Varför tar det så mycket tid att köra en fråga? Varför finns det inga index? Chansen är stor att du har hört talas om EXPLAIN i PostgreSQL. Men det finns fortfarande många människor som inte har en aning om hur man använder det. Jag hoppas att den här artikeln kommer att hjälpa användare att ta itu med detta fantastiska verktyg.
Den här artikeln är författarens revision av Understanding EXPLAIN av Guillaume Lelarge. Eftersom jag har missat en del information rekommenderar jag starkt att du bekantar dig med originalet.
Djävulen är inte så svart som han är målad
Det är viktigt att förstå logiken i PostgreSQL-kärnan för att optimera frågor. Jag ska försöka förklara. Det är verkligen inte så komplicerat.
EXPLAIN visar nödvändig information som förklarar vad kärnan gör för varje specifik fråga.
Låt oss ta en titt på vad EXPLAIN-kommandot visar och förstå exakt vad som händer inuti PostgreSQL. Du kan tillämpa denna information på PostgreSQL 9.2 och högre versioner.
Våra uppgifter:
- Lär dig hur du läser och förstår resultatet av kommandot EXPLAIN
- Förstå vad som händer i PostgreSQL när en fråga exekveras
Första stegen
Vi kommer att öva på ett testbord med en miljon rader.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Försök att läsa informationen
EXPLAIN SELECT * FROM foo;
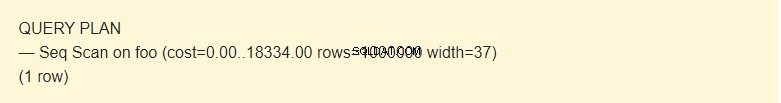
Det är möjligt att läsa data från en tabell på flera sätt. I vårt fall meddelar EXPLAIN att en Seq Scan används — en sekventiell, block-för-block, läs Foo-tabelldata.
Vad är kostnad ?
Tja, det är inte en tid, utan ett koncept utformat för att uppskatta kostnaden för en operation. Det första värdet 0,00 är kostnaderna för att få den första raden. Det andra värdet 18334,00 är kostnaderna för att få alla rader.
Rader är det ungefärliga antalet rader som returneras när en Seq Scan-operation utförs. Schemaläggaren returnerar detta värde. I mitt fall matchar det det faktiska antalet rader i tabellen.
Bredd är en genomsnittlig storlek på en rad i byte.
Låt oss försöka lägga till 10 rader.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Värdet på rader har inte ändrats. Tabellens statistik är gammal. För att uppdatera statistiken, anrop kommandot ANALYSE.
Nu, rader visa korrekt antal rader.
Vad händer när man kör ANALYS?
- Slumpmässigt väljs ett antal rader och läses från tabellen.
- Statistiken för värden för varje kolumn samlas in.
Antalet rader ANALYZE läser beror på parametern default_statistics_target.
Faktisk data
Allt vi såg ovan i utgången av kommandot EXPLAIN är vad planeraren förväntar sig att få. Låt oss försöka jämföra dem med resultaten på faktiska data. För att göra detta, använd EXPLAIN (ANALYSE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

En sådan fråga kommer verkligen att utföras. Så om du kör EXPLAIN (ANALYSE) för INSERT-, DELETE- eller UPDATE-satserna kommer dina data att ändras. Var försiktig! I dessa fall använder du kommandot ROLLBACK.
Kommandot visar följande ytterligare parametrar:
- faktisk tid är den faktiska tid i millisekunder som går åt för att få den första raden respektive alla rader.
- rader är det faktiska antalet rader som tagits emot med Seq Scan.
- slingor är antalet gånger Seq Scan-operationen behövde utföras.
- Total körtid är den totala tiden för utförande av en fråga.
Mer läsning:
Frågeoptimering i PostgreSQL. FÖRKLARA Grunderna – Del 2
Frågeoptimering i PostgreSQL. FÖRKLARA Grunderna – Del 3