Vakuum är en av de viktigaste funktionerna för att återvinna raderade tupler i tabeller och index. Utan vakuum skulle tabeller och index fortsätta växa i storlek utan gränser. Det här blogginlägget beskriver alternativet PARALLEL för VACUUM-kommandot, som nyligen introducerats till PostgreSQL13.
Vakuumbearbetningsfaser
Innan vi diskuterar det nya alternativet på djupet, låt oss gå igenom detaljerna om hur vakuum fungerar.
Vakuum (utan FULL-alternativ) består av fem faser. Till exempel, för en tabell med två index, fungerar det enligt följande:
- Högskanningsfas
- Skanna bordet från toppen och samla soptuplar i minnet.
- Indexvakuumfas
- Damsug båda indexen ett i taget.
- Högvakuumfas
- Sug upp högen (bord).
- Indexrensningsfas
- Rensa båda indexen ett i taget.
- Högavkortningsfas
- Trunkera tomma sidor i slutet av tabellen.
I heapscan-fasen kan vakuum använda synlighetskartan för att hoppa över bearbetningen av sidor som är kända för att inte ha något skräp, medan både indexvakuumfasen och indexrensningsfasen, beroende på indexåtkomstmetoder, en hel indexskanning krävs.
Till exempel kräver btree-index, den mest populära indextypen, en hel indexskanning för att ta bort skräptuplar och göra indexrensning. Eftersom vakuum alltid utförs av en enda process, bearbetas indexen en efter en. Den längre utförandetiden av vakuum på särskilt ett stort bord irriterar ofta användarna.
PARALLELLT alternativ
För att lösa detta problem föreslog jag en korrigeringsfil för att parallellisera vakuum 2016. Efter en lång granskningsprocess och många reformer har alternativet PARALLEL introducerats till PostgreSQL 13. Med detta alternativ kan vakuum utföra indexvakuumfasen och indexrensningsfasen med parallellarbetare. Parallelldammsugare startar innan de går in i antingen indexvakuumfas eller indexrensningsfas och avslutar i slutet av fasen. En enskild arbetare tilldelas ett index. Parallellvakuum är alltid inaktiverat i autovakuum.
Alternativet PARALLEL utan ett heltalsargument kommer automatiskt att beräkna parallellgraden baserat på antalet index i tabellen.
VACUUM (PARALLEL) tbl;
Eftersom ledarprocessen alltid bearbetar ett index, kommer det maximala antalet parallella arbetare att vara (antalet index i tabellen – 1), vilket ytterligare är begränsat till max_parallel_maintenance_workers. Målindexet måste vara större än eller lika med min_parallel_index_scan_size.
Alternativet PARALLEL låter oss ange parallellgraden genom att skicka ett heltalsvärde som inte är noll. Följande exempel använder tre arbetare, för totalt fyra parallella processer.
VACUUM (PARALLEL 3) tbl;
Alternativet PARALLELL är aktiverat som standard; för att inaktivera parallellvakuum, ställ in max_parallel_maintenance_workers till 0 eller ange PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
När vi tittar på VACUUM VERBOSE-utgången kan vi se att en arbetare bearbetar indexet.
Informationen som skrivs ut som "av parallellarbetare" rapporteras av arbetaren.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Indexåtkomstmetoder kontra graden av parallellitet
Vakuum utför inte alltid nödvändigtvis indexvakuumfasen och indexrensningsfasen parallellt. Om indexstorleken är liten, eller om det är känt att processen kan slutföras snabbt, orsakar kostnaden för att starta och hantera parallella arbetare för parallellisering istället overhead. Beroende på indexåtkomstmetoderna och dess storlek är det bättre att inte utföra dessa faser med en parallell vakuumarbetarprocess.
Till exempel, vid dammsugning av ett tillräckligt stort btree-index, kan indexvakuumfasen för indexet utföras av en parallellvakuumarbetare eftersom den alltid kräver en hel indexavsökning, medan indexrensningsfasen utförs av en parallellvakuumarbetare om indexet vakuum utförs inte (det finns t.ex. inget skräp på bordet). Detta beror på att vad btree-index kräver i indexrensningsfasen är att samla in indexstatistiken, som också samlas in under indexvakuumfasen. Å andra sidan kräver hashindex alltid inte en skanning av indexet i indexrensningsfasen.
För att stödja olika typer av indexvakuumstrategier kan utvecklare av indexåtkomstmetoder specificera dessa beteenden genom att sätta flaggor till amparallelvacuumoptions fältet i IndexAmRoutine strukturera. De tillgängliga flaggorna är följande:
- VACUUM_OPTION_NO_PARALLEL (standard)
- parallellvakuum är inaktiverat i båda faserna.
- VACUUM_OPTION_PARALLEL_BULKDEL
- indexvakuumfasen kan utföras parallellt.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- indexrensningsfasen kan utföras parallellt om indexvakuumfasen inte har utförts ännu.
- VACUUM_OPTION_PARALLEL_CLEANUP
- indexrensningsfasen kan utföras parallellt även om indexvakuumfasen redan har bearbetat indexet.
Tabellen nedan visar hur index AMs inbyggda PostgreSQL stöder parallellt vakuum.
| nbtree | hash | gin | sammanfattning | spgist | brin | blom | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Se 'src/include/command/vacuum.h' för mer information.
Prestandeverifiering
Jag har utvärderat prestandan för parallellvakuum på min bärbara dator (Core i7 2,6 GHz, 16 GB RAM, 512 GB SSD). Bordsstorleken är 6GB och har åtta 3GB-index. Den totala relationen är 30 GB, vilket inte passar maskinens RAM. För varje utvärdering gjorde jag flera procent av bordet smutsigt jämnt efter dammsugning, utförde sedan vakuum medan jag ändrade parallellgraden. Grafen nedan visar vakuumkörningstiden.
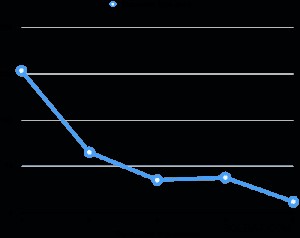
I alla utvärderingar stod exekveringstiden för indexvakuumet för mer än 95 % av den totala exekveringstiden. Därför bidrog parallellisering av indexvakuumfasen till att reducera vakuumexekveringstiden mycket.
Tack
Särskilt tack till Amit Kapila för hängiven granskning, ge råd och förmedling av den här funktionen till PostgreSQL 13. Jag uppskattar alla utvecklare som var involverade i den här funktionen för granskning, testning och diskussion.