Introduktion
Oavsett databasteknik är det nödvändigt att ha en övervakningsinställning, både för att upptäcka problem och vidta åtgärder, eller helt enkelt för att veta det aktuella tillståndet för våra system.
För detta ändamål finns det flera verktyg, betalda och gratis. I den här bloggen kommer vi att fokusera på en särskilt:Nagios Core.
Vad är Nagios Core?
Nagios Core är ett Open Source-system för övervakning av värdar, nätverk och tjänster. Det gör det möjligt att konfigurera varningar och har olika tillstånd för dem. Det tillåter implementering av plugins, utvecklade av communityn, eller låter oss till och med konfigurera våra egna övervakningsskript.
Hur installerar jag Nagios?
Den officiella dokumentationen visar oss hur man installerar Nagios Core på CentOS- eller Ubuntu-system.
Låt oss se ett exempel på nödvändiga steg för installationen på CentOS 7.
Paket krävs
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipLadda ner Nagios Core, Nagios Plugins och NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzLägg till Nagios-användare och -grupp
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheNagios-installation
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgNagios Plugin och NRPE-installation
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginVi lägger till följande rad i slutet av vår fil /usr/local/nagios/etc/objects/command.cfg för att använda NRPE när vi kontrollerar våra servrar:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios startar
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdWebåtkomst
Vi skapar användaren för att komma åt webbgränssnittet och vi kan komma in på webbplatsen.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Nagios webbåtkomst
Nagios webbåtkomst Hur konfigurerar man Nagios?
Nu när vi har våra Nagios installerade kan vi fortsätta med konfigurationen. För detta måste vi gå till den plats som motsvarar vår installation, i vårt exempel /usr/local/nagios/etc.
Det finns flera olika konfigurationsfiler som du kommer att behöva skapa eller redigera innan du börjar övervaka något.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: CGI-konfigurationsfilen innehåller ett antal direktiv som påverkar driften av CGI:erna. Den innehåller också en referens till huvudkonfigurationsfilen, så att CGI:erna vet hur du har konfigurerat Nagios och var dina objektdefinitioner lagras.
- htpasswd.users: Den här filen innehåller de användare som skapats för att komma åt Nagios webbgränssnitt.
- nagios.cfg: Huvudkonfigurationsfilen innehåller ett antal direktiv som påverkar hur Nagios Core-demonen fungerar.
- objekt: När du installerar Nagios placeras flera exempelobjektkonfigurationsfiler här. Du kan använda dessa exempelfiler för att se hur objektsarv fungerar och lära dig hur du definierar dina egna objektdefinitioner. Objekt är alla element som är involverade i övervaknings- och meddelandelogiken.
- resource.cfg: Detta används för att ange en valfri resursfil som kan innehålla makrodefinitioner. Makron låter dig referera till information om värdar, tjänster och andra källor i dina kommandon.
Inom objekt kan vi hitta mallar, som kan användas när man skapar nya objekt. Till exempel kan vi se att det i vår fil /usr/local/nagios/etc/objects/templates.cfg finns en mall som heter linux-server, som kommer att användas för att lägga till våra servrar.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Med den här mallen kommer våra värdar att ärva konfigurationen utan att behöva ange dem en efter en på varje server som vi lägger till.
Vi har också fördefinierade kommandon, kontakter och tidsperioder.
Kommandona kommer att användas av Nagios för sina kontroller, och det är vad vi lägger till i konfigurationsfilen för varje server för att övervaka den. Till exempel PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Vi har möjlighet att skapa kontakter eller grupper, och specificera vilka varningar jag vill nå vilken person eller grupp.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}För våra kontroller och varningar kan vi konfigurera under vilka timmar och dagar vi vill ta emot dem. Om vi har en tjänst som inte är kritisk vill vi förmodligen inte vakna i gryningen, så det vore bra att larma bara på arbetstid för att undvika detta.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Låt oss nu se hur man lägger till varningar till våra Nagios.
Vi kommer att övervaka våra PostgreSQL-servrar, så vi lägger först till dem som värdar i vår objektkatalog. Vi kommer att skapa 3 nya filer:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Sedan måste vi lägga till dem i filen nagios.cfg och här har vi 2 alternativ.
Lägg till våra värdar (cfg-filer) en efter en med variabeln cfg_file (standardalternativ) eller lägg till alla cfg-filer som vi har i en katalog med hjälp av variabeln cfg_dir.
Vi lägger till filerna en efter en enligt standardstrategin.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgMed detta har vi våra värdar övervakade. Nu ska vi bara lägga till vilka tjänster vi vill övervaka. För detta kommer vi att använda några redan definierade kontroller (check_ssh och check_ping), och vi kommer att lägga till några grundläggande kontroller av operativsystemet som belastning och diskutrymme, bland annat med NRPE.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperVad är NRPE?
Nagios Remote Plugin Executor. Det här verktyget tillåter oss att köra Nagios-plugins på en fjärrvärd på ett så transparent sätt som möjligt.
För att kunna använda det måste vi installera servern i varje nod som vi vill övervaka, och våra Nagios kommer att ansluta som en klient till var och en av dem och köra motsvarande plugin(s).
Hur installerar man NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeSedan redigerar vi konfigurationsfilen /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>Och vi startar om NRPE-tjänsten:
[example@sqldat.com ~]# systemctl restart nrpeVi kan testa anslutningen genom att köra följande från vår Nagios-server:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Hur övervakar man PostgreSQL?
När du övervakar PostgreSQL finns det två huvudområden att ta hänsyn till:operativsystem och databaser.
För operativsystemet har NRPE några grundläggande kontroller konfigurerade såsom diskutrymme och laddning, bland annat. Dessa kontroller kan aktiveras mycket enkelt på följande sätt.
I våra noder redigerar vi filen /usr/local/nagios/etc/nrpe.cfg och går till där följande rader är:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Namnen inom hakparenteser är de som vi kommer att använda i vår Nagios-server för att aktivera dessa kontroller.
I vår Nagios redigerar vi filerna för de tre noderna:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgVi lägger till dessa kontroller som vi såg tidigare och lämnar våra filer enligt följande:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}Och vi startar om nagios-tjänsten:
[example@sqldat.com ~]# systemctl start nagiosVid det här laget, om vi går till tjänsteavsnittet i webbgränssnittet för våra Nagios, borde vi ha något i stil med följande:
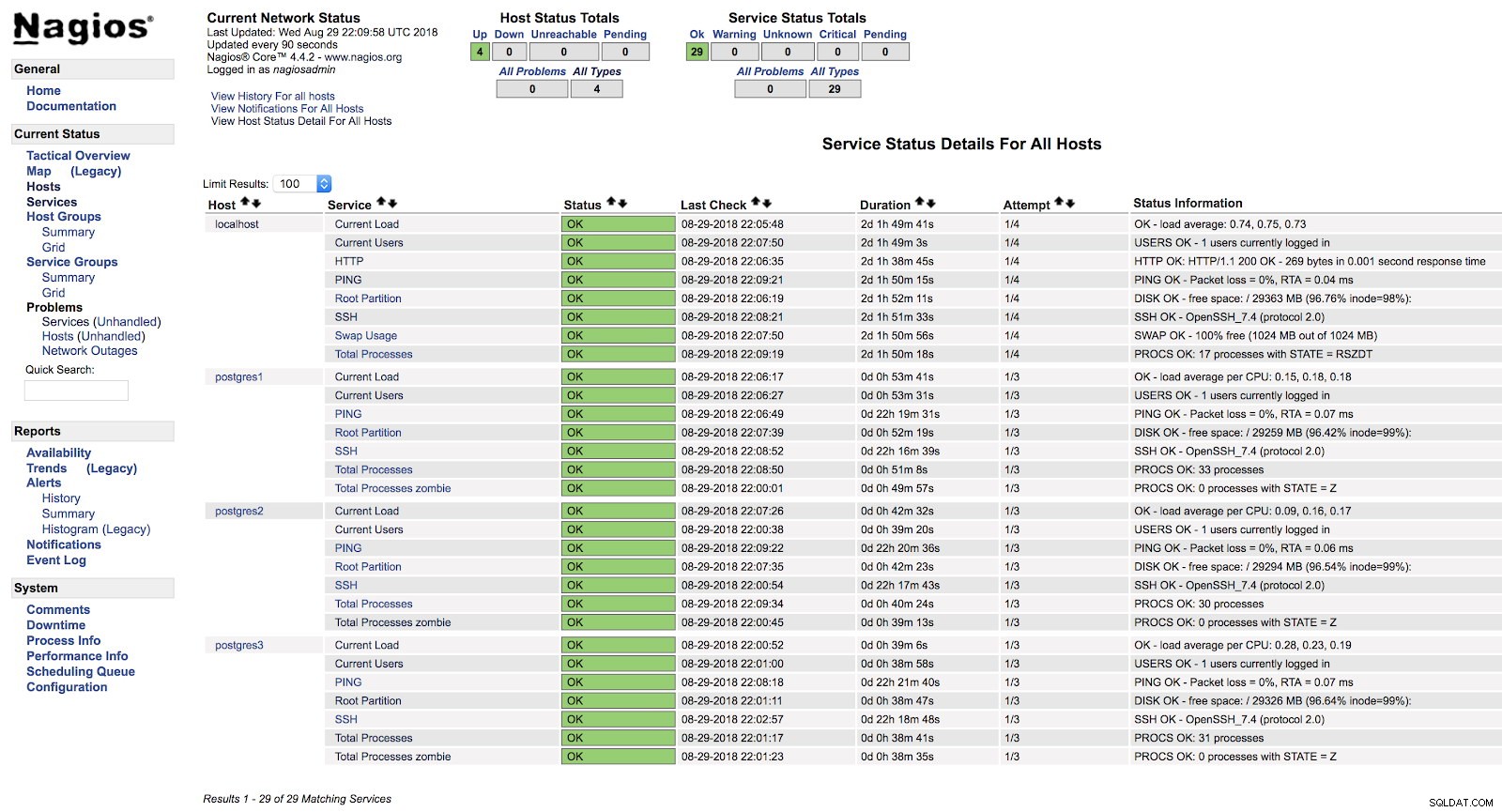 Nagios Host Alerts
Nagios Host Alerts På detta sätt kommer vi att täcka de grundläggande kontrollerna av vår server på operativsystemnivå.
Vi har många fler checkar som vi kan lägga till och vi kan till och med skapa våra egna checkar (vi får se ett exempel senare).
Låt oss nu se hur vi övervakar vår PostgreSQL-databasmotor med två av de huvudsakliga plugins som är designade för denna uppgift.
Check_postgres
En av de mest populära plugins för att kontrollera PostgreSQL är check_postgres från Bucardo.
Låt oss se hur man installerar det och hur man använder det med vår PostgreSQL-databas.
Paket krävs
[example@sqldat.com ~]# yum install perl-develInstallation
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksDet här sista kommandot skapar länkarna för att använda alla funktioner i denna kontroll, såsom check_postgres_connection, check_postgres_last_vacuum eller check_postgres_replication_slots bland andra.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Vi lägger till i vår NRPE-konfigurationsfil (/usr/local/nagios/etc/nrpe.cfg) raden för att utföra kontrollen vi vill använda:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100I vårt exempel har vi lagt till 4 grundläggande kontroller för PostgreSQL. Vi kommer att övervaka Lås, Bloat, Connection och Backends.
I filen som motsvarar vår databas på Nagios-servern (/usr/local/nagios/etc/objects/postgres1.cfg), lägger vi till följande poster:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}Och efter att ha startat om båda tjänsterna (NRPE och Nagios) på båda servrarna kan vi se våra varningar konfigurerade.
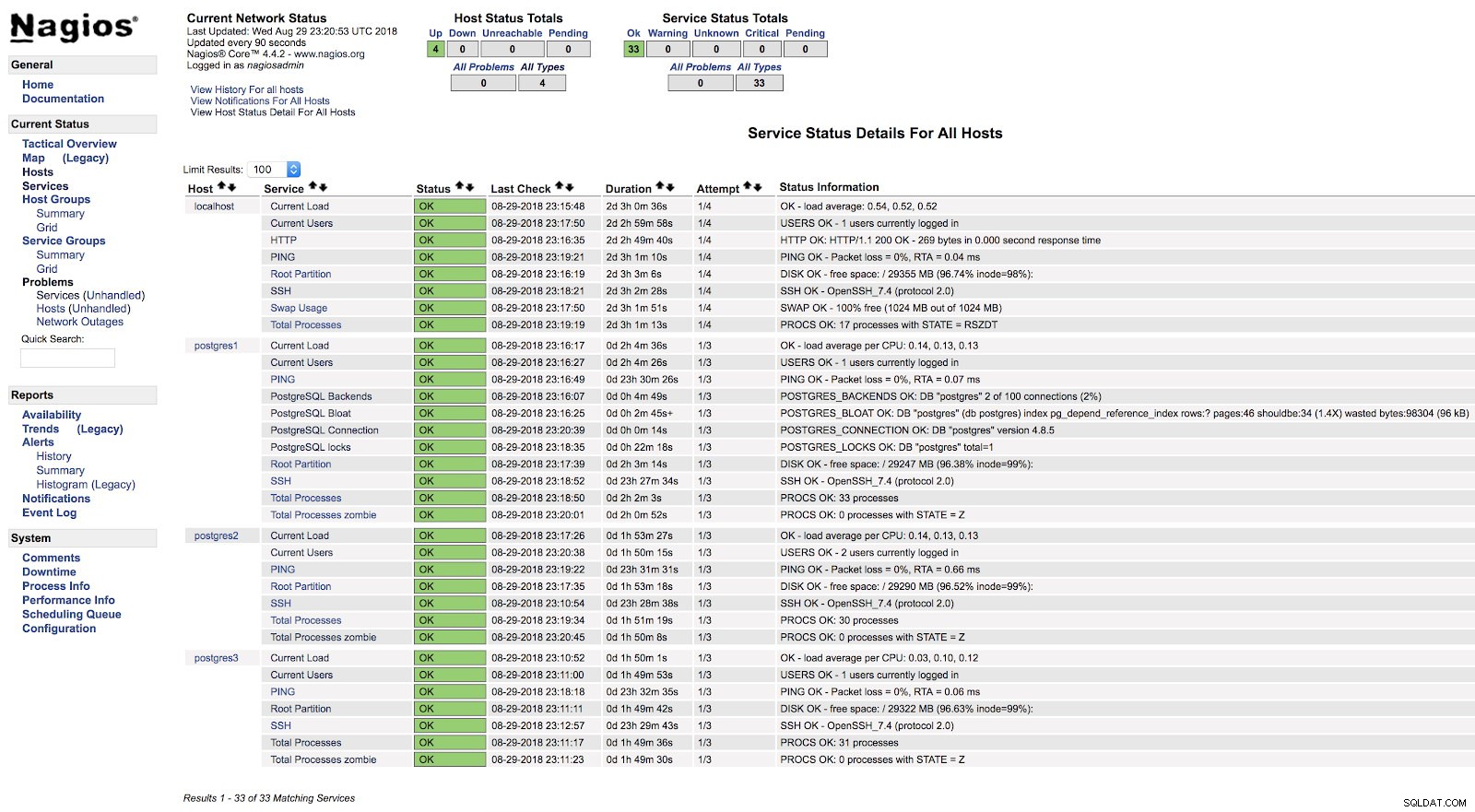 Nagios check_postgres Alerts
Nagios check_postgres Alerts I den officiella dokumentationen för plugin-programmet check_postgres kan du hitta information om vad mer du ska övervaka och hur du gör det.
Check_pgactivity
Nu är det turen till check_pgactivity, även populärt för att övervaka vår PostgreSQL-databas.
Installation
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityVi lägger till i vår NRPE-konfigurationsfil (/usr/local/nagios/etc/nrpe.cfg) raden för att utföra kontrollen vi vill använda:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10I vårt exempel kommer vi att lägga till 4 grundläggande kontroller för PostgreSQL. Vi kommer att övervaka backends, anslutning, ogiltiga index och lås.
I filen som motsvarar vår databas på Nagios-servern (/usr/local/nagios/etc/objects/postgres2.cfg), lägger vi till följande poster:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}Och efter att ha startat om båda tjänsterna (NRPE och Nagios) på båda servrarna kan vi se våra varningar konfigurerade.
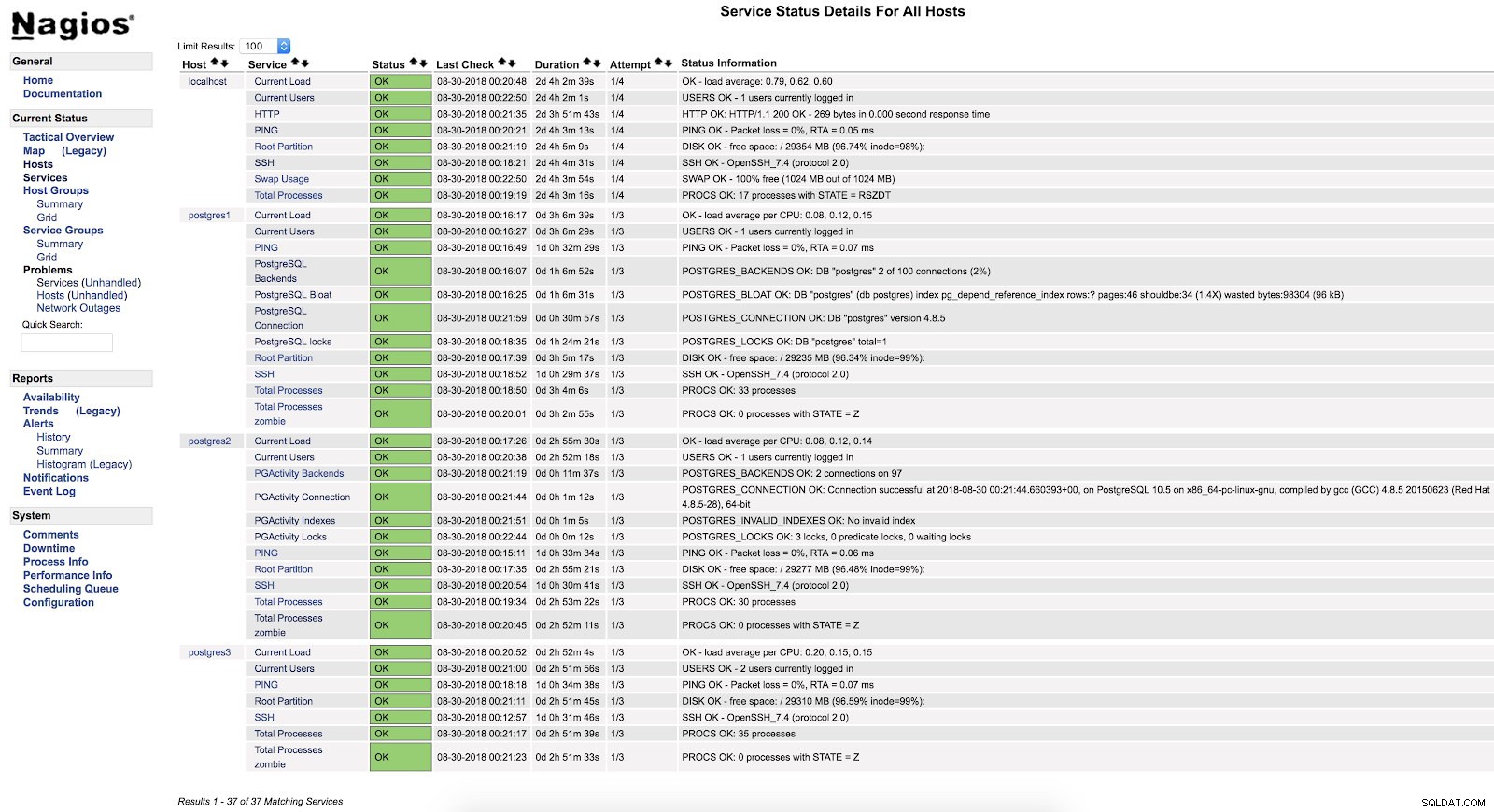 Nagios check_pgactivity-varningar
Nagios check_pgactivity-varningar Kontrollera fellogg
En av de viktigaste kontrollerna, eller den viktigaste, är att kontrollera vår fellogg.
Här kan vi hitta olika typer av fel som FATAL eller dödläge, och det är en bra utgångspunkt för att analysera eventuella problem vi har i vår databas.
För att kontrollera vår fellogg kommer vi att skapa vårt eget övervakningsskript och integrera det i våra Nagios (detta är bara ett exempel, det här skriptet kommer att vara grundläggande och har gott om utrymme för förbättringar).
Skript
Vi kommer att skapa filen /usr/local/nagios/libexec/check_postgres_log.sh på vår PostgreSQL3-server.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiDet viktiga med skriptet är att korrekt skapa utdata som motsvarar varje tillstånd. Dessa utdata läses av Nagios och varje nummer motsvarar ett tillstånd:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNI vårt exempel kommer vi bara att använda 2 tillstånd, OK och KRITISK, eftersom vi bara är intresserade av att veta om det finns fel av typen FATAL i vår fellogg under den aktuella timmen.
Texten som vi använder innan vi lämnar kommer att visas av webbgränssnittet på våra Nagios, så det bör vara så tydligt som möjligt att använda detta som en guide till problemet.
När vi har avslutat vårt övervakningsskript kommer vi att fortsätta med att ge det körrättigheter, tilldela det till användarnagios och lägga till det till vår databasserver NRPE såväl som till våra Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Starta om NRPE och Nagios. Sedan kan vi se vår kontroll i Nagios-gränssnittet:
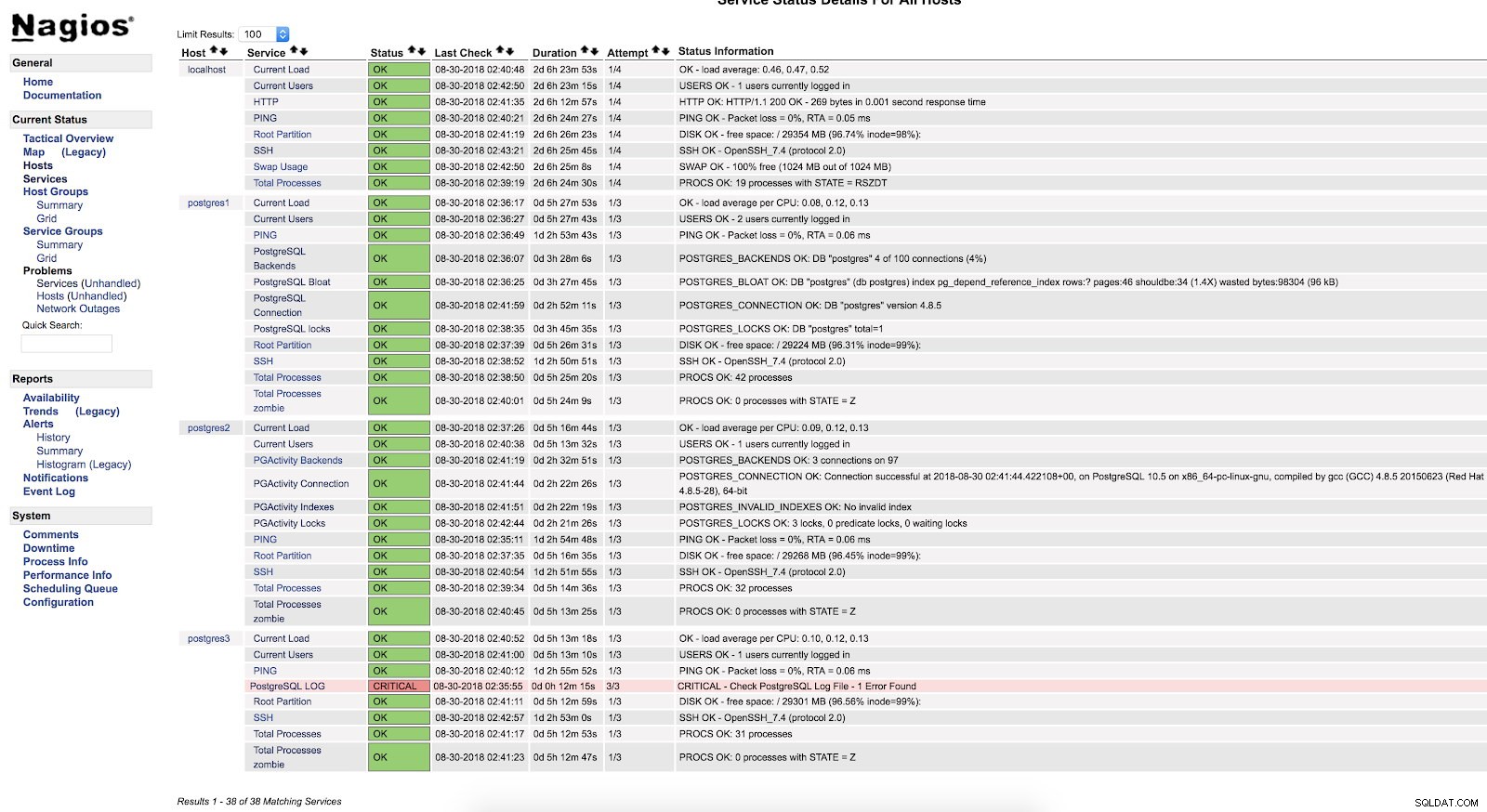 Nagios Script Alerts
Nagios Script Alerts Som vi kan se är det i ett KRITISKT tillstånd, så om vi går till loggen kan vi se följande:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"För mer information om vad vi kan övervaka i vår PostgreSQL-databas rekommenderar jag att du kollar våra prestations- och övervakningsbloggar eller detta Postgres Performance-webinarium.
Säkerhet och prestanda
När vi konfigurerar någon övervakning, antingen med plugins eller vårt eget skript, måste vi vara mycket försiktiga med två mycket viktiga saker - säkerhet och prestanda.
När vi tilldelar de nödvändiga behörigheterna för övervakning måste vi vara så restriktiva som möjligt, begränsa åtkomsten endast lokalt eller från vår övervakningsserver, använda säkra nycklar, kryptera trafik, tillåta anslutningen till det minimum som krävs för att övervakningen ska fungera.
När det gäller prestanda är övervakning nödvändig, men det är också nödvändigt att använda det säkert för våra system.
Vi måste vara försiktiga så att vi inte genererar orimligt hög diskåtkomst eller kör frågor som negativt påverkar vår databas prestanda.
Om vi har många transaktioner per sekund som genererar gigabyte med loggar, och vi fortsätter att leta efter fel kontinuerligt, är det förmodligen inte det bästa för vår databas. Så vi måste hålla en balans mellan vad vi övervakar, hur ofta och påverkan på prestanda.
Slutsats
Det finns flera sätt att implementera övervakning eller att konfigurera den. Vi kan göra det så komplicerat eller så enkelt som vi vill. Målet med den här bloggen var att introducera dig i övervakningen av PostgreSQL med ett av de mest använda verktygen med öppen källkod. Vi har också sett att konfigurationen är väldigt flexibel och kan skräddarsys efter olika behov.
Och glöm inte att vi alltid kan lita på gemenskapen, så jag lämnar några länkar som kan vara till stor hjälp.
Supportforum:https://support.nagios.com/forum/
Kända problem:https://github.com/NagiosEnterprises/nagioscore/issues
Nagios Plugins:https://exchange.nagios.org/directory/Plugins
Nagios plugin för ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol