Kunskap om replikering är ett måste för alla som hanterar databaser. Det är ett ämne som du förmodligen har sett om och om igen men som aldrig blir gammalt. I den här bloggen kommer vi att gå igenom lite av historien om PostgreSQL:s inbyggda replikeringsfunktioner och djupdyka i hur strömmande replikering fungerar.
När vi pratar om replikering kommer vi att prata mycket om WAL. Så låt oss snabbt gå igenom lite om skrivloggar.
Write-Ahead Log (WAL)
En Write-Ahead Log är en standardmetod för att säkerställa dataintegritet, och den är automatiskt aktiverad som standard.
WALs är REDO-loggarna i PostgreSQL. Men exakt vad är REDO-loggar?
REDO-loggar innehåller alla ändringar som gjorts i databasen och de används för replikering, återställning, onlinesäkerhetskopiering och punkt-i-tidsåterställning (PITR). Alla ändringar som inte har tillämpats på datasidorna kan göras om från REDO-loggarna.
Användning av WAL resulterar i ett avsevärt minskat antal diskskrivningar eftersom endast loggfilen behöver spolas till disken för att garantera att en transaktion genomförs, snarare än varje datafil som ändras av transaktionen.
En WAL-post kommer att specificera ändringarna som gjorts i data, bit för bit. Varje WAL-post kommer att läggas till i en WAL-fil. Infogningspositionen är ett Log Sequence Number (LSN), en byteförskjutning i loggarna, som ökar med varje ny post.
WALs lagras i pg_wal-katalogen (eller pg_xlog i PostgreSQL-versioner <10) under datakatalogen. Dessa filer har en standardstorlek på 16MB (du kan ändra storleken genom att ändra konfigurationsalternativet --with-wal-segsize när du bygger servern). De har ett unikt inkrementellt namn i följande format:"00000001 00000000 00000000".
Antalet WAL-filer som finns i pg_wal kommer att bero på värdet som tilldelas parametern checkpoint_segments (eller min_wal_size och max_wal_size, beroende på version) i postgresql.conf-konfigurationsfilen.
En parameter som du behöver ställa in när du konfigurerar alla dina PostgreSQL-installationer är wal_level. wal_level bestämmer hur mycket information som skrivs till WAL. Standardvärdet är minimalt, vilket bara skriver den information som behövs för att återhämta sig efter en krasch eller omedelbar avstängning. Arkiv lägger till loggning som krävs för WAL-arkivering; hot_standby lägger ytterligare till information som behövs för att köra skrivskyddade frågor på en standby-server; logical lägger till information som behövs för att stödja logisk avkodning. Den här parametern kräver en omstart, så det kan vara svårt att ändra på att köra produktionsdatabaser om du har glömt det.
För ytterligare information kan du kontrollera den officiella dokumentationen här eller här. Nu när vi har täckt WAL, låt oss granska historien om replikering i PostgreSQL.
Historia för replikering i PostgreSQL
Den första replikeringsmetoden (varm standby) som PostgreSQL implementerade (version 8.2, tillbaka 2006) baserades på metoden för loggsändning.
Detta betyder att WAL-posterna flyttas direkt från en databasserver till en annan för att tillämpas. Vi kan säga att det är en kontinuerlig PITR.
PostgreSQL implementerar filbaserad loggsändning genom att överföra WAL-poster en fil (WAL-segment) åt gången.
Denna replikeringsimplementering har nackdelen:om det finns ett stort fel på de primära servrarna kommer transaktioner som ännu inte har skickats att gå förlorade. Så det finns ett fönster för dataförlust (du kan ställa in detta genom att använda parametern archive_timeout, som kan ställas in på så lågt som några sekunder. En så låg inställning kommer dock att avsevärt öka den bandbredd som krävs för filsändning).
Vi kan representera denna filbaserade loggleveransmetod med bilden nedan:
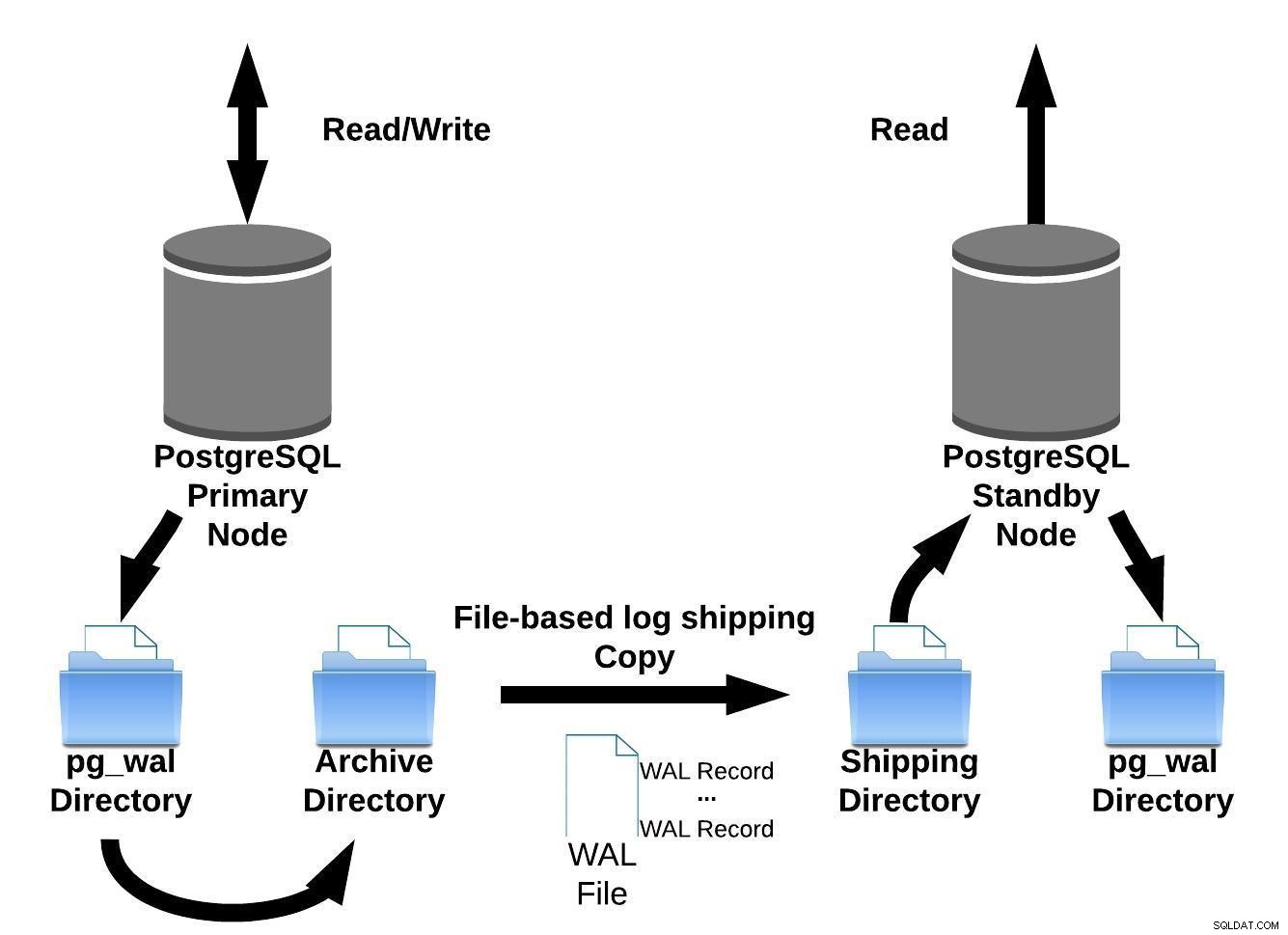 PostgreSQL-filbaserad loggsändning
PostgreSQL-filbaserad loggsändningDå, i version 9.0 (tillbaka 2010) ), introducerades strömmande replikering.
Streamande replikering gör att du kan hålla dig mer uppdaterad än vad som är möjligt med filbaserad loggsändning. Detta fungerar genom att överföra WAL-poster (en WAL-fil består av WAL-poster) i farten (rekordsbaserad loggsändning) mellan en primär server och en eller flera standby-servrar utan att vänta på att WAL-filen ska fyllas i.
I praktiken kommer en process som kallas WAL-mottagare, som körs på standby-servern, att ansluta till den primära servern med en TCP/IP-anslutning. På den primära servern finns en annan process, som heter WAL-avsändaren, och som ansvarar för att skicka WAL-registren till standbyservern när de händer.
Följande diagram representerar strömmande replikering:
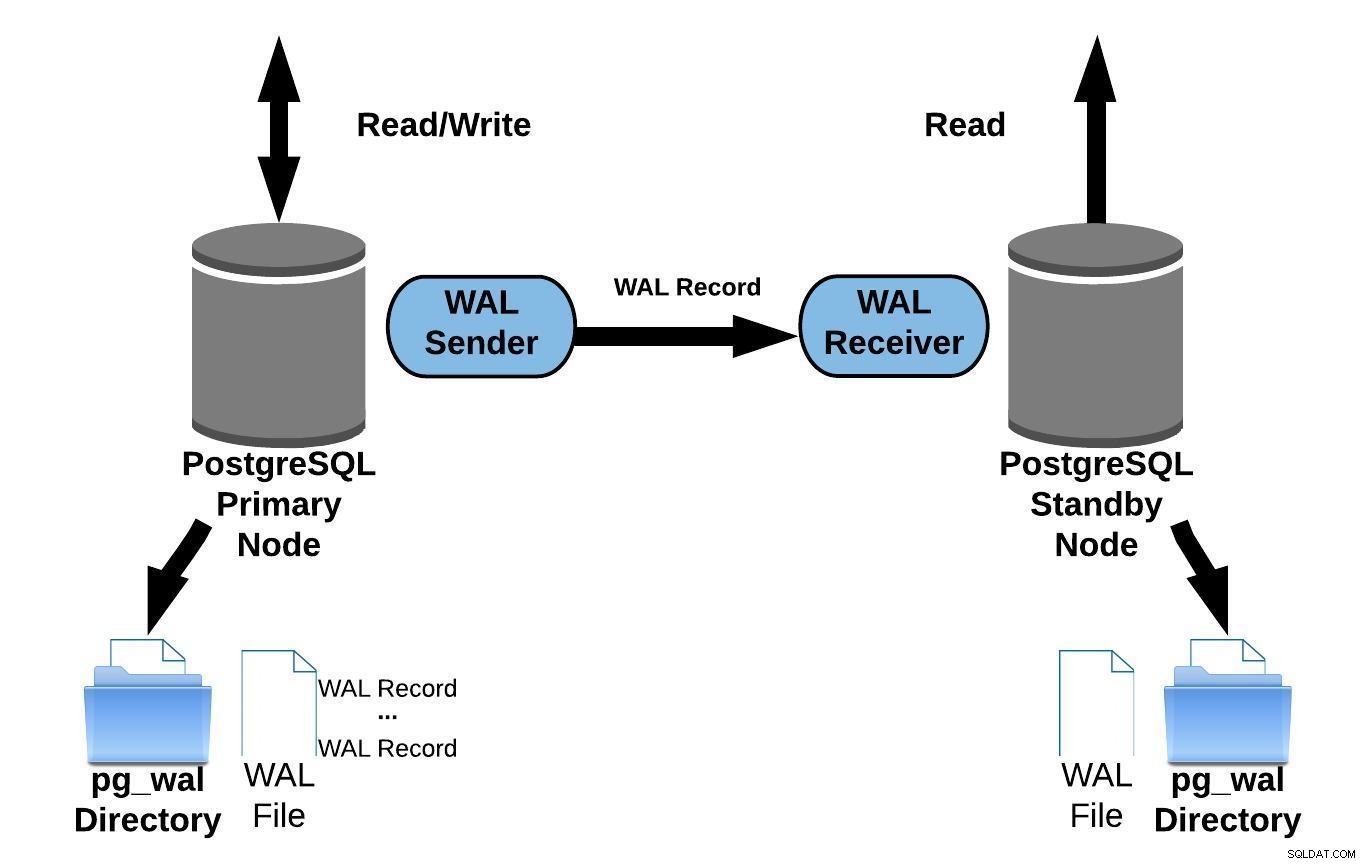 PostgreSQL Streaming-replikering
PostgreSQL Streaming-replikeringNär du tittar på diagrammet ovan kanske du undrar vad som händer när kommunikationen mellan WAL-sändaren och WAL-mottagaren misslyckas?
När du konfigurerar strömmande replikering har du möjlighet att aktivera WAL-arkivering.
Det här steget är inte obligatoriskt men är extremt viktigt för en robust replikeringsinställning. Det är nödvändigt att undvika att huvudservern återvinner gamla WAL-filer som ännu inte har applicerats på standbyservern. Om detta inträffar måste du återskapa repliken från början.
När du konfigurerar replikering med kontinuerlig arkivering, startar den från en säkerhetskopia. För att nå det synkroniserade tillståndet med den primära måste den tillämpa alla ändringar som finns i WAL som hände efter säkerhetskopieringen. Under denna process kommer vänteläget först att återställa all tillgänglig WAL på arkivplatsen (görs genom att anropa restore_command). Restore_command kommer att misslyckas när den når den senast arkiverade WAL-posten, så efter det kommer vänteläget att titta på pg_wal-katalogen för att se om ändringen finns där (detta fungerar för att undvika dataförlust när primärservrarna kraschar och vissa ändringar som har redan flyttats och tillämpats på repliken har ännu inte arkiverats).
Om det misslyckas och den begärda posten inte finns där, kommer den att börja kommunicera med den primära servern genom strömmande replikering.
När strömmande replikering misslyckas, går den tillbaka till steg 1 och återställer posterna från arkivet igen. Denna loop av återförsök från arkivet, pg_wal, och via strömmande replikering fortsätter tills servern stannar, eller failover utlöses av en triggerfil.
Följande diagram representerar en strömmande replikeringskonfiguration med kontinuerlig arkivering:
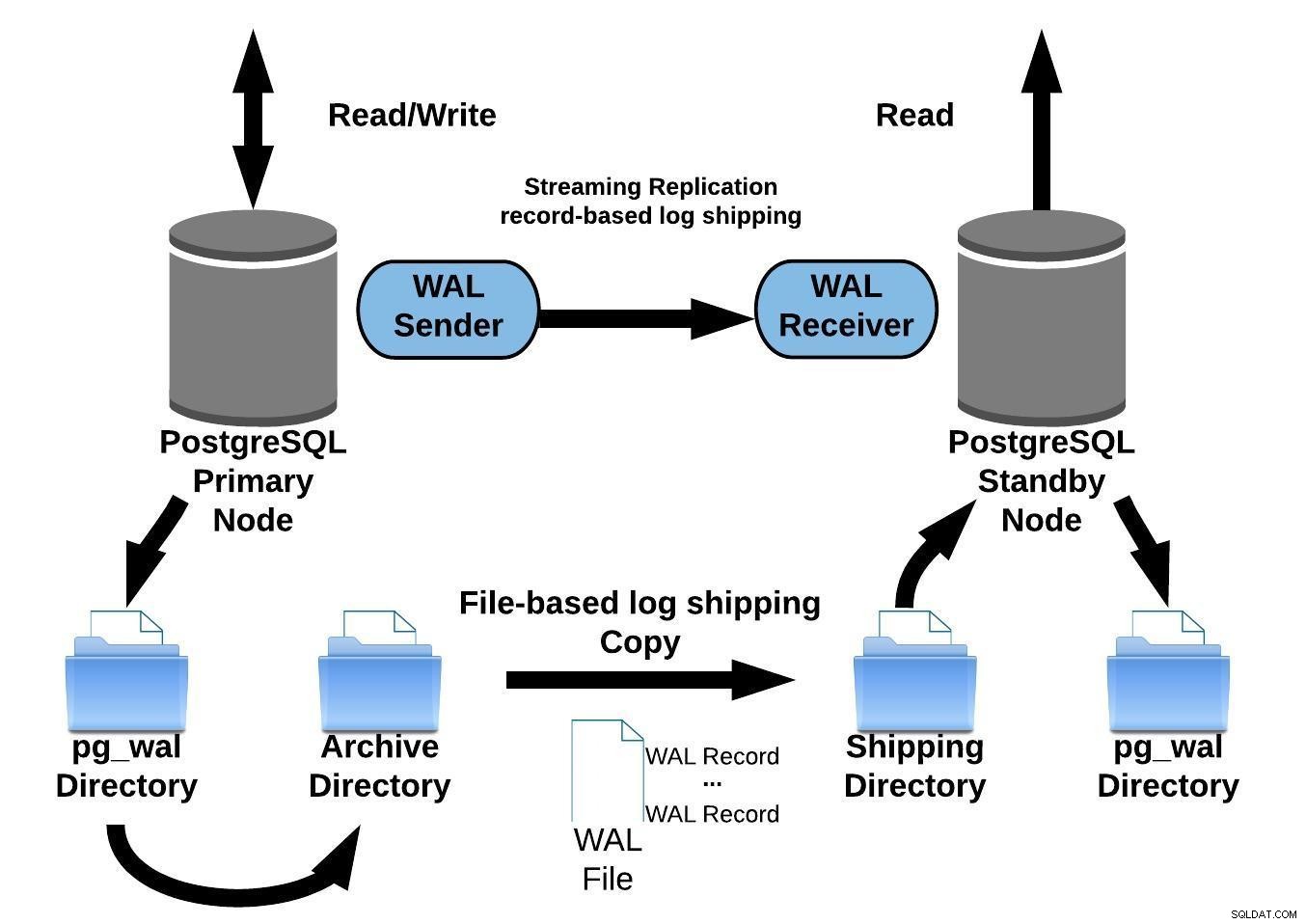 PostgreSQL strömmande replikering med kontinuerlig arkivering
PostgreSQL strömmande replikering med kontinuerlig arkiveringStrömmande replikering är asynkron som standard, så kl. När som helst kan du ha vissa transaktioner som kan överföras till den primära servern och ännu inte replikeras till standbyservern. Detta innebär en viss potentiell dataförlust.
Denna fördröjning mellan commit och påverkan av ändringarna i repliken ska dock vara väldigt liten (några millisekunder), givetvis förutsatt att replikservern är tillräckligt kraftfull för att hålla jämna steg med lasten.
För fall då risken för mindre dataförlust inte är acceptabel, introducerade version 9.1 funktionen för synkron replikering.
I synkron replikering väntar varje commit av en skrivtransaktion tills bekräftelse tas emot att commit skrivs till skriv-ahead-loggningen på disken för både den primära och standby-servern.
Denna metod minimerar risken för dataförlust; för att det ska hända behöver du att både den primära och vänteläget misslyckas samtidigt.
Den uppenbara nackdelen med denna konfiguration är att svarstiden för varje skrivtransaktion ökar, eftersom den måste vänta tills alla parter har svarat. Så, tiden för en commit är åtminstone en tur och retur mellan primär och replik. Skrivskyddade transaktioner kommer inte att påverkas av detta.
För att ställa in synkron replikering måste du ange ett application_name i primär_conninfo för återställningen för varje standby server.conf fil:primary_conninfo ='...aplication_name=standbyX' .
Du måste också ange listan över standby-servrar som kommer att delta i den synkrona replikeringen:synchronous_standby_name ='standbyX,standbyY'.
Du kan ställa in en eller flera synkrona servrar, och den här parametern anger också vilken metod (FÖRSTA och NÅGON) för att välja synkrona väntelägen från de listade. För mer information om hur du ställer in synkront replikeringsläge, kolla in den här bloggen. Det är också möjligt att ställa in synkron replikering vid distribution via ClusterControl.
När du har konfigurerat din replikering och den är igång måste du implementera övervakning
Övervaka PostgreSQL-replikering
Vyn pg_stat_replication på huvudservern har mycket relevant information:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Låt oss se detta i detalj:
-
pid:Process-id för walsenderprocessen.
-
usesysid:OID för användare som används för strömmande replikering.
-
användarnamn:Namn på användare som används för strömmande replikering.
-
application_name:Programnamn kopplat till master.
-
client_addr:Adress till standby-/strömningsreplikering.
-
client_hostname:Värdnamn för standby.
-
client_port:TCP-portnummer där standby kommunicerar med WAL-avsändare.
-
backend_start:Starttid när SR anslutit till Primary.
-
tillstånd:Aktuellt WAL-avsändartillstånd, d.v.s. streaming.
-
sent_lsn:Senaste transaktionsplatsen skickades till standby.
-
write_lsn:Senaste transaktionen skrevs på disken i vänteläge.
-
flush_lsn:Senaste transaktionsspolning på disk i vänteläge.
-
replay_lsn:Senaste transaktionsspolning på disk i vänteläge.
-
sync_priority:Prioritet för standbyserver vald som synkron standby.
-
sync_state:Synkronisera standbyläge (är det asynkront eller synkront).
Du kan också se WAL-sändar-/mottagarprocesserna som körs på servrarna.
Avsändare (primär nod):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Mottagare (väntelägesnod):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Ett sätt att kontrollera hur uppdaterad din replikering är, är att kontrollera mängden WAL-poster som genererats på den primära servern, men som ännu inte tillämpats i standby-servern.
Primär:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Standby:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Du kan använda följande fråga i standbynoden för att få eftersläpningen i sekunder:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Och du kan också se det senast mottagna meddelandet:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Övervaka PostgreSQL-replikering med ClusterControl
För att övervaka ditt PostgreSQL-kluster kan du använda ClusterControl, som låter dig övervaka och utföra flera ytterligare hanteringsuppgifter som distribution, säkerhetskopiering, utskalning och mer.
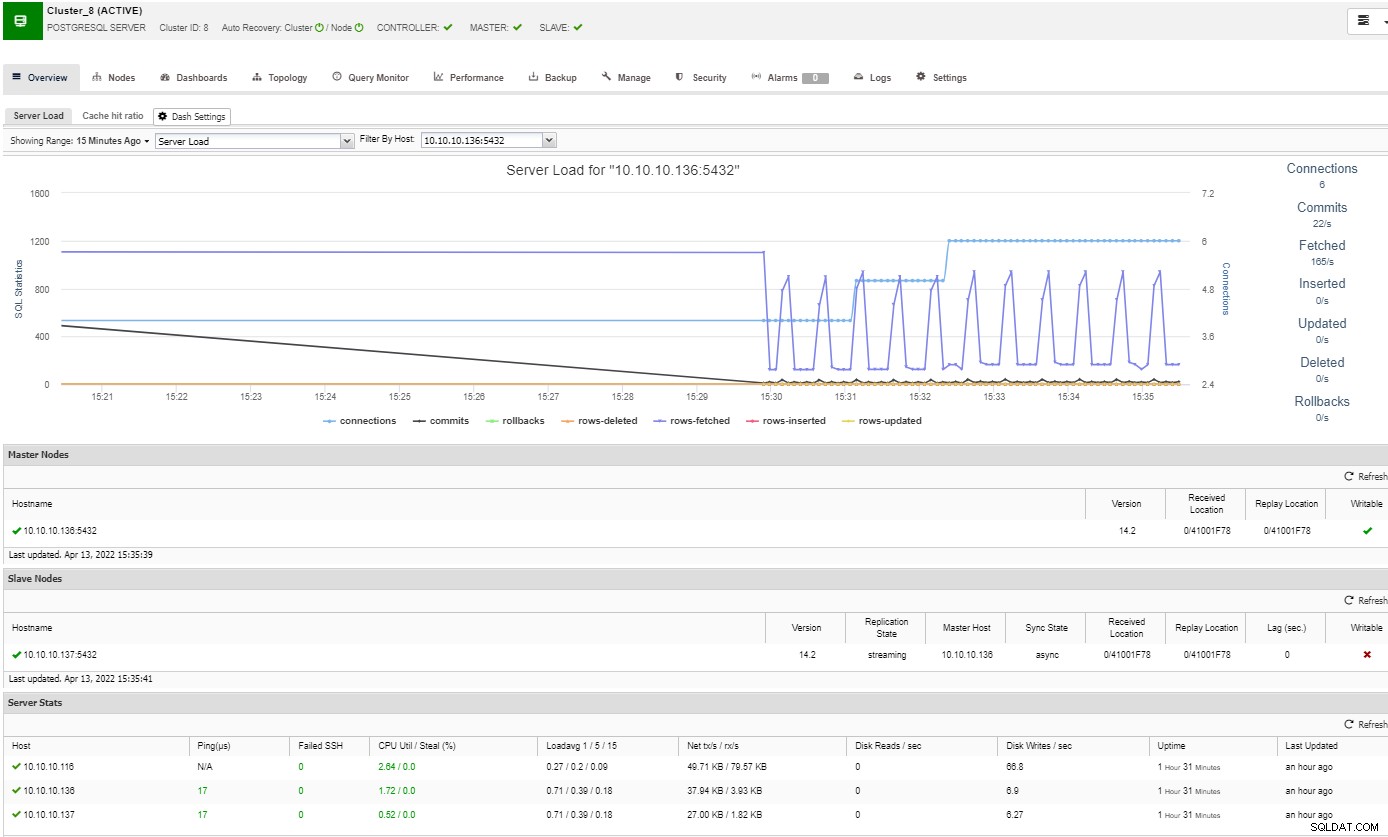
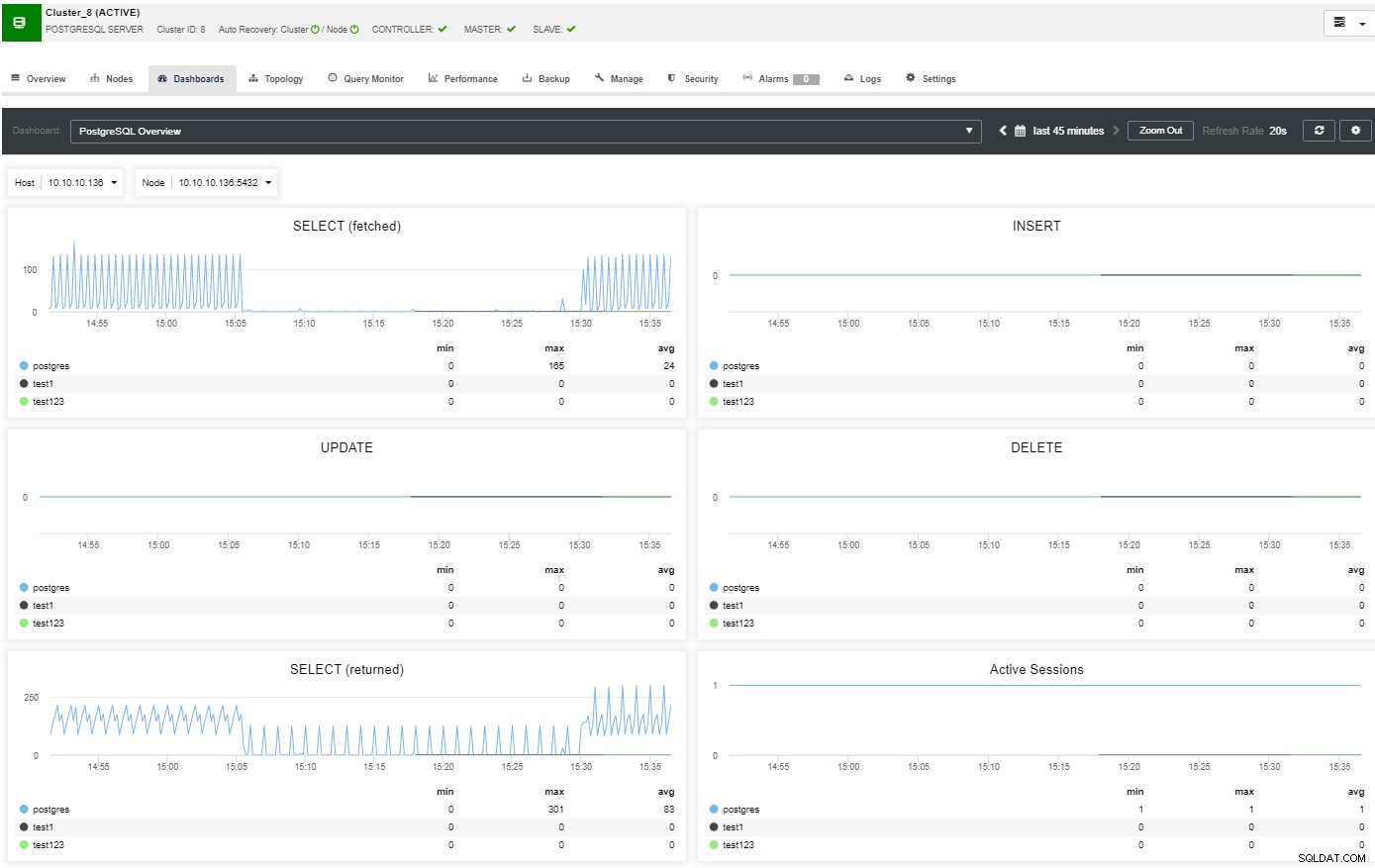
I översiktsavsnittet får du hela bilden av ditt databaskluster nuvarande status. För att se mer information kan du gå till instrumentpanelssektionen, där du kommer att se massor av användbar information uppdelad i olika diagram.
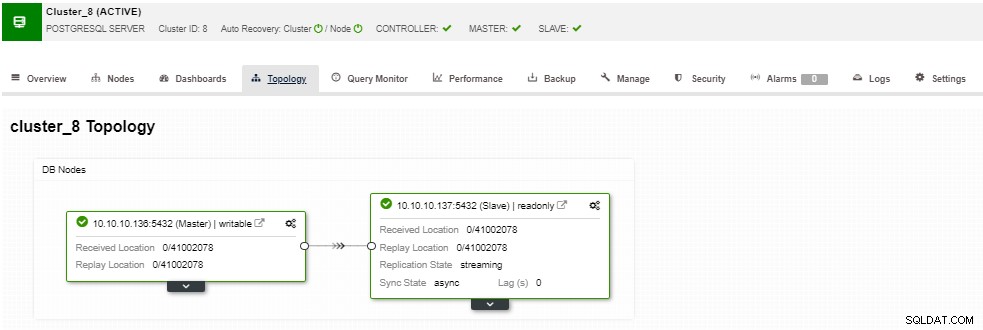
I topologisektionen kan du se din nuvarande topologi i en användar- vänligt sätt, och du kan också utföra olika uppgifter över noderna genom att använda knappen Nod Action.
Streamingreplikering är baserad på att skicka WAL-posterna och applicera dem i vänteläge server, den bestämmer vilka bytes som ska läggas till eller ändras i vilken fil. Som ett resultat är standby-servern faktiskt en bit-för-bit-kopia av den primära servern. Det finns dock några välkända begränsningar här:
-
Du kan inte replikera till en annan version eller arkitektur.
-
Du kan inte ändra något på standbyservern.
-
Du har inte mycket granularitet i vad du replikerar.
Så för att övervinna dessa begränsningar har PostgreSQL 10 lagt till stöd för logisk replikering
Logisk replikering
Logisk replikering kommer också att använda informationen i WAL-filen, men den kommer att avkoda den till logiska ändringar. Istället för att veta vilken byte som har ändrats kommer den att veta exakt vilken data som har infogats i vilken tabell.
Den är baserad på en "publicera" och "prenumerera"-modell med en eller flera prenumeranter som prenumererar på en eller flera publikationer på en utgivarnod som ser ut så här:
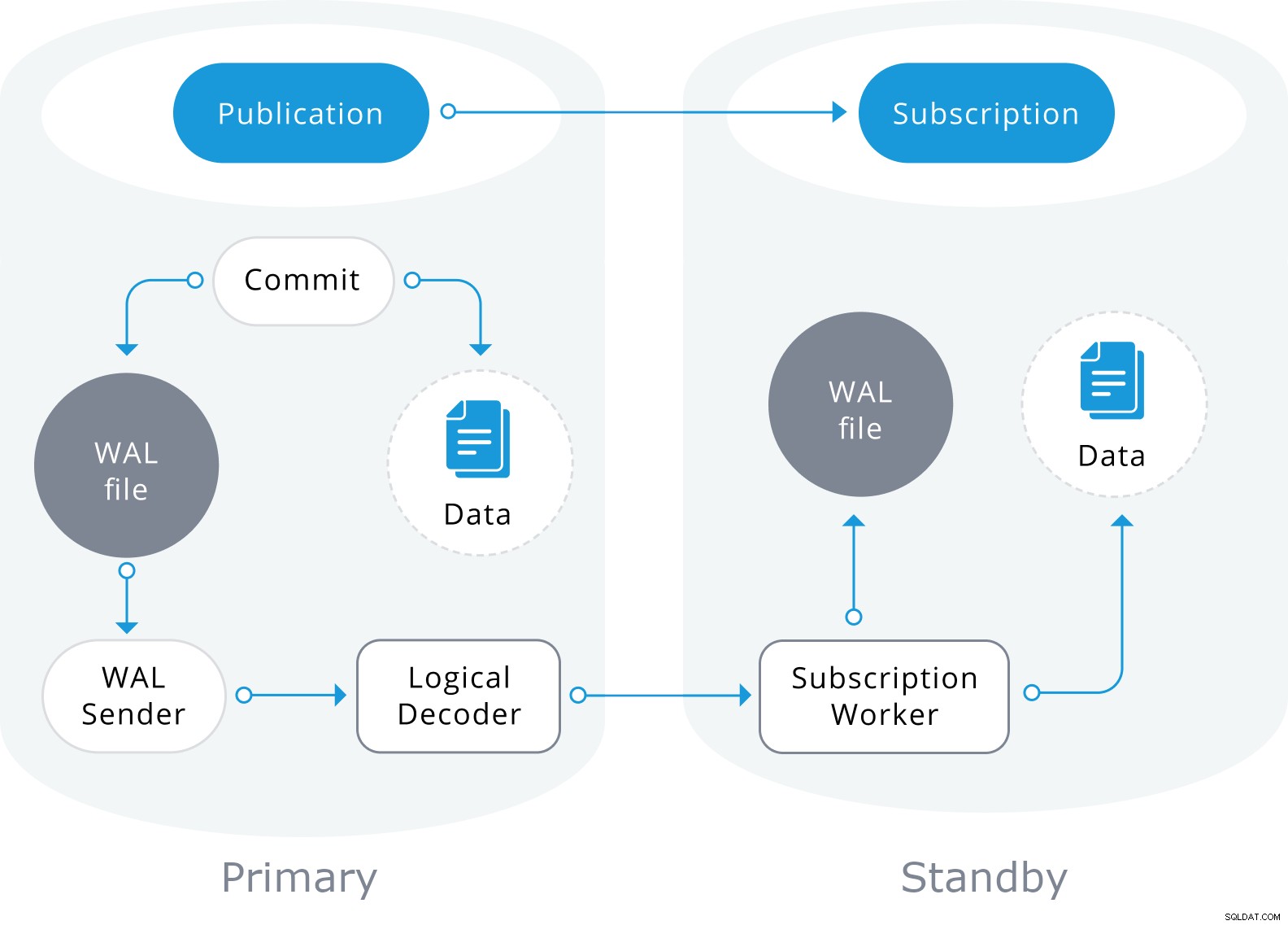
Avsluta
Med strömmande replikering kan du kontinuerligt skicka och tillämpa WAL-poster på dina standby-servrar, vilket säkerställer att information som uppdateras på den primära servern överförs till standby-servern i realtid, vilket gör att båda förblir synkroniserade .
ClusterControl gör det enkelt att konfigurera strömmande replikering och du kan utvärdera det gratis i 30 dagar.
Om du vill lära dig mer om logisk replikering i PostgreSQL, var noga med att kolla in den här översikten över logisk replikering och det här inlägget om bästa praxis för PostgreSQL-replikering.
För fler tips och bästa praxis för att hantera din öppen källkodsbaserad databas, följ oss på Twitter och LinkedIn och prenumerera på vårt nyhetsbrev för regelbundna uppdateringar.