När du distribuerar ett databaskluster på olika servrar har du uppnått replikeringsfördelen med att förbättra datatillgängligheten. Det finns dock ett behov av att hålla reda på processer och se om de körs eller inte. Ett av programmen som används i denna process är Heartbeat som har förmågan att kontrollera och verifiera närvaron av resurser på ett eller flera system i ett givet kluster. Förutom PostgreSQL och filsystemen för vilka PostgreSQL-data lagras, är DRBD en av resurserna som vi kommer att diskutera i den här artikeln om hur Heartbeat-programmet kan användas.
HA hjärtslag
Som diskuterats tidigare i DRBD-bloggen uppnås en hög tillgänglighet av data genom att köra olika instanser av servern men servera samma data. Dessa körande serverinstanser kan definieras som ett kluster i förhållande till ett Heartbeat. I grund och botten är var och en av serverinstanserna fysiskt kapabla att tillhandahålla samma tjänst som de andra inom det klustret. Endast en instans kan dock aktivt tillhandahålla tjänster åt gången i syfte att säkerställa hög tillgänglighet av data. Vi kan därför definiera de andra fallen som "hot-spares" som kan tas i bruk i händelse av fel på mastern. Heartbeat-paketet kan laddas ner från denna länk. När du har installerat det här paketet kan du konfigurera det för att fungera med ditt system med proceduren nedan. En enkel struktur för Heartbeat-konfigurationen är:
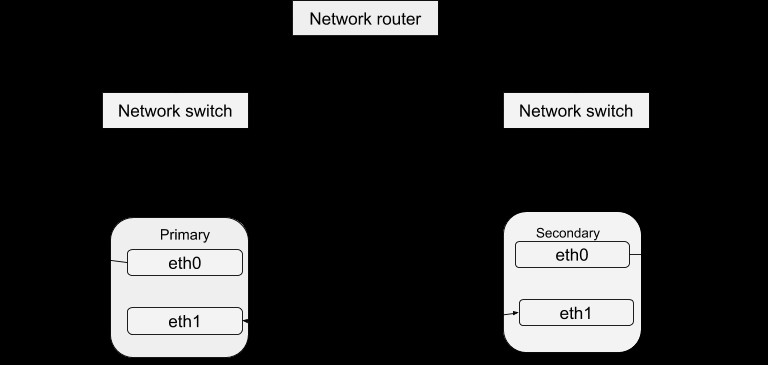
Konfiguration av hjärtslag
Om du tittar in i den här katalogen /etc/ha.d hittar du några filer som används i konfigurationsprocessen. Ha.cf-filen utgör den huvudsakliga hjärtslagskonfigurationen. Den innehåller en lista över alla noder och tider för att identifiera fel förutom att styra hjärtslag på vilken typ av mediabanor som ska användas och hur man konfigurerar dem. Säkerhetsinformation för klustret registreras i authkeys-filen. Inspelad information i dessa filer bör vara identisk för alla värdar i klustret och detta kan enkelt uppnås genom synkronisering mellan alla värdar. Det vill säga att alla ändringar av information i en värd ska kopieras till alla andra.
Ha.cf-fil
Grundkonturen av ha.cf-filen är
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Loggfunktion:den här används för att styra Heartbeat på vilken syslogloggningsfunktion den ska använda för att spela in meddelanden. Det vanligaste värdet är auth, authpriv, user, local0, syslog och daemon. Du kan också välja att inte ha några loggar så att du kan ställa in värdet till none .i.e
logfacility none - Keepalive:detta är tiden mellan hjärtslag, det vill säga frekvensen med vilken hjärtslagssignalen skickas till de andra värdarna. I exempelkoden ovan är den inställd på 3 sekunder.
- Dödtid:det är fördröjningen i sekunder efter vilken en nod sägs ha misslyckats.
- Warntime:är fördröjningen i sekunder efter vilken en varning registreras i en logg som indikerar att en nod inte längre kan kontaktas.
- Initdead:det här är tiden i sekunder att vänta under systemstart innan den andra värden anses vara nere.
- Mcast:det är en definierad metod för att skicka en hjärtslagssignal. För exempelkoden ovan används multicast-nätverksadressen över en avgränsad nätverksenhet. För ett multipelkluster måste multicastadressen vara unik för varje kluster. Du kan också välja en seriell anslutning över multicast eller om du ställer in på ett sådant sätt att det finns flera nätverksgränssnitt, använd båda för hjärtslagsanslutningen som i exemplet. Fördelen med att använda båda är att övervinna risken för övergående fel som följaktligen kan orsaka en ogiltig felhändelse.
- Auto_failback:detta återansluter en server som hade misslyckats tillbaka till klustret om den blir tillgänglig. Det kan dock orsaka förvirring om servern är påslagen och sedan kommer online vid en annan tidpunkt. I förhållande till DRBD, om den inte är välkonfigurerad, kan du sluta med mer än en datauppsättning på samma server. Därför är det lämpligt att alltid sätta den på av.
- Nod:beskriver noden inom Heartbeat-klustergruppen. Du bör ha minst en nod för varje.
Ytterligare konfigurationer
Du kan också ställa in ytterligare konfigurationsinformation som:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:detta är viktigt för att säkerställa att du har anslutning på det offentliga gränssnittet för servrarna och anslutning till en annan värd. Det är viktigt att överväga IP-adressen snarare än värdnamnet för målmaskinen.
- Respawn:detta är kommandot som ska köras när ett fel inträffar.
- Apiauth:är auktoriteten för felet. Du måste konfigurera användar- och grupp-ID som kommandot ska köras med. Authkeys-filen innehåller behörighetsinformationen för Heartbeat-klustret och denna nyckel är mycket unik för att verifiera maskiner inom ett givet Heartbeat-kluster.
- Deadping:definierar tidsgränsen innan ett uteblivet svar utlöser ett fel.
Integration av Heartbeat med Postgres och DRBD
Som nämnts tidigare, när en huvudserver misslyckas, kommer en annan server med ett visst kluster att hoppa till handling för att tillhandahålla samma tjänst. Heartbeat hjälper till med konfigurationen av resurser som förbättrar valet av en server i händelse av fel. Den definierar till exempel vilka individuella servrar som ska tas upp eller kasseras vid fel. När vi checkar in på filen haresources i katalogen /etc/ha.d får vi en översikt över de resurser som kan hanteras. Resursfilens sökväg är /etc/ha.d/resource.d och resursdefinitionen finns på en rad som är:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(observera blanktecken).
- Drbd1:hänvisar till namnet på den föredragna värden för att vara mer sekant den server som normalt används som standardmaster för att hantera tjänsten. Som nämnts i DRBD-bloggen behöver vi resurser för vår server och dessa definieras i raden som drbddisk, filsystem och postgres. Det sista fältet är en virtuell IP-adress som ska användas för att dela tjänsten, dvs ansluta till Postgres-servern. Som standard kommer den att allokeras till servern som är aktiv när Heartbeat börjar. När ett fel inträffar kommer dessa resurser att startas på backupservern i ordningsföljd när motsvarande skript anropas. I inställningen kommer skriptet att växla DRBD-disken på den sekundära värden till primärt läge, vilket gör att enheten läser/skriver.
- Filsystem:detta kommer att hantera filsystemresurserna och i det här fallet har DRBD valts så att den kommer att monteras under anropet av resursskriptet.
- Postgres:detta kommer antingen att starta eller hantera Postgres-servern
Ibland vill du få aviseringar via e-post. För att göra det, lägg till den här raden i resursfilen med din e-post för att ta emot varningstexterna:
MailTo:: example@sqldat.com::DRBDFailureFör att starta hjärtslag kan du köra kommandot
/etc/ha.d/heartbeat starteller starta om både den primära och sekundära servern. Om du nu kör kommandot
$ /usr/lib64/heartbeat/hb_standbyDen aktuella noden kommer att triggas för att avstå sina resurser rent till den andra noden.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperHantera systemnivåfel
Ibland kan serverkärnan vara skadad vilket indikerar ett potentiellt problem med din server. Du kommer att behöva konfigurera servern för att ta bort sig själv från klustret under händelse av ett problem. Detta problem kallas ofta kärnpanik och det utlöser följaktligen en hård omstart på din maskin. Du kan tvinga fram en omstart genom att ställa in kernel.panic och kernel.panic_on_oop för kärnkontrollfilen /etc/sysctl.conf. Dvs
kernel.panic_on_oops = 1
kernel.panic = 1Ett annat alternativ är att göra det från kommandoraden med kommandot sysctl, dvs:
$ sysctl -w kernel.panic=1Du kan också redigera filen sysctl.conf och ladda om konfigurationsinformationen med det här kommandot.
sysctl -pVärdet anger hur många sekunder som ska vänta innan omstart. Den andra hjärtslagsnoden ska då upptäcka att servern är nere och sedan byta över failover-värden.
Slutsats
Heartbeat är ett delsystem som tillåter val av en sekundär server till primär och ett backupsystem när en aktiv server misslyckas. Det avgör också om alla andra servrar är vid liv. Det säkerställer också överföring av resurser till den nya primära noden