Det finns inte ett perfekt system, hårdvara eller topologi för att undvika alla möjliga problem som kan hända i en produktionsmiljö. För att övervinna dessa utmaningar krävs en effektiv DRP (Disaster Recovery Plan), konfigurerad enligt din applikation, infrastruktur och affärskrav. Nyckeln till framgång i dessa typer av situationer är alltid hur snabbt vi kan åtgärda eller återhämta oss från problemet.
I den här bloggen tar vi en titt på de vanligaste PostgreSQL-felscenarierna och visar dig hur du kan lösa eller hantera problemen. Vi kommer också att titta på hur ClusterControl kan hjälpa oss att komma tillbaka online
Den gemensamma PostgreSQL-topologin
För att förstå vanliga felscenarier måste du först börja med en vanlig PostgreSQL-topologi. Detta kan vara vilken applikation som helst som är ansluten till en PostgreSQL Primary Node som har en replik ansluten till sig.
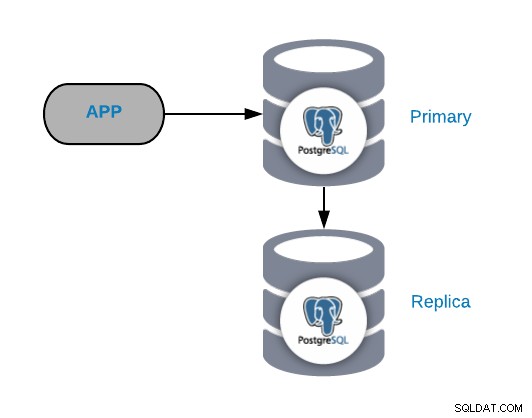
Du kan alltid förbättra eller utöka denna topologi genom att lägga till fler noder eller lastbalanserare , men det här är den grundläggande topologin vi ska börja arbeta med.
Primärt PostgreSQL-nodfel
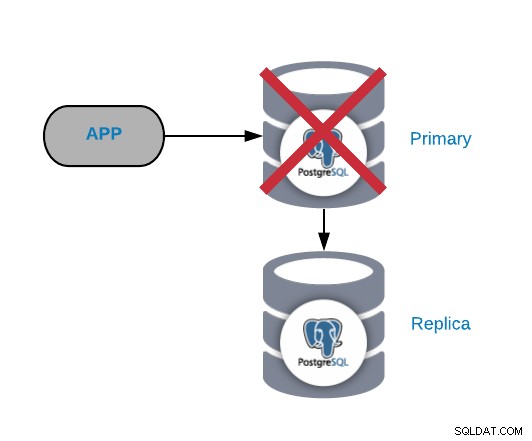
Detta är ett av de mest kritiska felen eftersom vi bör åtgärda det ASAP om vi vill hålla våra system online. För denna typ av fel är det viktigt att ha någon form av automatisk failover-mekanism på plats. Efter misslyckandet kan du undersöka orsaken till problemen. Efter failover-processen säkerställer vi att den misslyckade primärnoden inte fortfarande tror att den är den primära noden. Detta för att undvika datainkonsekvens när du skriver till den.
De vanligaste orsakerna till den här typen av problem är ett operativsystemsfel, maskinvarufel eller ett diskfel. I vilket fall som helst bör vi kontrollera databasen och operativsystemloggarna för att hitta orsaken.
Den snabbaste lösningen för detta problem är att utföra en failover-uppgift för att minska driftstopp. För att främja en replik kan vi använda kommandot pg_ctl promote på slavdatabasnoden, och sedan måste vi skicka trafiken från applikation till den nya primära noden. För denna sista uppgift kan vi implementera en lastbalanserare mellan vår applikation och databasnoderna, för att undvika förändringar från applikationssidan i händelse av fel. Vi kan också konfigurera lastbalanseraren för att upptäcka nodfelet och istället för att skicka trafik till honom, skicka trafiken till den nya primära noden.
Efter failover-processen och se till att systemet fungerar igen, kan vi undersöka problemet, och vi rekommenderar att alltid ha minst en slavnod i drift, så i händelse av ett nytt primärt fel, vi kan utföra failover-uppgiften igen.
PostgreSQL Replica Node Failure
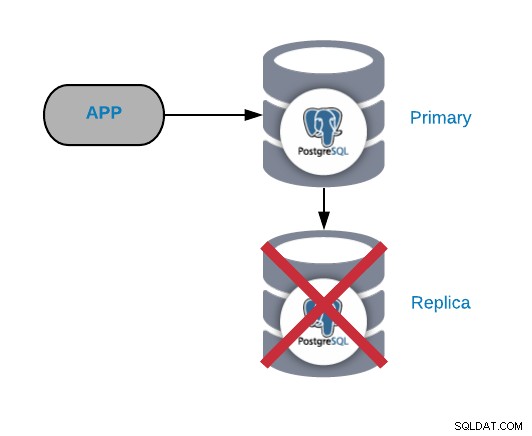
Detta är normalt inte ett kritiskt problem (så länge du har mer än en replik och använder den inte för att skicka den lästa produktionstrafiken). Om du upplever problem på den primära noden och inte har din replika uppdaterad, har du ett riktigt kritiskt problem. Om du använder vår replika för rapporterings- eller big data-ändamål, vill du förmodligen fixa det snabbt ändå.
De vanligaste orsakerna till den här typen av problem är desamma som vi såg för den primära noden, ett operativsystemfel, maskinvarufel eller diskfel. Du bör kontrollera databasen och operativsystemloggarna för att hitta orsaken.
Det rekommenderas inte att låta systemet fungera utan någon replik eftersom du inte har ett snabbt sätt att komma tillbaka online i händelse av fel. Om du bara har en slav bör du lösa problemet ASAP; det snabbaste sättet är genom att skapa en ny replik från grunden. För detta måste du ta en konsekvent säkerhetskopia och återställa den till slavnoden och sedan konfigurera replikeringen mellan denna slavnod och den primära noden.
Om du vill veta orsaken till felet bör du använda en annan server för att skapa den nya repliken och sedan titta på den gamla för att upptäcka den. När du är klar med den här uppgiften kan du också konfigurera om den gamla repliken och fortsätta att fungera som ett framtida failover-alternativ.
Om du använder repliken för rapportering eller för big data-ändamål måste du ändra IP-adressen för att ansluta till den nya. Som i det föregående fallet är ett sätt att undvika denna förändring genom att använda en lastbalanserare som känner till statusen för varje server, så att du kan lägga till/ta bort repliker som du vill.
PostgreSQL-replikeringsfel
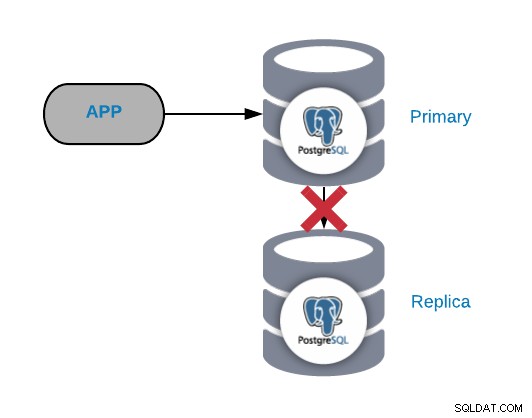
I allmänhet genereras den här typen av problem på grund av ett nätverk eller en konfiguration problem. Det är relaterat till en WAL-förlust (Write-Ahead Logging) i den primära noden och hur PostgreSQL hanterar replikeringen.
Om du har viktig trafik, kör du kontrollpunkter för ofta, eller så lagrar du WALS i bara några minuter; om du har ett nätverksproblem har du lite tid att lösa det. Dina WALs skulle raderas innan du kan skicka och tillämpa den på repliken.
Om WAL som repliken behöver för att fortsätta fungera togs bort måste du bygga om den, så för att undvika denna uppgift bör vi kontrollera vår databaskonfiguration för att öka wal_keep_segments (mängden WALS att behålla i pg_xlog-katalogen) eller parametrarna max_wal_senders (maximalt antal WAL-avsändarprocesser som körs samtidigt).
Ett annat rekommenderat alternativ är att konfigurera archive_mode på och skicka WAL-filerna till en annan sökväg med parametern archive_command. På detta sätt, om PostgreSQL når gränsen och tar bort WAL-filen, kommer vi att ha den i en annan väg ändå.
PostgreSQL-datakorruption / datainkonsekvens / oavsiktlig radering

Detta är en mardröm för alla DBA och förmodligen den mest komplexa frågan som är fixat, beroende på hur utbrett problemet är.
När dina data påverkas av några av dessa problem är det vanligaste sättet att åtgärda det (och förmodligen det enda) genom att återställa en säkerhetskopia. Det är därför säkerhetskopior är den grundläggande formen av alla katastrofåterställningsplaner och det rekommenderas att du har minst tre säkerhetskopior lagrade på olika fysiska platser. Bästa praxis säger att säkerhetskopieringsfiler ska ha en lagrad lokalt på databasservern (för snabbare återställning), en annan på en centraliserad backupserver och den sista i molnet.
Vi kan också skapa en blandning av fullständiga/inkrementella/differentiella PITR-kompatibla säkerhetskopior för att minska vårt mål för återställningspunkt.
Hantera PostgreSQL-fel med ClusterControl
Nu när vi har tittat på dessa vanliga PostgreSQL-felscenarier låt oss titta på vad som skulle hända om vi hanterade dina PostgreSQL-databaser från ett centraliserat databashanteringssystem. En som är bra när det gäller att nå ett snabbt och enkelt sätt att åtgärda problemet, ASAP, vid misslyckande.
ClusterControl tillhandahåller automatisering för de flesta av PostgreSQL-uppgifterna som beskrivs ovan; allt på ett centraliserat och användarvänligt sätt. Med detta system kommer du enkelt att kunna konfigurera saker som manuellt skulle ta tid och ansträngning. Vi kommer nu att granska några av dess huvudfunktioner relaterade till PostgreSQL-felscenarier.
Distribuera/importera ett PostgreSQL-kluster
När vi väl har kommit in i ClusterControl-gränssnittet är det första vi ska göra att distribuera ett nytt kluster eller importera ett befintligt. För att utföra en distribution, välj helt enkelt alternativet Distribuera databaskluster och följ instruktionerna som visas.
Skala ditt PostgreSQL-kluster
Om du går till Cluster Actions och väljer Lägg till replikeringsslav kan du antingen skapa en ny replika från början eller lägga till en befintlig PostgreSQL-databas som en replik. På så sätt kan du ha din nya kopia igång på några minuter och vi kan lägga till så många kopior som vi vill; sprida lästrafik mellan dem med en lastbalanserare (som vi också kan implementera med ClusterControl).
PostgreSQL Automatic Failover
ClusterControl hanterar failover på din replikeringsinställning. Den upptäcker masterfel och marknadsför en slav med de senaste uppgifterna som den nya mastern. Den misslyckas också automatiskt med resten av slavarna för att replikera från den nya mastern. När det gäller klientanslutningar använder den två verktyg för uppgiften:HAProxy och Keepalived.
HAProxy är en lastbalanserare som distribuerar trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för uppgiften. Om någon av destinationerna slutar svara markeras den som offline och trafiken skickas till en av de tillgängliga destinationerna. Detta förhindrar att trafik skickas till en otillgänglig destination och förlust av denna information genom att dirigera den till en giltig destination.
Keelived låter dig konfigurera en virtuell IP inom en aktiv/passiv grupp av servrar. Denna virtuella IP tilldelas en aktiv "Main"-server. Om den här servern misslyckas migreras IP:n automatiskt till den "sekundära" servern som visade sig vara passiv, vilket gör att den kan fortsätta arbeta med samma IP på ett transparent sätt för våra system.
Lägga till en PostgreSQL Load Balancer
Om du går till Cluster Actions och väljer Add Load Balancer (eller från klustervyn - gå till Hantera -> Load Balancer) kan du lägga till lastbalanserare till vår databastopologi.
Konfigurationen som behövs för att skapa din nya lastbalanserare är ganska enkel. Du behöver bara lägga till IP/värdnamn, port, policy och de noder vi ska använda. Du kan lägga till två lastbalanserare med Keepalved mellan dem, vilket gör att vi kan ha en automatisk failover av vår lastbalanserare vid fel. Keepalved använder en virtuell IP-adress och migrerar den från en belastningsbalanserare till en annan i händelse av fel, så att vår installation kan fortsätta att fungera normalt.
PostgreSQL-säkerhetskopior
Vi har redan diskuterat vikten av att ha säkerhetskopior. ClusterControl tillhandahåller funktionen att antingen generera en omedelbar säkerhetskopiering eller schemalägga en.
Du kan välja mellan tre olika backupmetoder, pgdump, pg_basebackup eller pgBackRest. Du kan också ange var säkerhetskopiorna ska lagras (på databasservern, på ClusterControl-servern eller i molnet), komprimeringsnivån, kryptering som krävs och lagringsperioden.
PostgreSQL-övervakning och varning
Innan du kan vidta åtgärder måste du veta vad som händer, så du måste övervaka ditt databaskluster. ClusterControl låter dig övervaka våra servrar i realtid. Det finns grafer med grundläggande data som CPU, nätverk, disk, RAM, IOPS, såväl som databasspecifika mätvärden som samlats in från PostgreSQL-instanserna. Databasfrågor kan också ses från Query Monitor.
På samma sätt som du aktiverar övervakning från ClusterControl kan du också ställa in varningar som informerar dig om händelser i ditt kluster. Dessa varningar är konfigurerbara och kan anpassas efter behov.
Slutsats
Alla kommer så småningom att behöva hantera PostgreSQL-problem och misslyckanden. Och eftersom du inte kan undvika problemet måste du kunna fixa det ASAP och hålla systemet igång. Vi såg också hur användning av ClusterControl kan hjälpa till med dessa problem; allt från en enda och användarvänlig plattform.
Det här är vad vi trodde var några av de vanligaste felscenarierna för PostgreSQL. Vi vill gärna höra om dina egna erfarenheter och hur du fixade det.