Detta program är baserat på en demon (cron) som tillåter att uppgifter automatiskt körs i bakgrunden med jämna mellanrum och regelbundet verifierar konfigurationsfilerna (kallade crontab-filer) på vilka skriptet/kommandot som ska köras och dess schemaläggning definieras.
Varje användare kan ha sin egen crontab-fil och för de senaste Ubuntu-versionerna finns i:
/var/spool/cron/crontabs (for other linux distributions the location could be different):
example@sqldat.com:/var/spool/cron/crontabs# ls -ltr
total 12
-rw------- 1 dbmaster crontab 1128 Jan 12 12:18 dbmaster
-rw------- 1 slonik crontab 1126 Jan 12 12:22 slonik
-rw------- 1 nines crontab 1125 Jan 12 12:23 ninesSyntaxen för konfigurationsfilen är följande:
mm hh dd mm day <<command or script to execute>>
mm: Minute(0-59)
hh: Hour(0-23)
dd: Day(1-31)
mm: Month(1-12)
day: Day of the week(0-7 [7 or 0 == Sunday])Några operatorer skulle kunna användas med den här syntaxen för att effektivisera schemaläggningsdefinitionen och dessa symboler tillåter att ange flera värden i ett fält:
Asterisk (*) - det betyder alla möjliga värden för ett fält
Kommat (,) - används för att definiera en lista med värden
Streck (-) - används för att definiera ett värdeintervall
Separator (/) - anger ett stegvärde
Skriptet all_db_backup.sh kommer att köras enligt varje schemaläggningsuttryck:
| 0 6 * * * /home/backup/all_db_backup.sh | Klockan 6 varje dag |
| 20 22 * * Mån, Tis, Ons, Tors, Fre /home/backup/all_db_backup.sh | Kl. 22:20, varje vardag |
| 0 23 * * 1-5 /home/backup/all_db_backup.sh | Kl. 23.00 under veckan |
| 0 0/5 14 * * /home/backup/all_db_backup.sh | Var femte timme med start kl. 14.00. och slutar 14:55 varje dag |
Om crontab-filen inte finns för en användare kan den skapas med följande kommando:
example@sqldat.com:~$ crontab -eeller presenterade det med parametern -l:
example@sqldat.com:~$ crontab -lOm det behövs för att ta bort den här filen är lämplig parameter -r:
example@sqldat.com:~$ crontab -rCron-demonens status visas genom att följande kommando körs:
Agent pgAgent
pgAgent är en jobbschemaläggningsagent tillgänglig för PostgreSQL som tillåter exekvering av lagrade procedurer, SQL-satser och skalskript. Dess konfiguration lagras i postgres-databasen i klustret.
Syftet är att denna agent ska köras som en demon på Linux-system och regelbundet gör en anslutning till databasen för att kontrollera om det finns några jobb att köra.
Denna schemaläggning hanteras enkelt av PgAdmin 4, men den är inte installerad som standard när pgAdmin väl har installerats, det är nödvändigt att ladda ner och installera det på egen hand.
Härefter beskrivs alla nödvändiga steg för att pgAgent ska fungera korrekt:
Steg ett
Installation av pgAdmin 4
$ sudo apt install pgadmin4 pgadmin4-apacheSteg två
Skapande av plpgsql procedurspråk om inte definierat
CREATE TRUSTED PROCEDURAL LANGUAGE ‘plpgsql’
HANDLER plpgsql_call_handler
HANDLER plpgsql_validator;Steg tre
Installation av pgAgent
$ sudo apt-get install pgagentSteg fyra
Skapande av tillägget pgagent
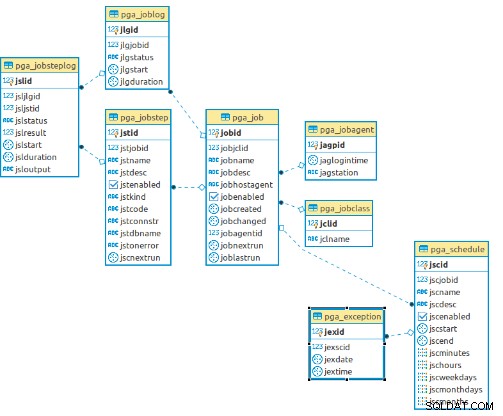
CREATE EXTENSION pageant Detta tillägg kommer att skapa alla tabeller och funktioner för pgAgent-operationen och härefter visas datamodellen som används av detta tillägg:
Nu har pgAdmin-gränssnittet redan alternativet "pgAgent Jobs" för att hantera pgAgent:

För att definiera ett nytt jobb är det bara nödvändigt att välja "Skapa" genom att använda den högra knappen på "pgAgent Jobs", så infogar den en beteckning för det här jobbet och definierar stegen för att utföra det:
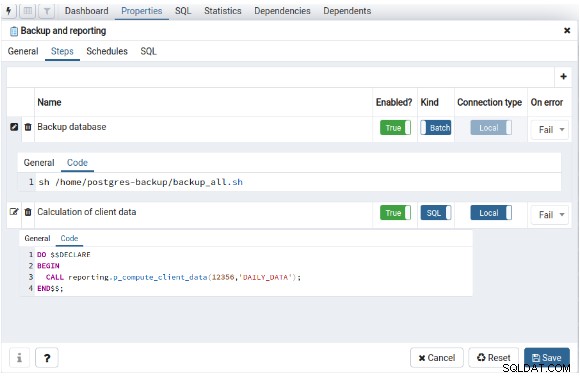
I fliken "Schedules" måste schemaläggningen för detta nya jobb definieras :
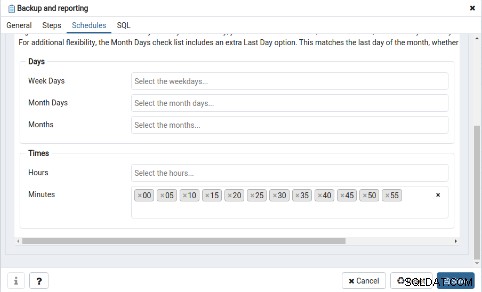
Äntligen, för att agenten ska köras i bakgrunden är det nödvändigt att starta följande process manuellt:
/usr/bin/pgagent host=localhost dbname=postgres user=postgres port=5432 -l 1Ändå är det bästa alternativet för den här agenten att skapa en demon med föregående kommando.
Tillägg pg_cron
pg_cron är en cron-baserad jobbschemaläggare för PostgreSQL som körs inuti databasen som en förlängning (liknande DBMS_SCHEDULER i Oracle) och tillåter exekvering av databasuppgifter direkt från databasen, på grund av en bakgrundsarbetare.
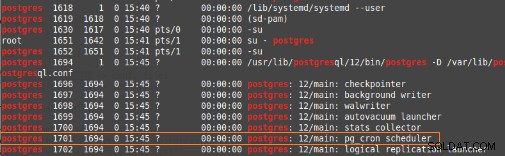
De uppgifter som ska utföras kan vara någon av följande:
- lagrade procedurer
- SQL-satser
- PostgreSQL-kommandon (som VACUUM, eller VACUUM ANALYZE)
pg_cron kan köra flera jobb parallellt, men bara en instans av ett program kan köras åt gången.
Om en andra körning ska startas innan den första är klar, ställs den i kö och kommer att startas så snart den första körningen är klar.
Det här tillägget definierades för version 9.5 eller högre av PostgreSQL.
Installation av pg_cron
Installationen av detta tillägg kräver endast följande kommando:
example@sqldat.com:~$ sudo apt-get -y install postgresql-10-cronUppdatering av konfigurationsfiler
För att starta bakgrundsarbetaren pg_cron när PostgreSQL-servern startar, är det nödvändigt att ställa in pg_cron till parametern shared_preload_libraries i postgresql.conf:
shared_preload_libraries = ‘pg_cron’Det är också nödvändigt att i den här filen definiera databasen som tillägget pg_cron kommer att skapas på, genom att lägga till följande parameter:
cron.database_name= ‘postgres’Å andra sidan, i filen pg_hba.conf som hanterar autentiseringen, är det nödvändigt att definiera postgres-inloggningen som förtroende för IPV4-anslutningarna, eftersom pg_cron kräver att en sådan användare kan ansluta till databasen utan att ange något lösenord, så följande rad måste läggas till i den här filen:
host postgres postgres 192.168.100.53/32 trustFörtroendemetoden för autentisering tillåter vem som helst att ansluta till databasen/databaserna som specificeras i filen pg_hba.conf, i detta fall postgres-databasen. Det är en metod som ofta används för att tillåta anslutning med Unix-domänsocket på en enskild användares dator för att komma åt databasen och bör endast användas när det finns ett tillräckligt skydd på operativsystemnivå på anslutningar till servern.
Båda ändringarna kräver omstart av PostgreSQL-tjänsten:
example@sqldat.com:~$ sudo system restart postgresql.serviceDet är viktigt att ta hänsyn till att pg_cron inte kör några jobb så länge servern är i hot standby-läge, utan den startar automatiskt när servern marknadsförs.
Skapande av tillägget pg_cron
Detta tillägg kommer att skapa metadata och procedurerna för att hantera dem, så följande kommando bör köras på psql:
postgres=#CREATE EXTENSION pg_cron;
CREATE EXTENSION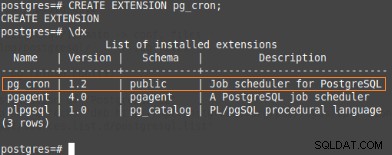
Nu är de nödvändiga objekten för att schemalägga jobb redan definierade i cron-schemat :
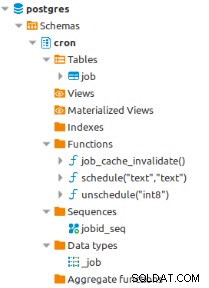
Detta tillägg är väldigt enkelt, bara jobbtabellen räcker för att hantera alla denna funktion:
Definition av nya jobb
Schemaläggningssyntaxen för att definiera jobb på pg_cron är densamma som används i cron-verktyget, och definitionen av nya jobb är mycket enkel, det är bara nödvändigt att anropa funktionen cron.schedule:
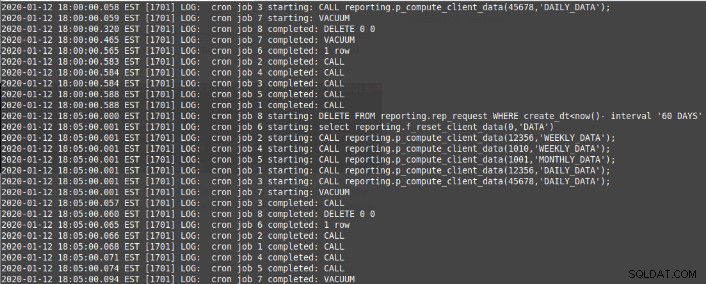
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(12356,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(998934,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(45678,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1010,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1001,''MONTHLY_DATA'');')
select cron.schedule('*/5 * * * *','select reporting.f_reset_client_data(0,''DATA'')')
select cron.schedule('*/5 * * * *','VACUUM')
select cron.schedule('*/5 * * * *','$$DELETE FROM reporting.rep_request WHERE create_dt<now()- interval '60 DAYS'$$)Jobbinställningarna lagras i jobbtabellen:
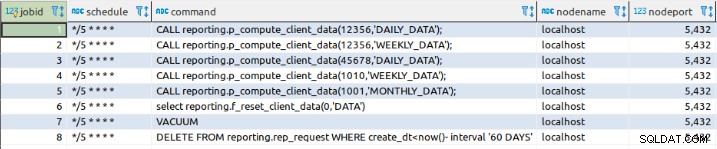
Ett annat sätt att definiera ett jobb är att infoga data direkt på cron .jobbtabell:
INSERT INTO cron.job (schedule, command, nodename, nodeport, database, username)
VALUES ('0 11 * * *','call loader.load_data();','postgresql-pgcron',5442,'staging', 'loader');och använd anpassade värden för nodnamn och nodport för att ansluta till en annan dator (liksom andra databaser).
Avaktivering av ett jobb
Å andra sidan, för att avaktivera ett jobb är det bara nödvändigt att utföra följande funktion:
select cron.schedule(8)Jobbloggning
Loggningen av dessa jobb finns i PostgreSQL-loggfilen /var/log/postgresql/postgresql-12-main.log: