Introduktion
Nuförtiden är hög tillgänglighet ett krav för många system, oavsett vilken teknik du använder. Detta är särskilt viktigt för databaser, eftersom de lagrar data som kritiska applikationer och system förlitar sig på. Den vanligaste strategin för att uppnå hög tillgänglighet är replikering. Det finns olika sätt att replikera data över flera servrar och failover-trafik när, till exempel, en primär server slutar svara.
Hög tillgänglighetsarkitektur för PostgreSQL
Det finns flera arkitekturer för att implementera hög tillgänglighet i PostgreSQL, men de grundläggande är Primär-Standby- och Primär-Primär-arkitekturer.
Primär-standby-arkitekturer
Primär-Standby kan vara den mest grundläggande HA-arkitekturen du kan ställa in och, ofta, den enklaste att implementera och underhålla. Den är baserad på en primär databas med en eller flera standby-servrar. Dessa Standby-databaser förblir synkroniserade (eller nästan synkroniserade) med den primära noden, beroende på om replikeringen är synkron eller asynkron. Om den primära servern misslyckas, innehåller Standby-servern nästan all primär serverns data och kan snabbt omvandlas till den nya primära databasservern.
Du kan implementera två typer av standby-databaser, baserat på arten av replikeringen:
- Logiska väntelägen – Replikeringen mellan primär och standby görs via SQL-satser.
- Fysiska beredskapslägen – Replikeringen mellan primär och beredskap görs via de interna datastrukturändringarna.
I fallet med PostgreSQL används en ström av WAL-poster (Write-ahead Log) för att hålla Standby-databaserna synkroniserade. Detta kan vara synkront eller asynkront, och hela databasservern replikeras.
Från och med version 10 inkluderar PostgreSQL ett inbyggt alternativ för att ställa in logisk replikering, som konstruerar en ström av logiska datamodifieringar från informationen i loggen för skrivning. Denna replikeringsmetod gör att dataändringarna från enskilda tabeller kan replikeras utan att behöva utse en primär server. Det låter också data flöda i flera riktningar.
Tyvärr räcker inte en primär standby-inställning för att effektivt säkerställa hög tillgänglighet, eftersom du också måste hantera fel. För att hantera fel måste du kunna upptäcka dem. När du vet att det finns ett fel, till exempel fel på den primära noden eller att noden inte svarar, kan du välja en standbynod för att ersätta den misslyckade noden med minsta möjliga fördröjning. Denna process måste vara så effektiv som möjligt för att återställa full funktionalitet till applikationerna. PostgreSQL i sig inkluderar inte en automatisk failover-mekanism, så detta kommer att kräva några anpassade skript eller tredjepartsverktyg för denna automatisering.
Efter en failover måste din applikation meddelas om detta för att börja använda den nya primära. Du måste också utvärdera tillståndet för din arkitektur efter failover eftersom du kan hamna i en situation där bara den nya primära körs (t.ex. du hade en primärnod och bara en standby före problemet). I så fall måste du lägga till en standby-nod för att återskapa den primära standby-inställning som du ursprungligen hade för hög tillgänglighet.
Primär-Primär arkitektur
Primär-Primär-arkitektur ger ett sätt att minimera effekten av ett fel på en av noderna, eftersom de andra noderna kan ta hand om all trafik, vilket endast kan påverka prestandan något men aldrig förlora funktionalitet. Primär-Primär arkitektur används ofta med det dubbla syftet att skapa en miljö med hög tillgänglighet och skala horisontellt (jämfört med konceptet med vertikal skalbarhet där du lägger till fler resurser till en server).
PostgreSQL stöder ännu inte den här arkitekturen "native", så du måste hänvisa till tredjepartsverktyg och implementeringar. När du väljer en lösning måste du tänka på att det finns många projekt/verktyg, men vissa av dem stöds inte längre, medan andra är nya och kanske inte är stridstestade i produktionen.
Lastbalansering
Lastbalanserare är verktyg som kan användas för att hantera trafiken från din applikation för att få ut det mesta av din databasarkitektur.
De här verktygen är inte bara användbara för att balansera belastningen på dina databaser, utan de hjälper också applikationer att omdirigeras till tillgängliga/friska noder och till och med ange portar med olika roller.
HAProxy är en lastbalanserare som distribuerar trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för denna uppgift. Om någon av destinationerna slutar svara markeras de som offline och trafiken skickas till resten av de tillgängliga destinationerna.
Keelived är en tjänst som låter dig konfigurera en virtuell IP-adress inom en aktiv/passiv grupp av servrar. Denna virtuella IP-adress tilldelas en aktiv server. Om denna server misslyckas migreras IP-adressen automatiskt till den "sekundära" passiva servern, vilket gör att den kan fortsätta arbeta med samma IP-adress på ett transparent sätt för systemen.
Låt oss se nu hur man implementerar ett Primary-Standby PostgreSQL-kluster med belastningsbalansservrar och keepalive konfigurerade mellan dem. Vi kommer att visa detta med ClusterControls lättanvända gränssnitt.
För detta exempel kommer vi att skapa:
- 3 PostgreSQL-servrar (en primär och två väntelägen).
- 2 HAProxy Load Balancers.
- Behålls konfigurerad mellan belastningsutjämningsservrarna.
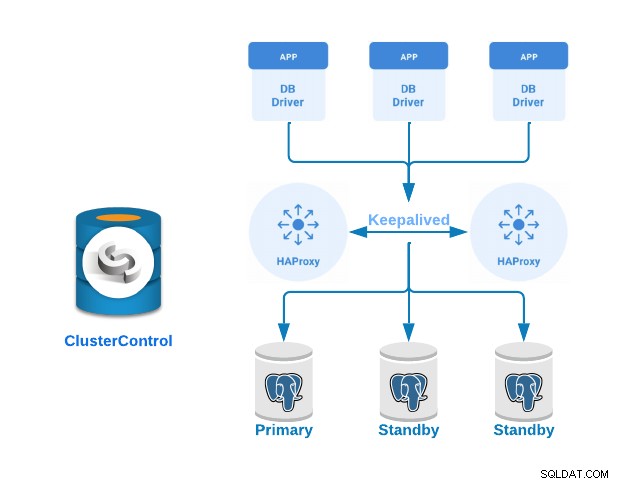
Databasdistribution
För att distribuera en databas med ClusterControl, välj helt enkelt alternativet "Deploy" och följ instruktionerna som visas.
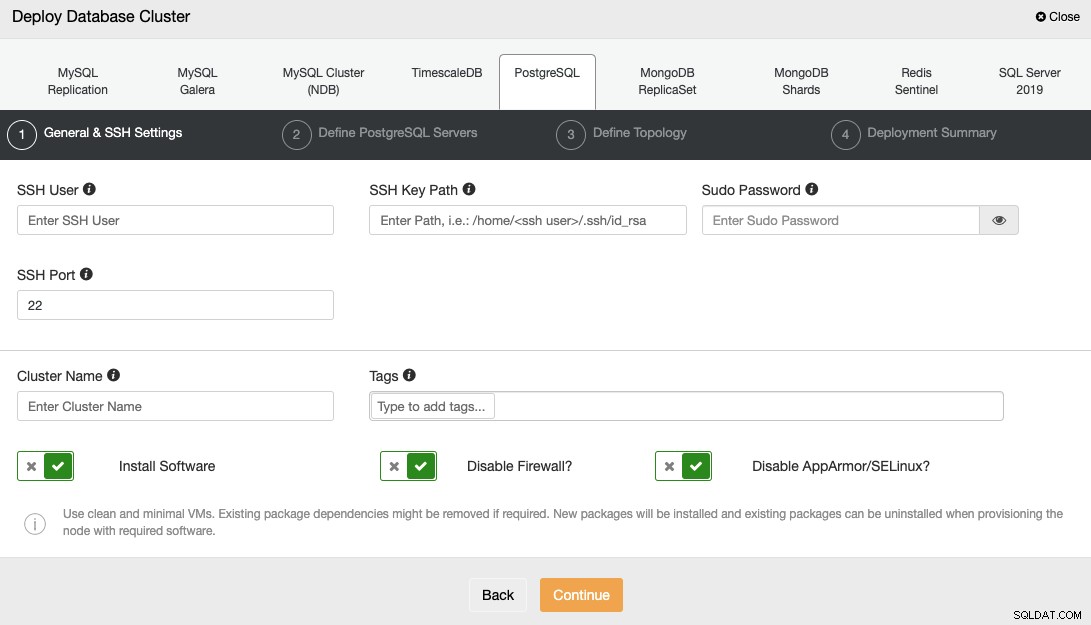
När du väljer PostgreSQL måste du ange användaren, nyckeln eller lösenordet och Port för att ansluta med SSH till dina servrar. Du behöver också namnet på ditt nya kluster och välj om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
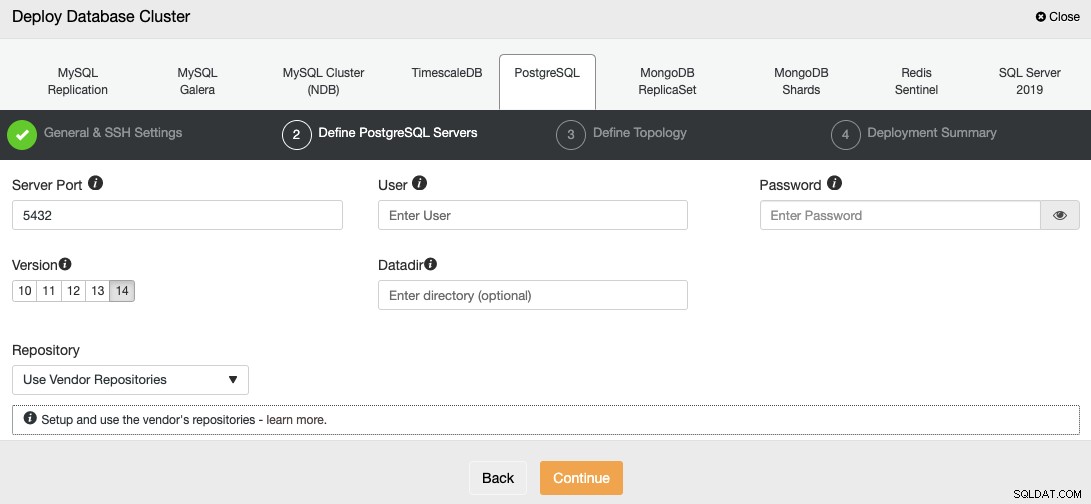
När du har ställt in SSH-åtkomstinformationen måste du definiera databasanvändaren, version och datadir (valfritt). Du kan också ange vilket förråd som ska användas; det officiella leverantörsförrådet kommer att användas som standard.
I nästa steg måste du lägga till dina servrar i klustret du ska skapa.
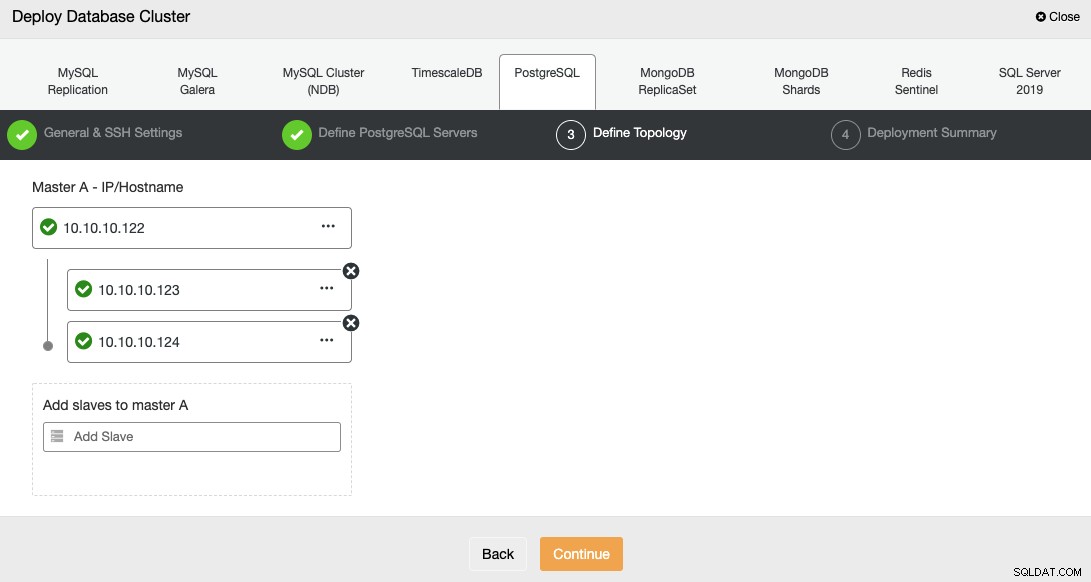
När du lägger till dina servrar kan du ange IP eller värdnamn.
I det sista steget kan du välja om din replikering ska vara Synkron eller Asynkron.
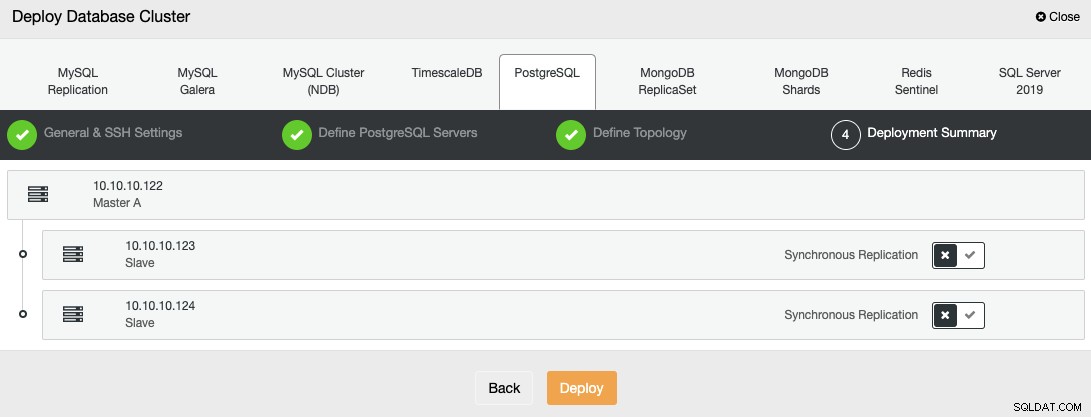
Du kan övervaka statusen för skapandet av ditt nya kluster från ClusterControl aktivitetsövervakare.
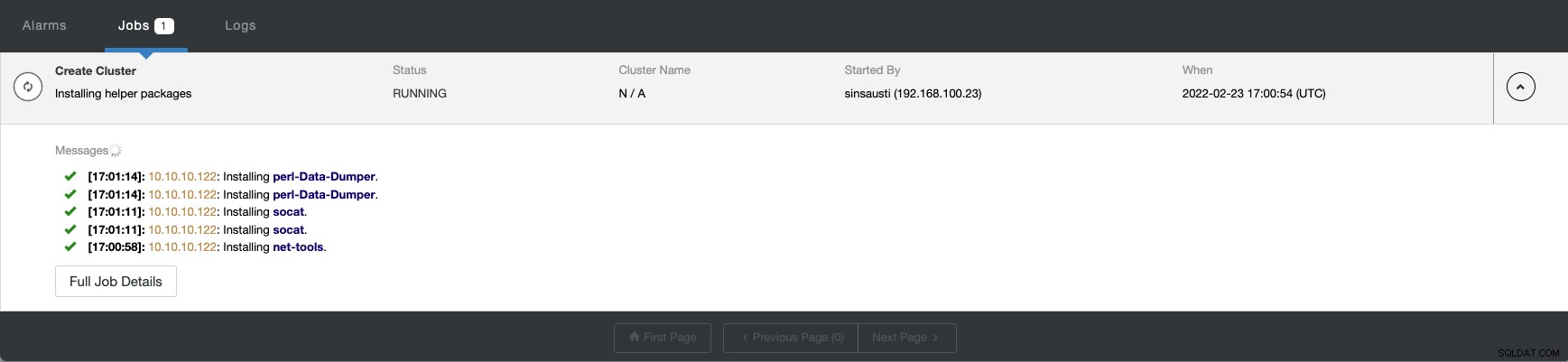
När uppgiften är klar kan du se ditt kluster i huvud ClusterControl skärmen.
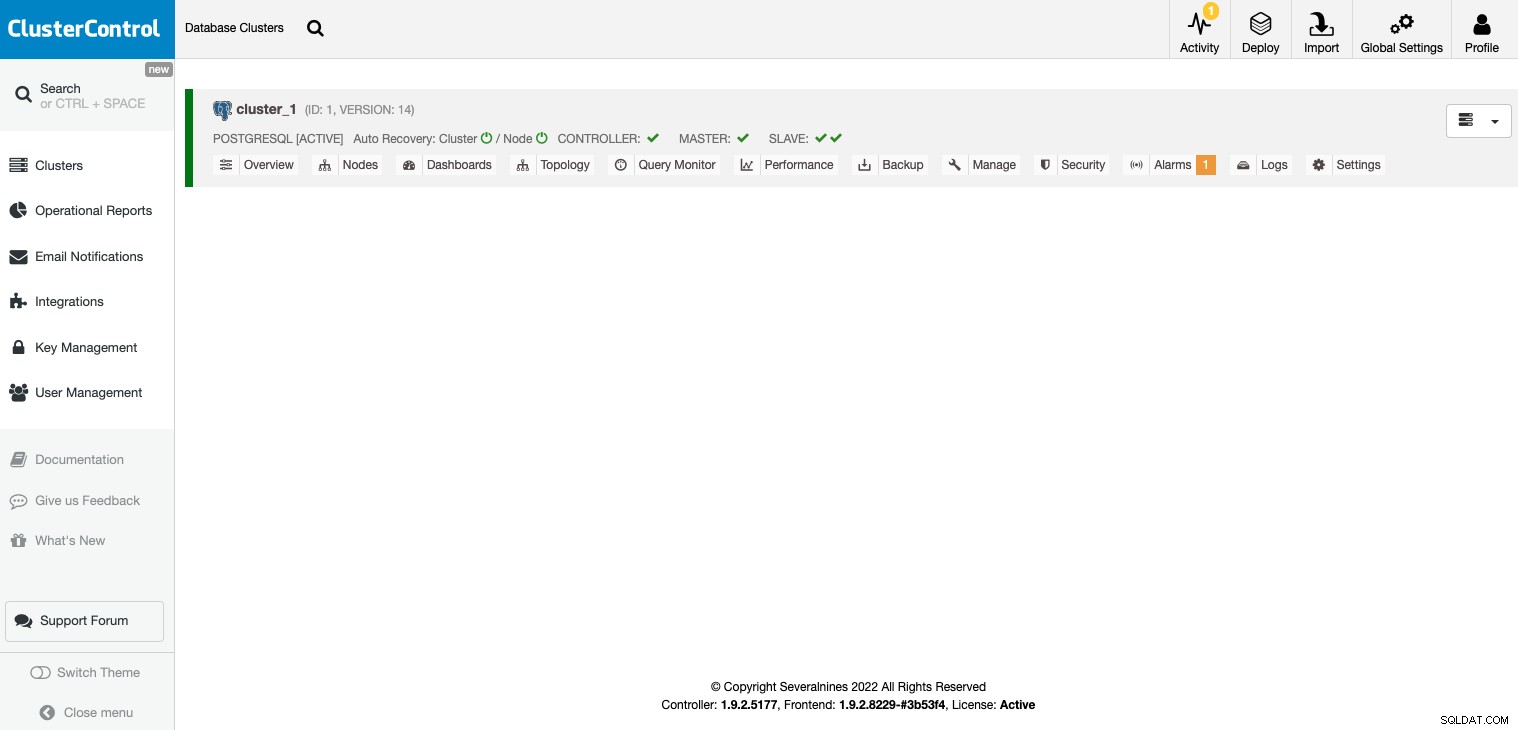
När ditt kluster har skapats kan du utföra flera uppgifter, som att lägga till en lastbalanserare (HAProxy) eller en ny kopia.
Load Balancer Deployment
För att utföra en lastbalanserare, välj alternativet "Lägg till lastbalanserare" i klusteråtgärderna och fyll i den begärda informationen.
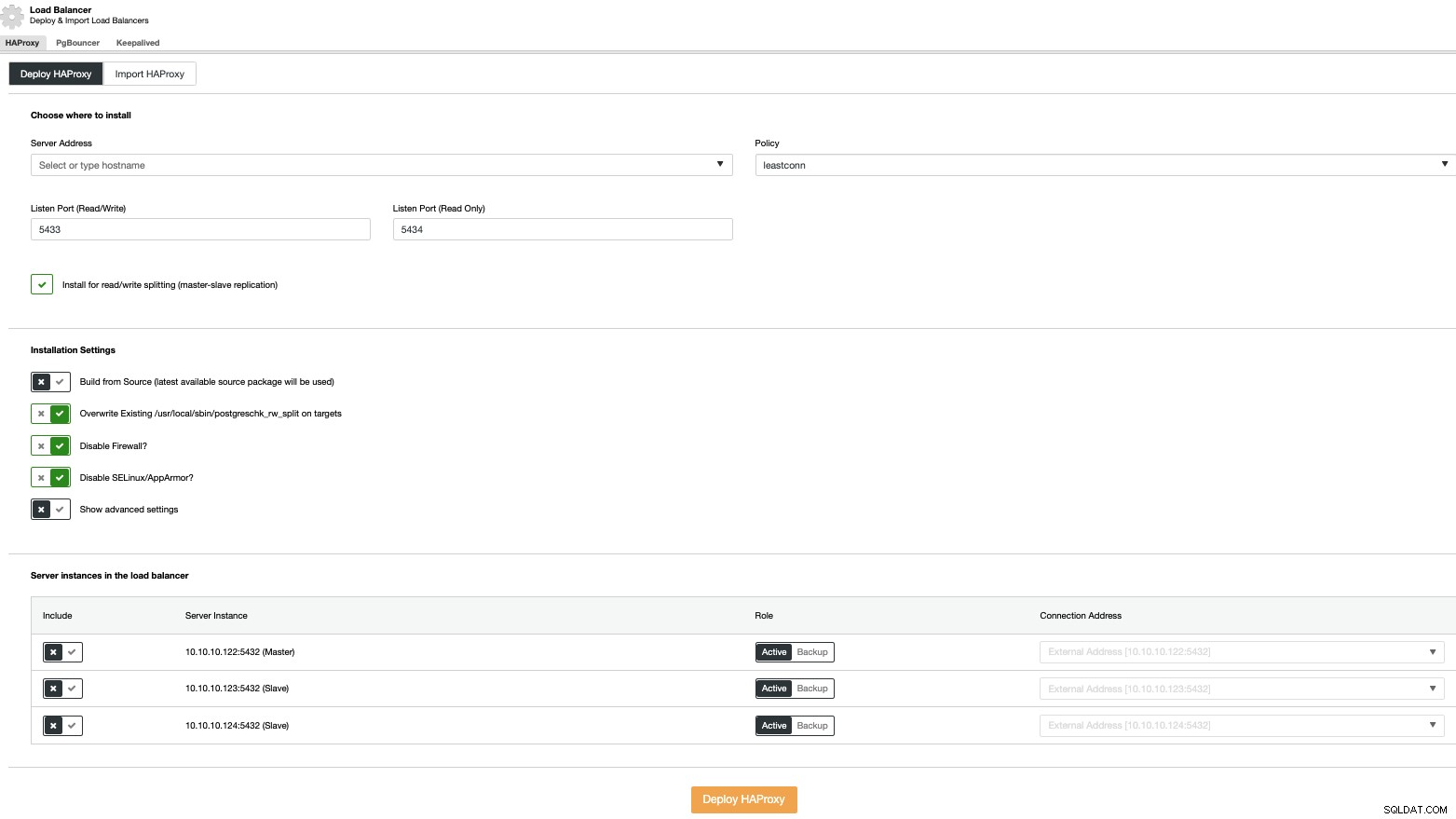
Du behöver bara lägga till IP-adressen eller värdnamn, port, policy, och noderna du kommer att konfigurera i dina lastbalanserare.
Keelived Deployment
För att utföra en Keepalive-distribution, välj klustret, gå till menyn "Hantera" och avsnittet "Load Balancer" och välj sedan alternativet "Keepalived".
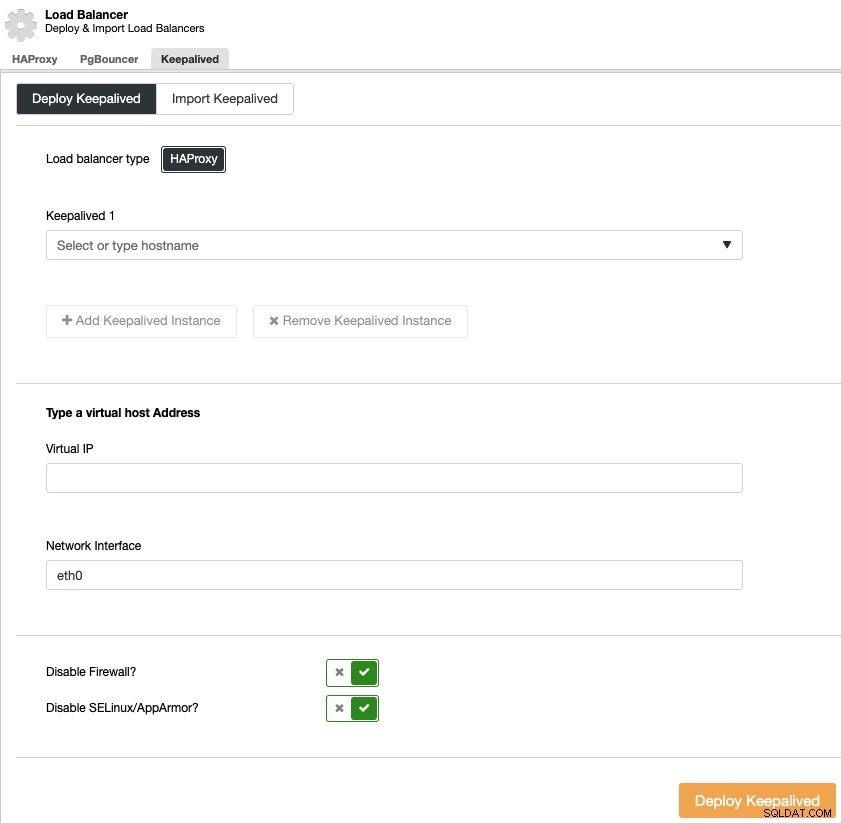
Du måste välja lastbalanseringsservrarna och den virtuella IP-adressen för din höga tillgänglighetsmiljö.
Keelived använder den virtuella IP-adressen och migrerar den från en lastbalanserare till en annan i händelse av fel, så att dina system kan fortsätta att fungera normalt.
Om du följde de föregående stegen bör du ha följande topologi:
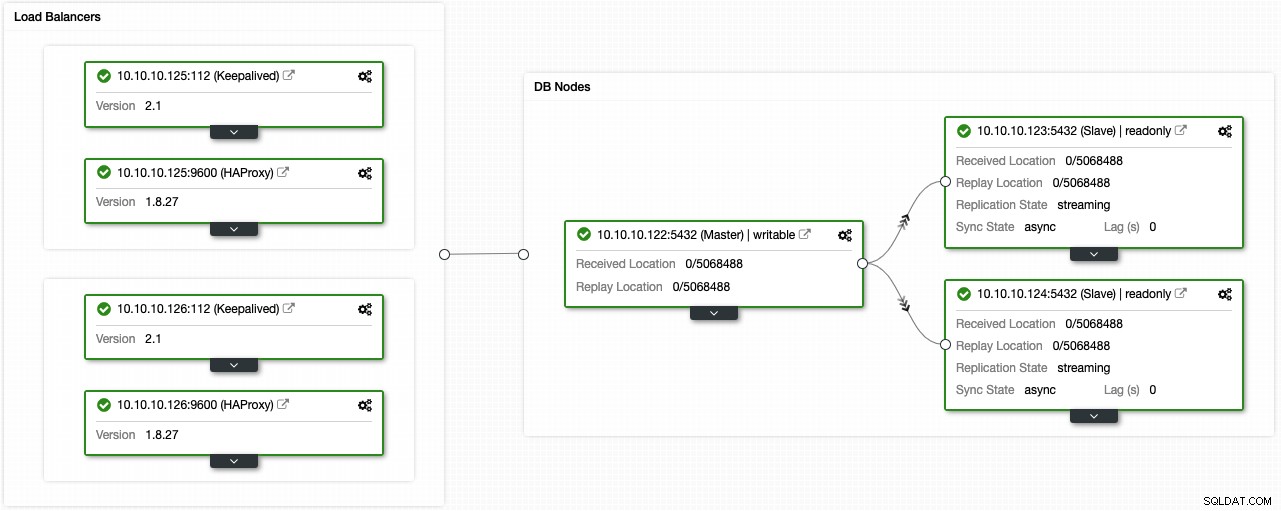
Du kan förbättra denna miljö med hög tillgänglighet genom att lägga till en anslutningspoolare som PgBouncer. Det är inte ett måste men kan vara till hjälp för att förbättra prestanda och hantera aktiva anslutningar i händelse av fel, och det bästa är att du också kan distribuera det genom att använda ClusterControl.
ClusterControl Failover
Anta att alternativet "Autorecovery" är PÅ i din ClusterControl-server. I händelse av ett primärt misslyckande kommer ClusterControl att marknadsföra det mest avancerade standbyläget (om det inte finns på den svarta listan) till primärt, samt meddela dig om problemet. Det kommer också att failover resten av Standby-noderna för att replikera från den nya primära.
HAProxy är konfigurerat som standard med två olika portar; läs-skriv- och skrivskyddade portar.
I din läs-skrivport har du din primära server som online och resten av dina noder som offline, och i den skrivskyddade porten har du både primära och vilolägen online.
När HAProxy upptäcker att en av dina noder, antingen Primär eller Standby, inte är tillgänglig, markeras den automatiskt som offline. Det tar inte hänsyn till det för att skicka trafik till det. Detektering utförs av hälsokontrollskript som ClusterControl konfigurerar vid tidpunkten för distributionen. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
När ClusterControl främjar en Standby till Primary, markerar din HAProxy den gamla Primary som offline för båda portarna och lägger den marknadsförda noden online i läs-skrivporten.
Om din aktiva HAProxy, som har tilldelats den virtuella IP-adress som dina system ansluter till, misslyckas, migrerar Keepalved denna IP-adress till din passiva HAProxy automatiskt. Det betyder att dina system sedan kan fortsätta att fungera normalt.
På detta sätt fortsätter dina system att fungera som förväntat och utan ditt manuella ingripande.
Överväganden
Om du lyckas återställa din gamla misslyckade primärnod, kommer den INTE att återinföras automatiskt till klustret som standard. Du måste göra det manuellt. En anledning till detta är att om din replik var försenad vid tidpunkten för felet, och ClusterControl lägger till den gamla primära till klustret, skulle det innebära förlust av information eller datainkonsekvens över noderna. Du kanske också vill analysera problemet i detalj. Om ClusterControl bara återinförde den misslyckade noden i klustret, skulle du eventuellt förlora diagnostisk information.
Om failover misslyckas görs inga ytterligare försök. Manuell intervention krävs för att analysera problemet och utföra motsvarande åtgärder. Detta för att undvika situationen där ClusterControl, som hög tillgänglighetshanterare, försöker främja nästa Standby och nästa. Det kan finnas ett problem och du måste kontrollera detta.
Säkerhet
En viktig sak som du inte kan glömma innan du går i produktion med din högtillgänglighetsmiljö är att säkerställa dess säkerhet.
Flera säkerhetsaspekter att överväga inkluderar kryptering, rollhantering och åtkomstbegränsning av IP-adress, som vi har behandlat ingående i en tidigare blogg.
I din PostgreSQL-databas har du filen pg_hba.conf, som hanterar klientautentiseringen. Du kan begränsa typen av anslutning, käll-IP-adress eller nätverk, vilken databas du kan ansluta till och med vilka användare. Därför är den här filen en viktig del för PostgreSQL-säkerhet.
Du kan konfigurera din PostgreSQL-databas från postgresql.conf-filen, så att den bara lyssnar på ett specifikt nätverksgränssnitt och en annan port än standardporten (5432), vilket undviker grundläggande anslutningsförsök från oönskade källor .
Riktig användarhantering, antingen genom att använda säkra lösenord eller begränsa åtkomst och privilegier, är en annan viktig del av dina säkerhetsinställningar. Det rekommenderas att du tilldelar minsta möjliga privilegier till alla användare och anger, om möjligt, källan till anslutningen.
Du kan också aktivera datakryptering, antingen under transport eller i vila, för att undvika tillgång till information för obehöriga personer.
En granskningslogg är användbar för att förstå vad som händer eller har hänt i din databas. PostgreSQL låter dig konfigurera flera parametrar för loggning eller till och med använda tillägget pgAudit för denna uppgift.
Sist men inte minst, det rekommenderas att hålla din databas och servrar uppdaterade med de senaste patcharna för att undvika säkerhetsrisker. För detta tillåter ClusterControl dig att generera driftsrapporter för att verifiera om du har tillgängliga uppdateringar och till och med hjälpa dig att uppdatera dina databasservrar.
Slutsats
Isättningar med hög tillgänglighet kan tyckas vara svåra att uppnå, särskilt när det gäller att förstå de olika arkitekturerna och nödvändiga komponenterna för att konfigurera dem korrekt.
Om du hanterar HA manuellt, var noga med att kolla in Performing Replication Topology Changes for PostgreSQL. Många kommer att leta efter verktyg som ClusterControl för att hjälpa till att hantera driftsättning, lastbalanserare, failover, säkerhet och mer för en komplett miljö med hög tillgänglighet. Du kan ladda ner ClusterControl gratis i 30 dagar för att se hur det kan underlätta bördan av att hantera en databasinfrastruktur med hög tillgänglighet.
Hur du än väljer att hantera dina PostgreSQL-databaser med hög tillgänglighet, se till att följa oss på Twitter eller LinkedIn, eller prenumerera på vårt nyhetsbrev för att få de senaste uppdateringarna och bästa praxis för att hantera dina databasinställningar.