Att hantera trafik till databasen kan bli svårare och svårare eftersom det ökar i mängd och databasen faktiskt distribueras över flera servrar. PostgreSQL-klienter pratar vanligtvis med en enda slutpunkt. När en primär nod misslyckas kommer databasklienterna att fortsätta att försöka med samma IP. Om du har misslyckats till en sekundär nod måste applikationen uppdateras med den nya slutpunkten. Det är här du skulle vilja sätta en lastbalanserare mellan applikationerna och databasinstanserna. Den kan dirigera applikationer till tillgängliga/friska databasnoder och failover vid behov. En annan fördel skulle vara att öka läsprestandan genom att använda repliker effektivt. Det är möjligt att skapa en skrivskyddad port som balanserar läsningar över repliker. I den här bloggen kommer vi att täcka HAProxy. Vi får se vad som är, hur det fungerar och hur man distribuerar det för PostgreSQL.
Vad är HAProxy?
HAProxy är en proxy med öppen källkod som kan användas för att implementera hög tillgänglighet, lastbalansering och proxy för TCP- och HTTP-baserade applikationer.
Som en lastbalanserare distribuerar HAProxy trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för denna uppgift. Om någon av destinationerna slutar svara markeras den som offline och trafiken skickas till resten av de tillgängliga destinationerna.
Hur man installerar och konfigurerar HAProxy manuellt
För att installera HAProxy på Linux kan du använda följande kommandon:
På Ubuntu/Debian OS:
$ apt-get install haproxy -yPå CentOS/RedHat OS:
$ yum install haproxy -yOch sedan måste vi redigera följande konfigurationsfil för att hantera vår HAProxy-konfiguration:
$ /etc/haproxy/haproxy.cfgAtt konfigurera vår HAProxy är inte komplicerat, men vi måste veta vad vi gör. Vi har flera parametrar att konfigurera, beroende på hur vi vill att HAProxy ska fungera. För mer information kan vi följa dokumentationen om HAProxy-konfigurationen.
Låt oss titta på ett grundläggande konfigurationsexempel. Anta att du har följande databastopologi:
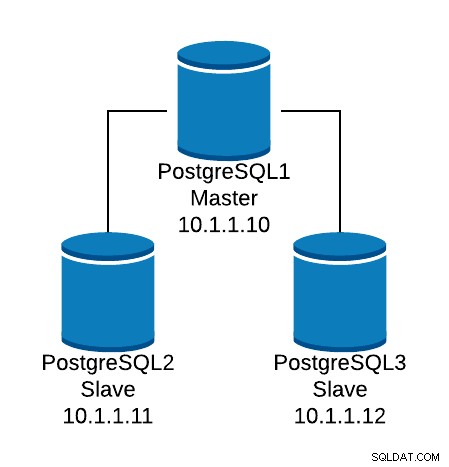 Exempel på databastopologi
Exempel på databastopologi Vi vill skapa en HAProxy-lyssnare för att balansera lästrafiken mellan de tre noderna.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkSom vi nämnde tidigare finns det flera parametrar att konfigurera här, och denna konfiguration beror på vad vi vill göra. Till exempel:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkHur HAProxy fungerar på ClusterControl
För PostgreSQL konfigureras HAProxy av ClusterControl med två olika portar som standard, en läs-skriv- och en skrivskyddad.
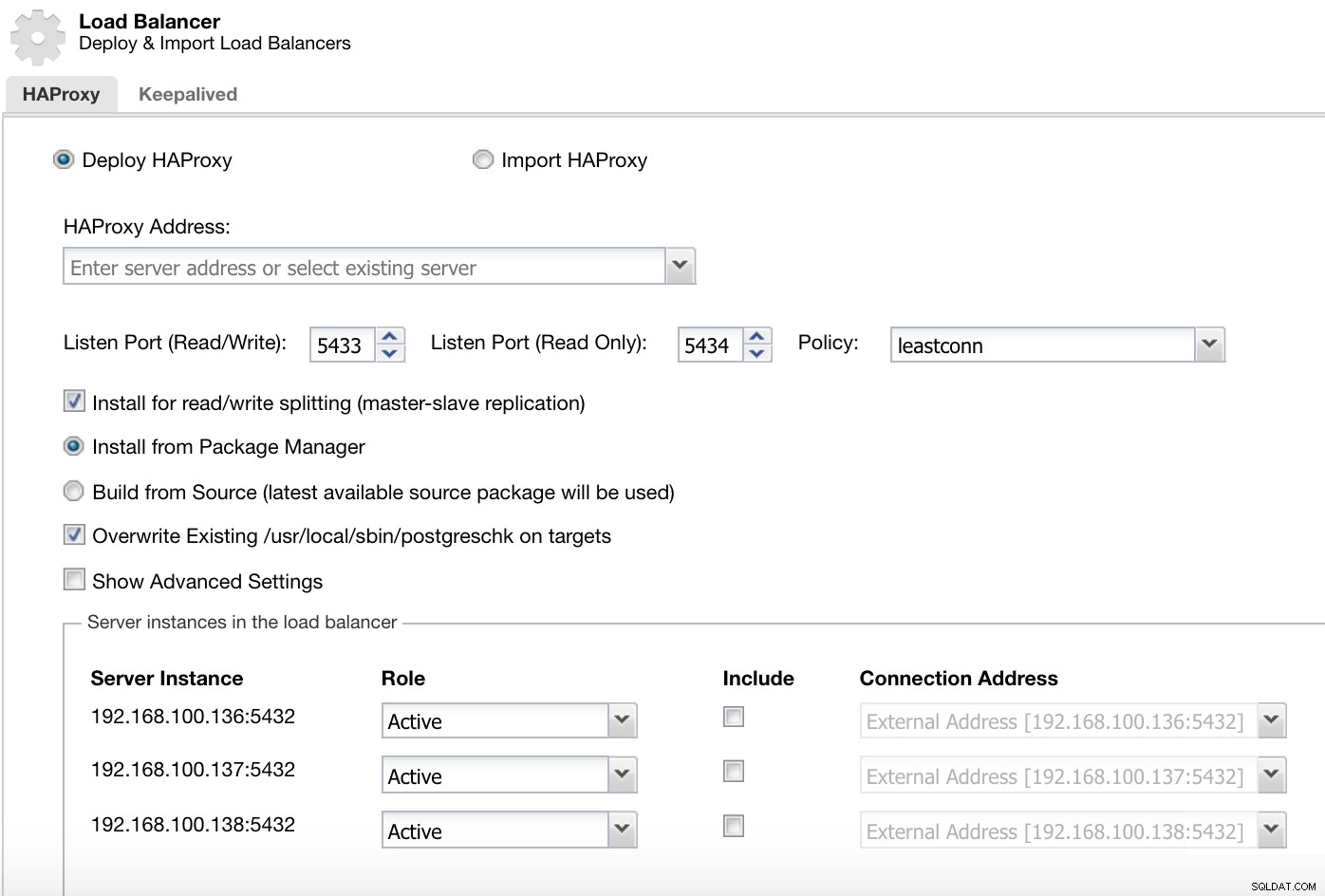 ClusterControl Load Balancer Deploy Information 1
ClusterControl Load Balancer Deploy Information 1 I vår läs- och skrivport har vi vår masterserver som online och resten av våra noder som offline, och i skrivskyddsporten har vi både mastern och slavarna online.
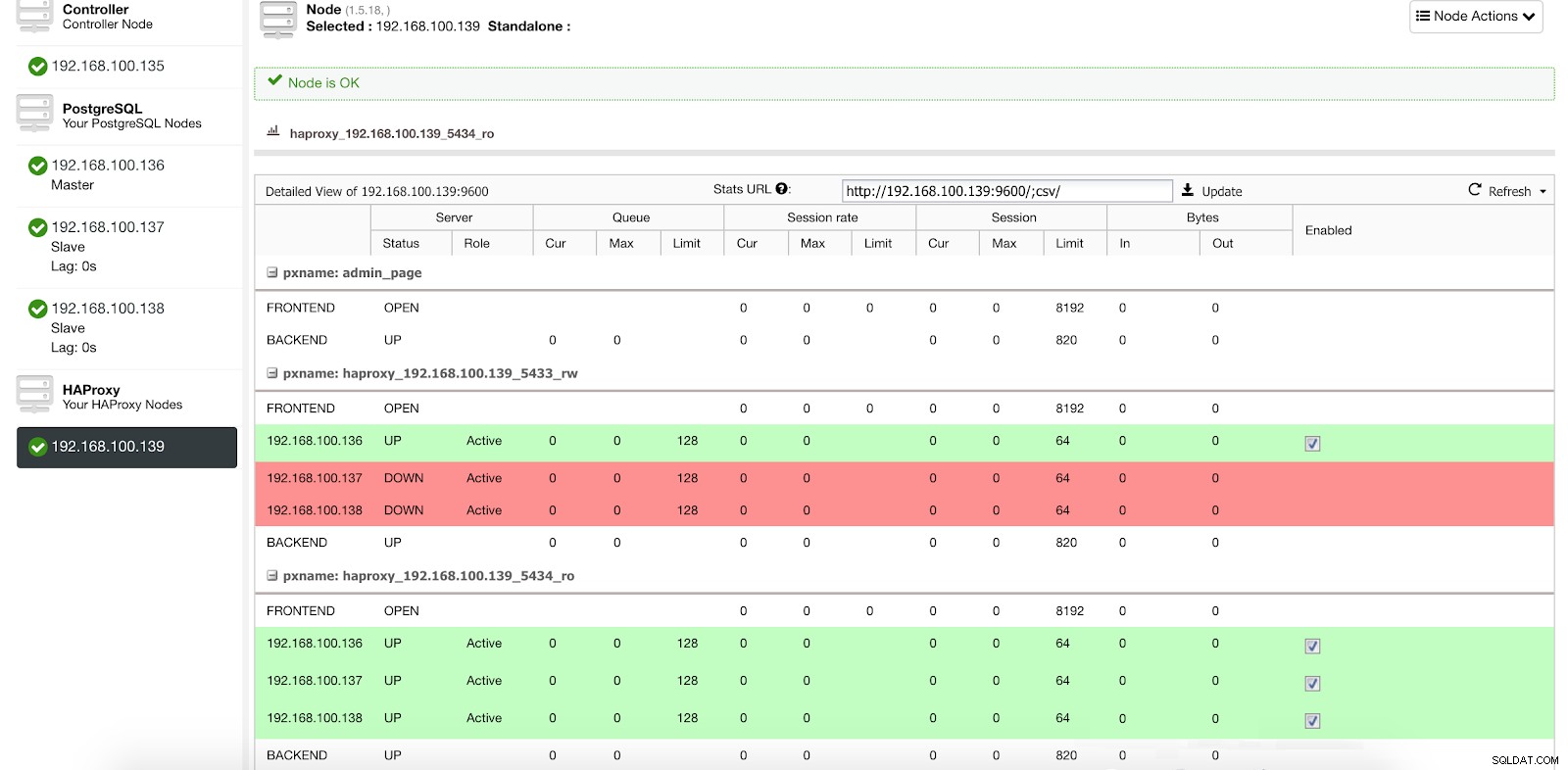 ClusterControl Load Balancer Stats 1
ClusterControl Load Balancer Stats 1 När HAProxy upptäcker att en av våra noder, antingen master eller slav, inte är tillgänglig, markerar den automatiskt den som offline och tar inte hänsyn till det när trafik skickas. Detektering görs av hälsokontrollskript som konfigureras av ClusterControl vid tidpunkten för distribution. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
När ClusterControl marknadsför en slav till mästare, markerar vår HAProxy den gamla mastern som offline (för båda portarna) och lägger den befordrade noden online (i läs-skrivporten).
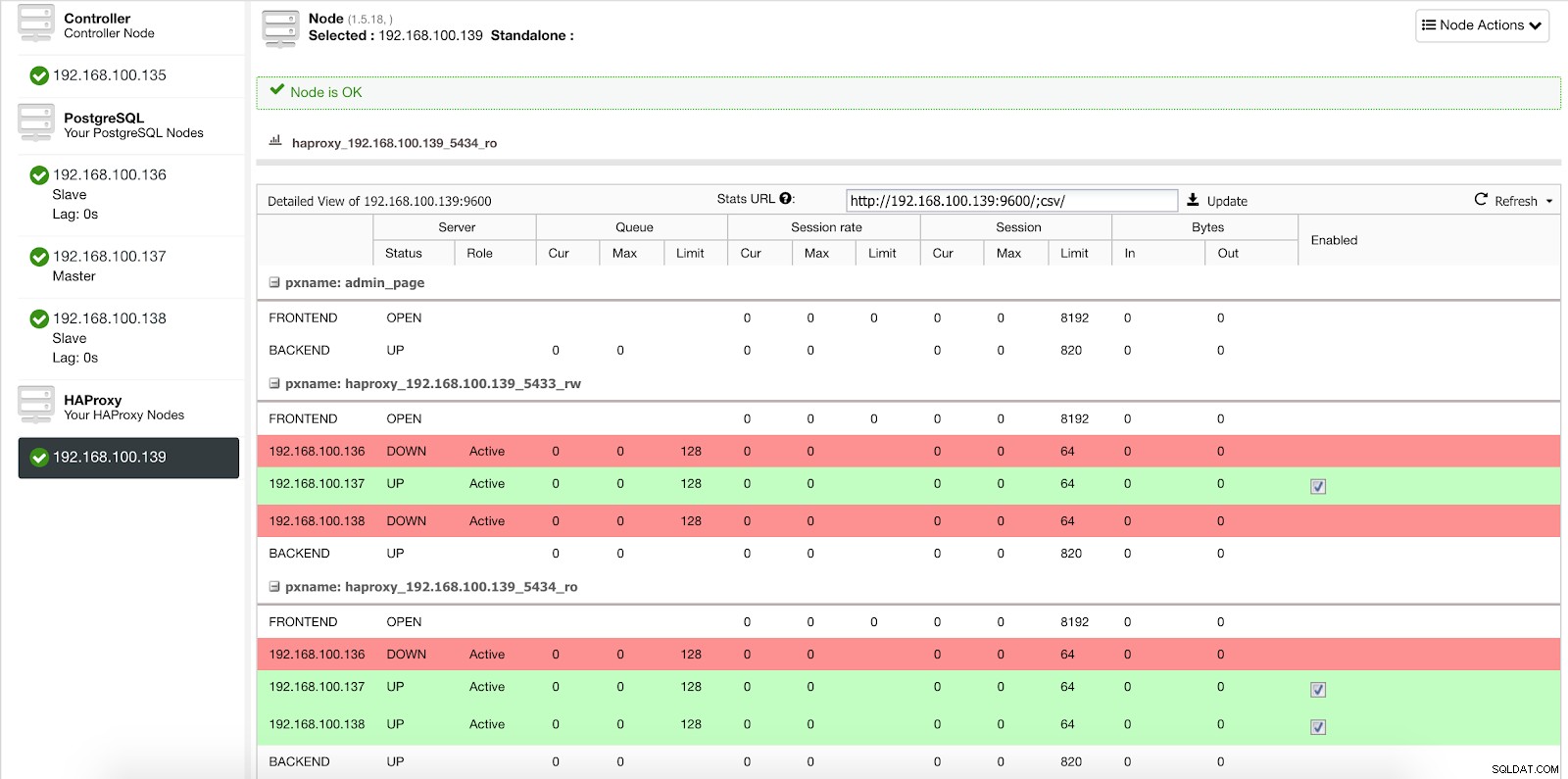 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 På detta sätt fortsätter våra system att fungera normalt och utan vår inblandning.
Hur man distribuerar HAProxy med ClusterControl
I vårt exempel skapade vi en miljö med 1 master och 2 slavar - se en skärmdump av Topology View i ClusterControl. Vi lägger nu till vår HAProxy-lastbalanserare.
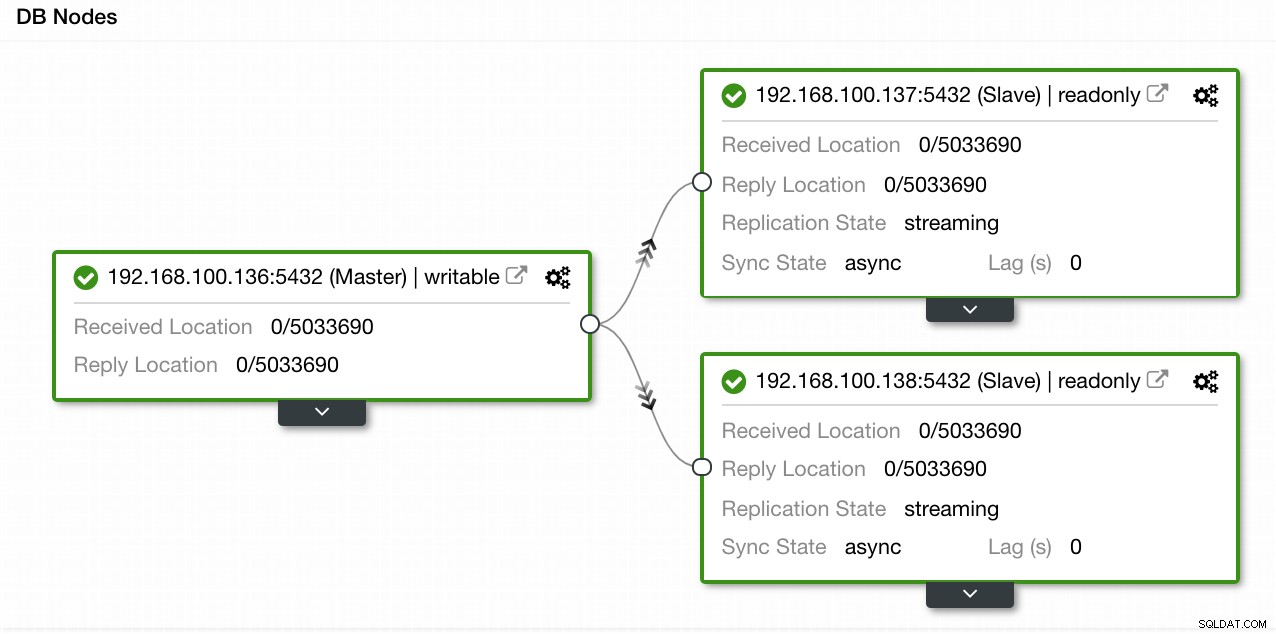 ClusterControl Topology View 1
ClusterControl Topology View 1 För denna uppgift måste vi gå till ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
 ClusterControl Cluster Actions Menu
ClusterControl Cluster Actions Menu Här måste vi lägga till informationen som ClusterControl kommer att använda för att installera och konfigurera vår HAProxy load balancer.
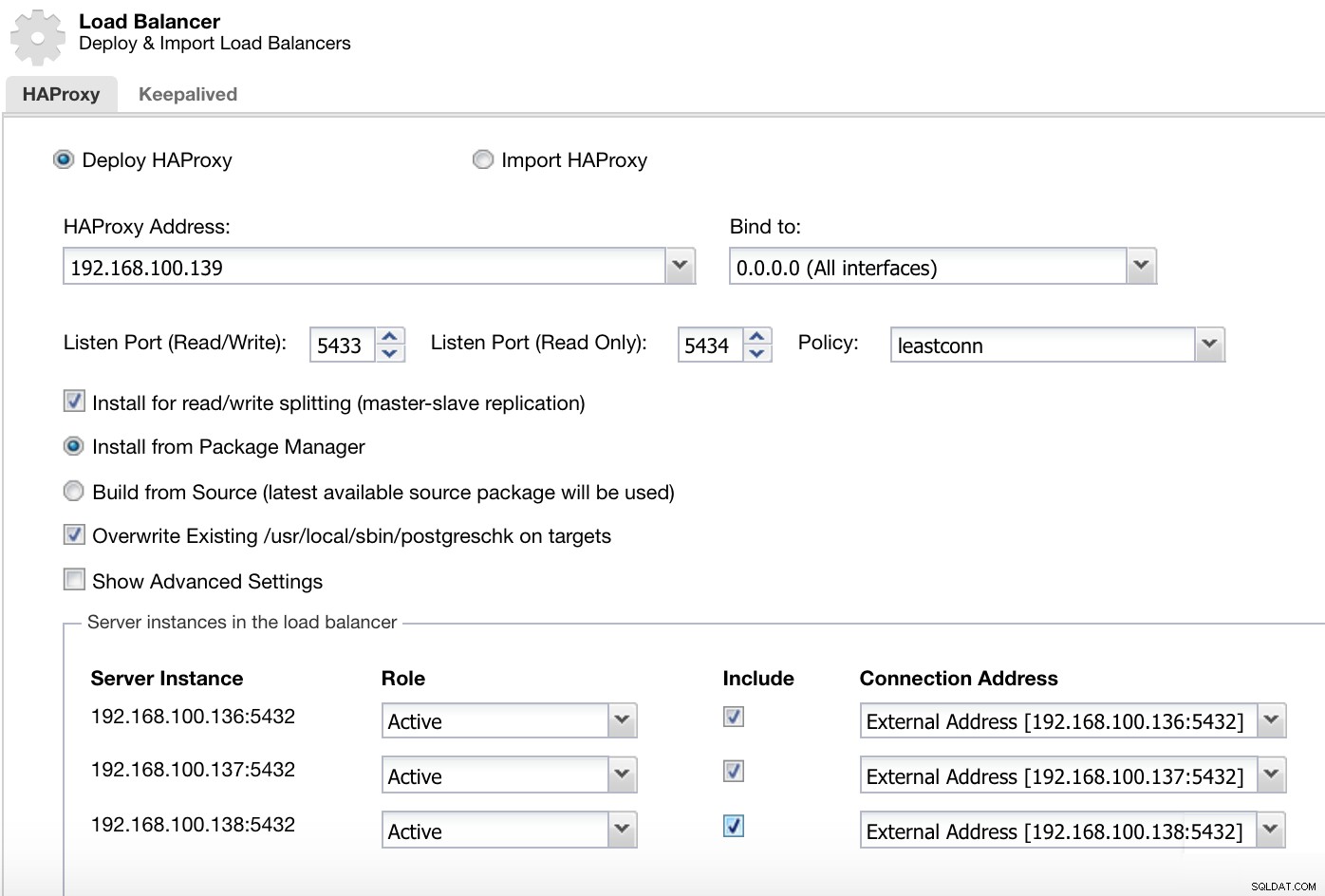 ClusterControl Load Balancer Deploy Information 2
ClusterControl Load Balancer Deploy Information 2 Informationen som vi behöver presentera är:
Åtgärd:Distribuera eller importera.
HAProxy-adress:IP-adress för vår HAProxy-server.
Bind till:Gränssnitt eller IP-adress där HAProxy lyssnar.
Lyssnasport (läs/skriv):Port för läs-/skrivläge.
Listen Port (Read Only):Port för skrivskyddat läge.
Policy:Det kan vara:
- leastconn:Servern med det lägsta antalet anslutningar tar emot anslutningen.
- roundrobin:Varje server används i tur och ordning, beroende på deras vikt.
- källa:Källans IP-adress hashas och divideras med den totala vikten av de körande servrarna för att ange vilken server som ska ta emot begäran.
Installera för läs/skrivdelning:För master-slav-replikering.
Källa:Vi kan välja Installera från en pakethanterare eller bygga från källan.
Skriv över befintlig postgreschk på mål.
Och vi måste välja vilka servrar du vill lägga till i HAProxy-konfigurationen och lite ytterligare information som:
Roll:Det kan vara aktivt eller säkerhetskopierat.
Inkludera:Ja eller Nej.
Anslutningsadressinformation.
Vi kan också konfigurera avancerade inställningar som Admin User, Backend Name, Timeouts och mer.
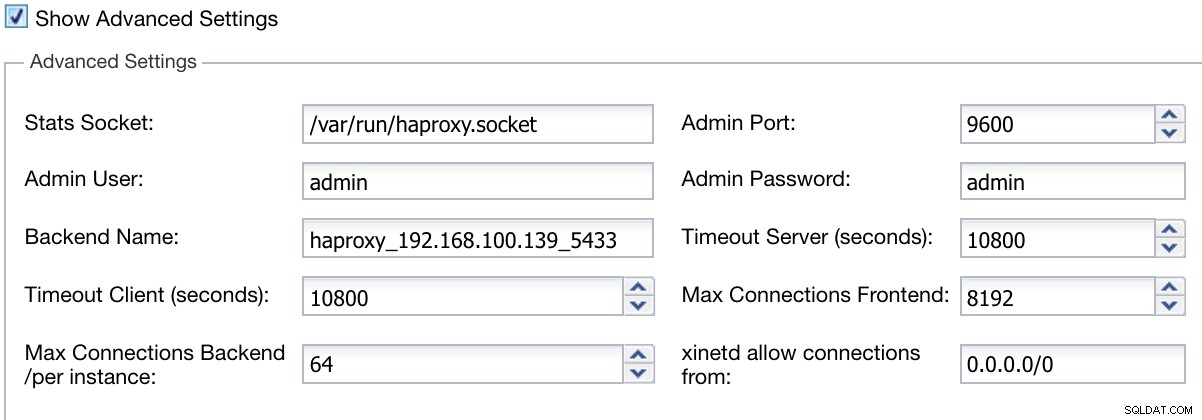 ClusterControl Load Balancer Deploy Information Advanced
ClusterControl Load Balancer Deploy Information Advanced När du är klar med konfigurationen och bekräftar distributionen kan vi följa framstegen i aktivitetsavsnittet på ClusterControl UI.
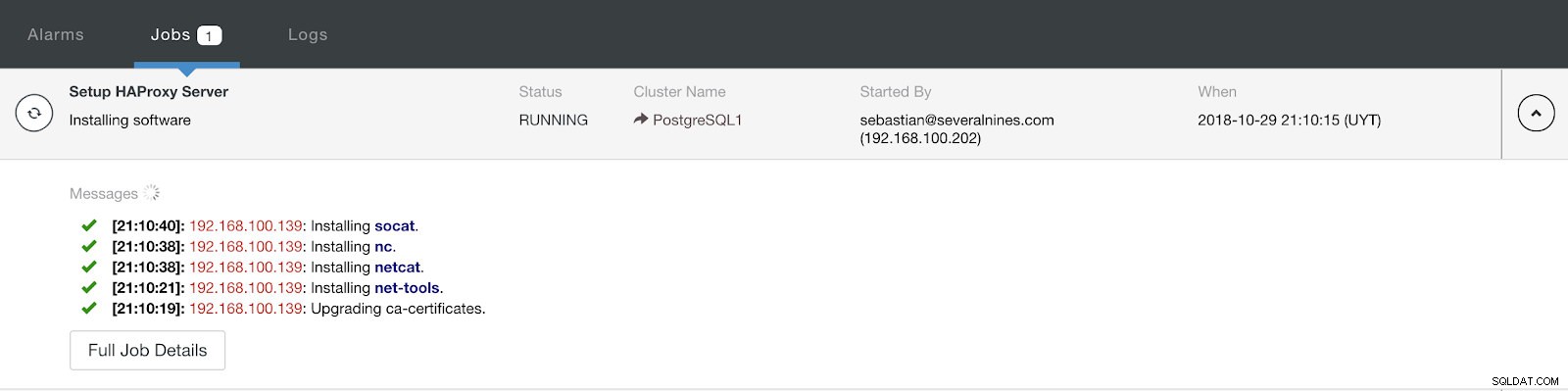 ClusterControl Activity Section
ClusterControl Activity Section När den är klar bör vi ha följande topologi:
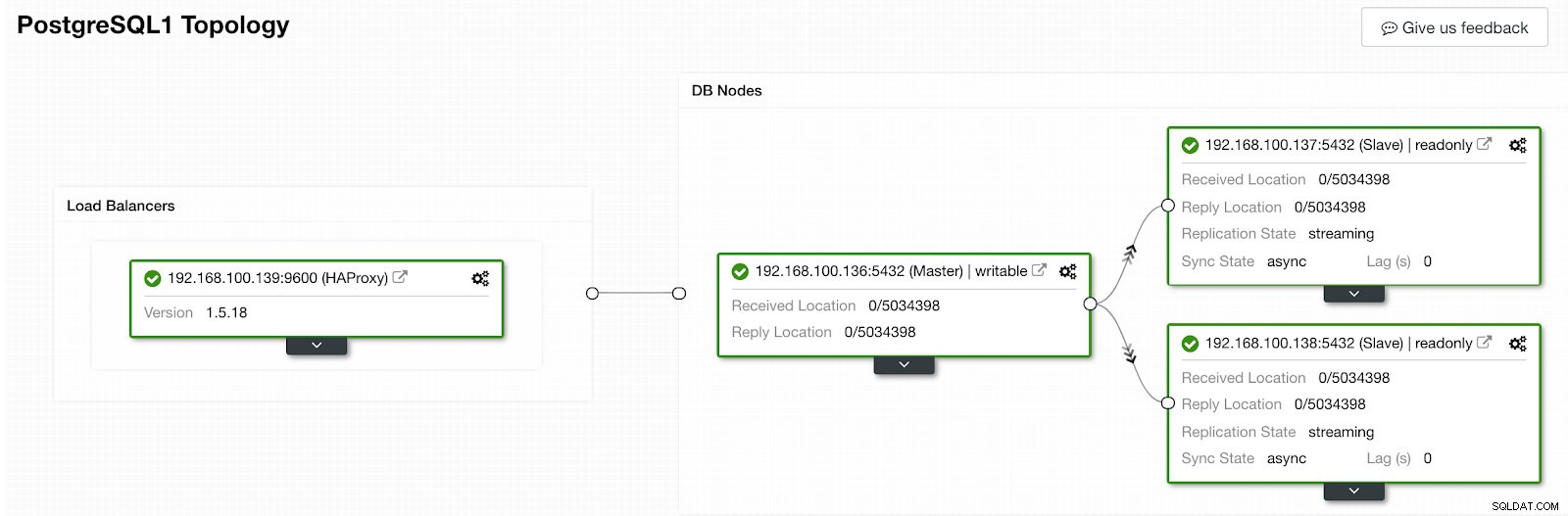 ClusterControl Topology View 2
ClusterControl Topology View 2 Vi kan förbättra vår HA-design genom att lägga till en ny HAProxy-nod och konfigurera Keepalved-tjänsten mellan dem. Allt detta kan utföras av ClusterControl. För mer information kan du kolla vår tidigare blogg om PostgreSQL och HA.
Använda ClusterControl CLI för att lägga till en HAProxy Load Balancer
Även känt som s9s-tools, detta valfria paket introducerades i ClusterControl version 1.4.1, som innehåller en binär som kallas s9s. Det är ett kommandoradsverktyg för att interagera, kontrollera och hantera din databasinfrastruktur med ClusterControl. s9s kommandoradsprojekt är öppen källkod och kan hittas på GitHub.
Från och med version 1.4.1 installerar installationsskriptet automatiskt paketet (s9s-tools) på ClusterControl-noden.
ClusterControl CLI öppnar en ny dörr för klusterautomation där du enkelt kan integrera den med befintliga automationsverktyg för distribution som Ansible, Puppet, Chef eller Salt.
Låt oss titta på ett exempel på hur man skapar en HAProxy-lastbalanserare med IP-adress 192.168.100.142 på kluster-ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Och sedan kan vi kontrollera alla våra noder från kommandoraden:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5För mer information om s9s och hur man använder den, kan du kontrollera den officiella dokumentationen eller detta hur man bloggar om detta ämne.
Slutsats
I den här bloggen har vi granskat hur HAProxy kan hjälpa oss att hantera trafiken som kommer från applikationen till vår PostgreSQL-databas. Vi kollade hur det kan distribueras och konfigureras manuellt och såg sedan hur det kan automatiseras med ClusterControl. För att undvika att HAProxy blir en enda felpunkt (SPOF), se till att du distribuerar minst två HAProxy-instanser och implementerar något som Keepalved och Virtual IP ovanpå dem.