Replikering spelar en avgörande roll för att upprätthålla hög tillgänglighet. Servrar kan misslyckas, operativsystemet eller databasprogramvaran kan behöva uppgraderas. Detta innebär att serverroller blandas om och replikeringslänkar flyttas, samtidigt som datakonsistensen bibehålls i alla databaser. Topologiändringar kommer att krävas, och det finns olika sätt att utföra dem.
Marknadsför en standby-server
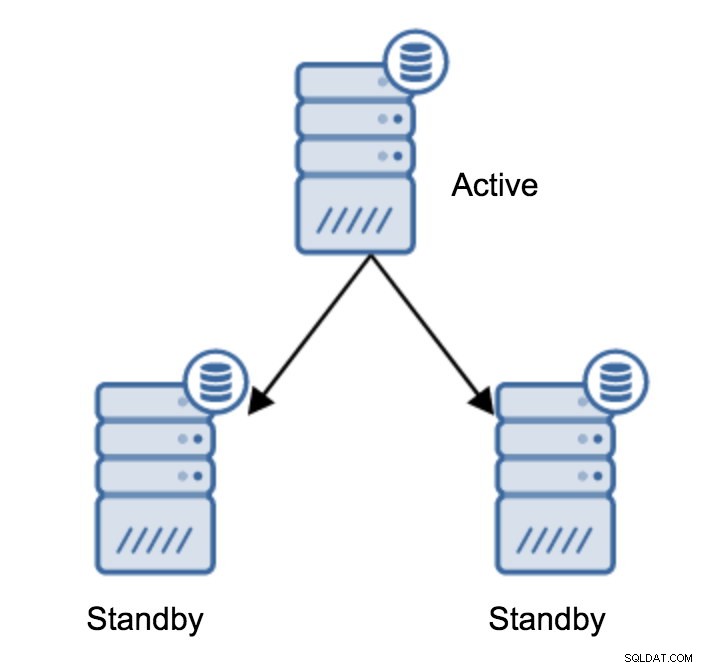
Förmodligen är detta den vanligaste operationen som du behöver utföra. Det finns flera skäl - till exempel databasunderhåll på den primära servern som skulle påverka arbetsbelastningen på ett oacceptabelt sätt. Det kan finnas planerade driftstopp på grund av vissa hårdvaruoperationer. Den primära servern kraschar vilket gör den oåtkomlig för applikationen. Dessa är alla skäl att utföra en failover, oavsett om den är planerad eller inte. I alla fall måste du marknadsföra en av standby-servrarna för att bli en ny primär server.
För att marknadsföra en standby-server måste du köra:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
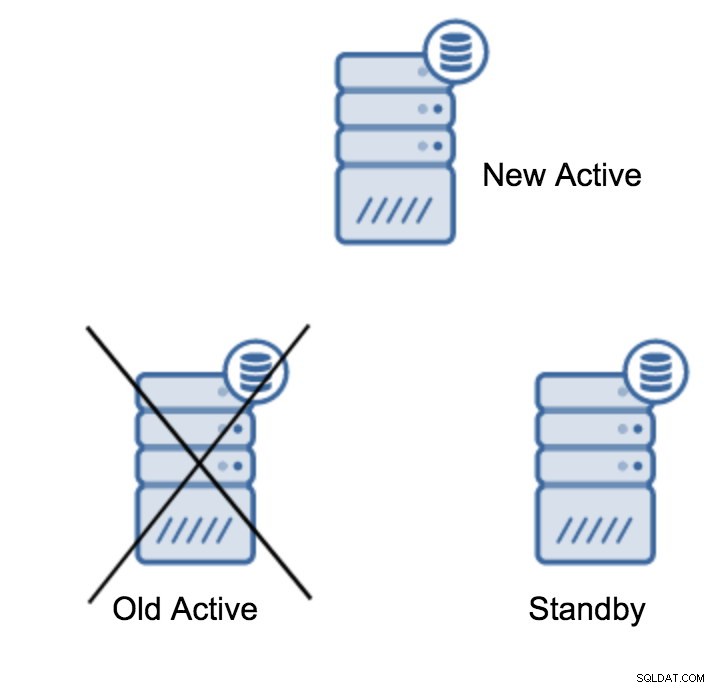
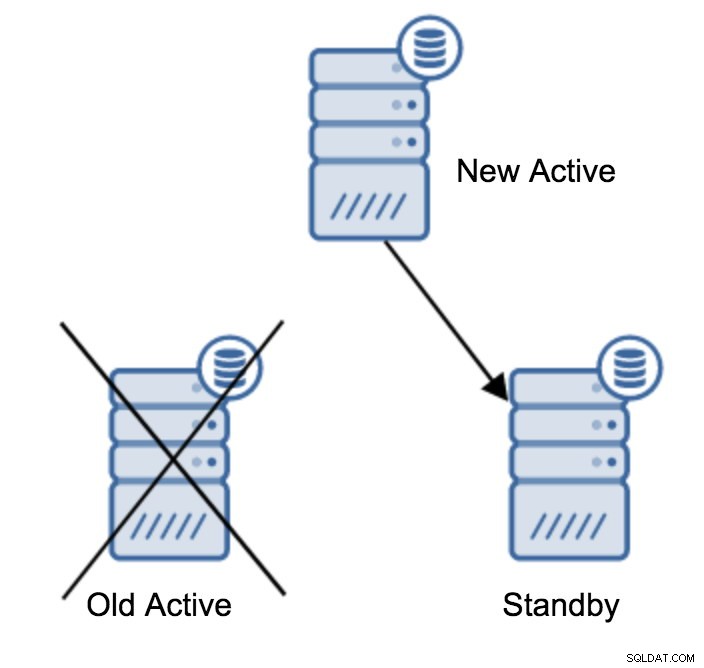
server promotedDet är lätt att köra det här kommandot, men se först till att för att undvika förlust av data. Om vi pratar om ett scenario med "primär server nere" kanske du inte har för många alternativ. Om det är ett planerat underhåll så går det att förbereda sig för det. Du måste stoppa trafiken på den primära servern och sedan verifiera att standbyservern tog emot och tillämpade all data. Detta kan göras på standby-servern med hjälp av frågan enligt nedan:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)När allt är bra kan du stoppa den gamla primära servern och marknadsföra standbyservern.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperSlavning av en standby-server från en ny primär server
Du kan ha mer än en standby-server som slavar av din primära server. När allt kommer omkring är standby-servrar användbara för att avlasta skrivskyddad trafik. Efter att ha marknadsfört en standby-server till en ny primär server, måste du göra något åt de återstående standby-servrarna som fortfarande är anslutna (eller som försöker ansluta) till den gamla primära servern. Tyvärr kan du inte bara ändra recovery.conf och ansluta dem till den nya primära servern. För att ansluta dem måste du först bygga om dem. Det finns två metoder du kan prova här:standardbasbackup eller pg_rewind.
Vi kommer inte in på detaljer om hur man tar en bassäkerhetskopiering - vi behandlade det i vårt tidigare blogginlägg, som fokuserade på att ta säkerhetskopior och återställa dem på PostgreSQL. Om du råkar använda ClusterControl kan du också använda det för att skapa en bassäkerhetskopiering:
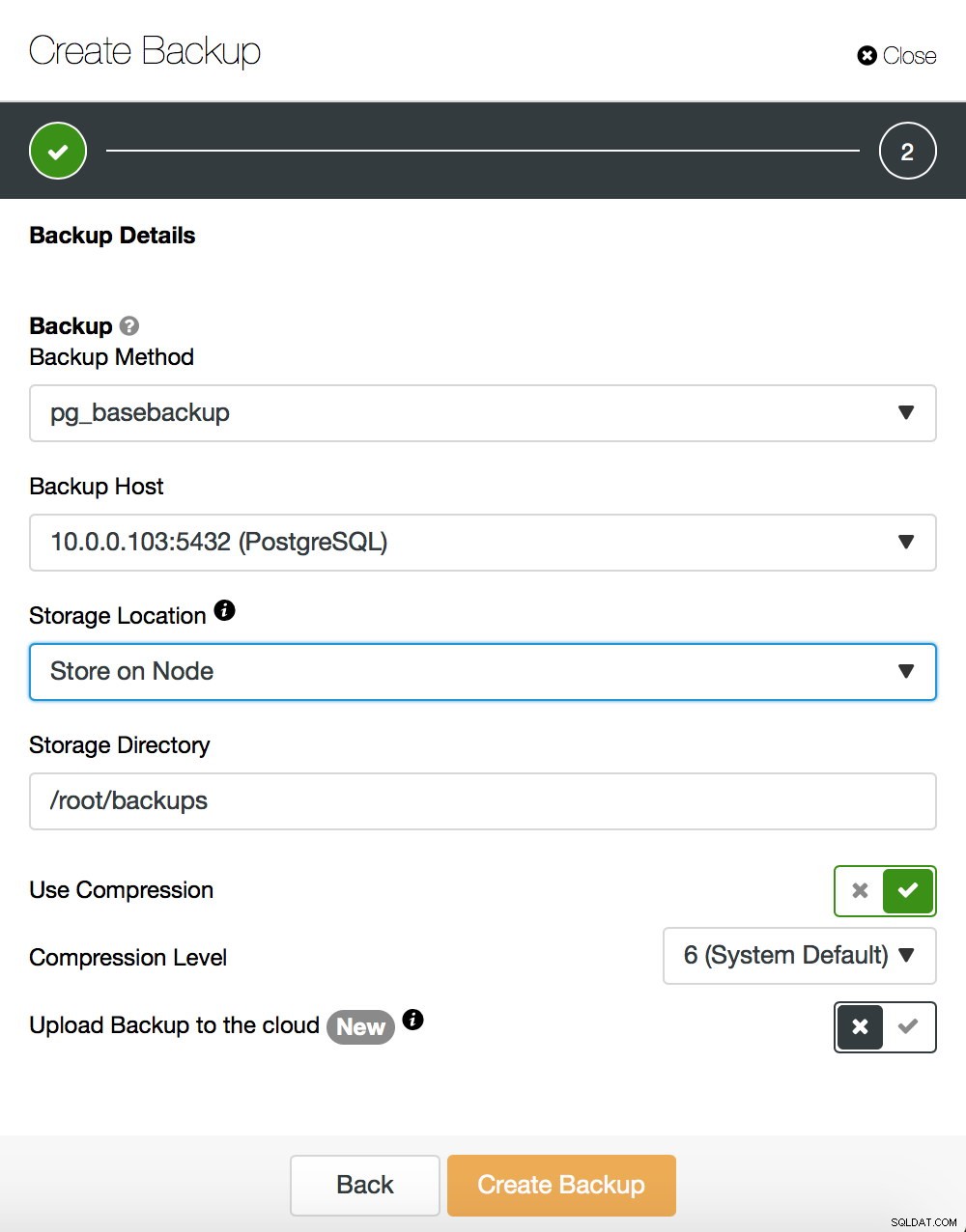
Å andra sidan, låt oss säga några ord om pg_rewind. Den största skillnaden mellan båda metoderna är att bassäkerhetskopieringen skapar en fullständig kopia av datamängden. Om vi pratar om små datamängder kan det vara ok men för dataset med hundratals gigabyte i storlek (eller ännu större) kan det snabbt bli ett problem. I slutändan vill du ha dina standbyservrar snabbt igång - för att ladda ner din aktiva server och ha ytterligare en standby att failover till, om det skulle behövas. Pg_rewind fungerar annorlunda - den kopierar bara de block som har modifierats. Istället för att kopiera allt kopierar den bara ändringar, vilket påskyndar processen ganska avsevärt. Låt oss anta att din nya master har en IP på 10.0.0.103. Så här kan du köra pg_rewind. Observera att du måste stoppa målservern - PostgreSQL kan inte köras där.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Detta kommer att göra en torrkörning , testar processen men gör inga ändringar. Om allt är bra är allt du behöver göra att köra det igen, denna gång utan parametern '--dry-run'. När det är gjort är det sista återstående steget att skapa en recovery.conf-fil, som pekar på den nya mastern. Det kan se ut så här:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Nu är du redo att starta din standby-server och den kommer att replikera från den nya aktiva servern.
Kedjig replikering
Det finns många anledningar till varför du kanske vill bygga en kedjad replikering, även om det vanligtvis görs för att minska belastningen på den primära servern. Att servera WAL till standby-servrar tillför en del overhead. Det är inte mycket av ett problem om du har en standby eller två, men om vi pratar om ett stort antal standby-servrar kan detta bli ett problem. Till exempel kan vi minimera antalet standbyservrar som replikerar direkt från den aktiva genom att skapa en topologi enligt nedan:
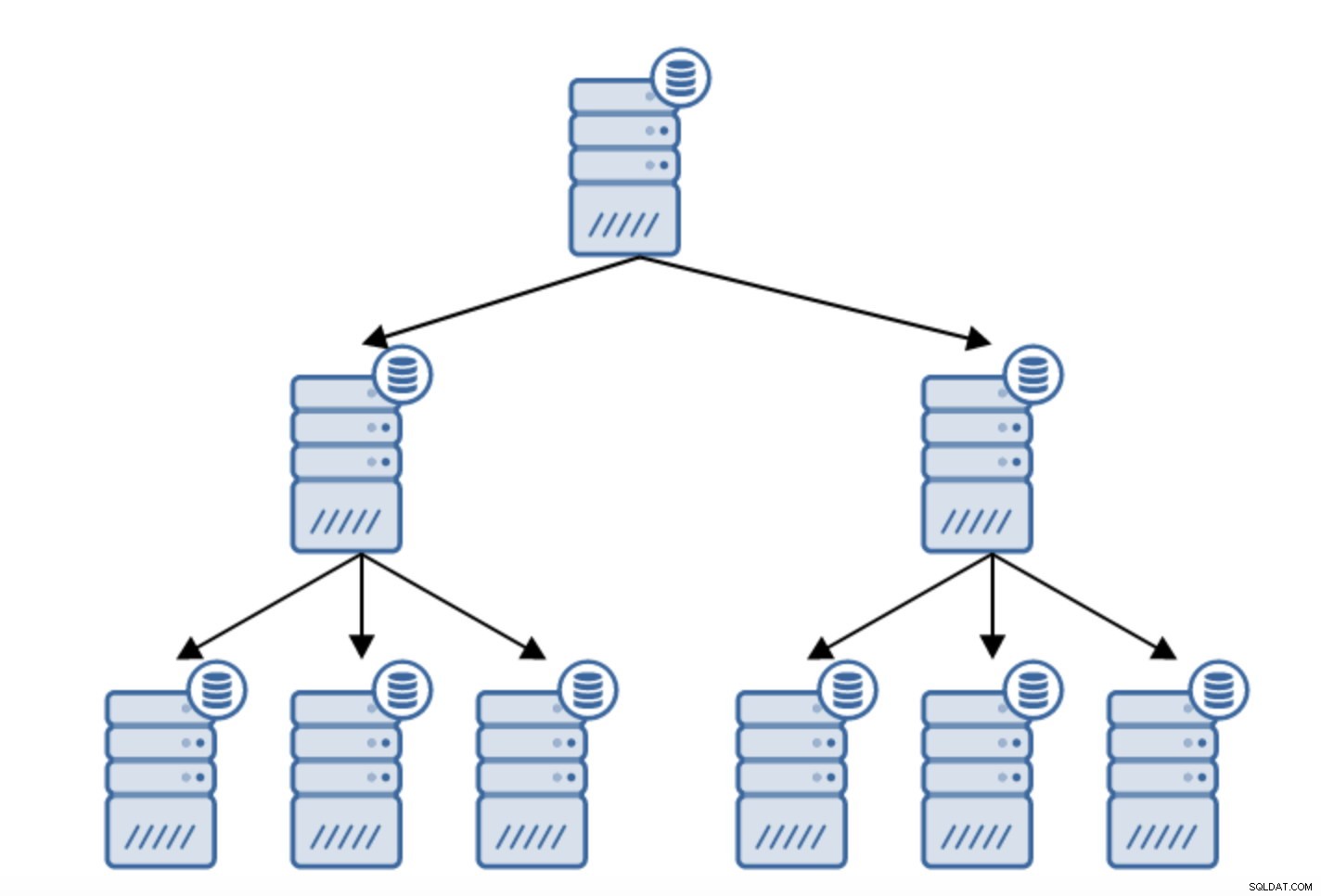
Övergången från en topologi med två standby-servrar till en kedjad replikering är ganska enkel.
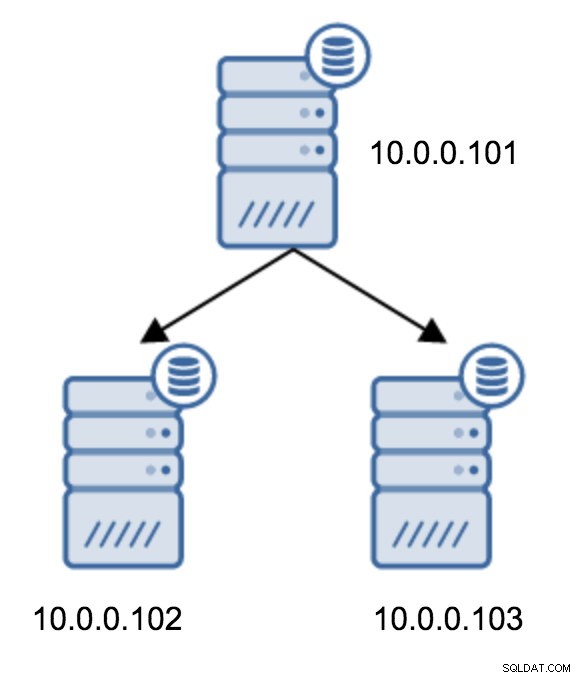
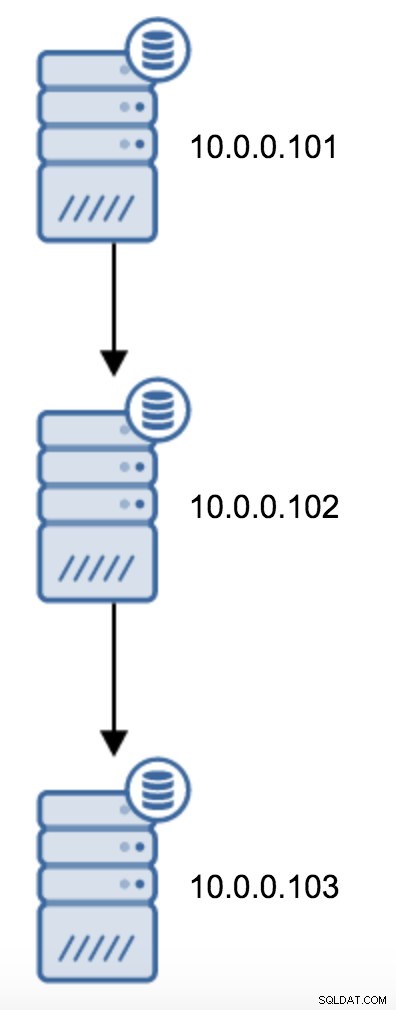
Du skulle behöva ändra recovery.conf på 10.0.0.103, rikta den mot 10.0.0.102 och sedan starta om PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Efter omstart bör 10.0.0.103 börja tillämpa WAL-uppdateringar.
Det här är några vanliga fall av topologiförändringar. Ett ämne som inte diskuterades, men som ändå är viktigt, är effekterna av dessa förändringar på ansökningarna. Vi tar upp det i ett separat inlägg, samt hur man gör dessa topologiändringar transparenta för applikationerna.