Jag fortsätter en serie artiklar om grunderna i EXPLAIN i PostgreSQL, som är en kort recension av Understanding EXPLAIN av Guillaume Lelarge.
För att bättre förstå problemet rekommenderar jag starkt att du granskar originalet "Understanding EXPLAIN" av Guillaume Lelarge och läs mina första och andra artiklar.
BESTÄLL AV
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Först utför du en sekventiell skanning (Seq Scan) av foo-tabellen och gör sedan sorteringen (Sortera). Tecknet -> för kommandot EXPLAIN indikerar hierarkin av steg (nod). Ju tidigare steget utförs, desto större indrag har det.
Sorteringsnyckel är ett villkor för sortering.
Sorteringsmetod:extern sammanfogning Disk en temporär fil på disken med en kapacitet på 4592 kB används vid sortering.
Kontrollera med alternativet BUFFARE:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
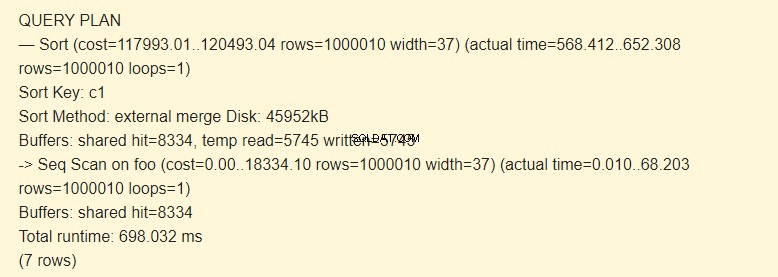
Faktum är att raden temp read=5745 written=5745 betyder att 45960Kb (5745 block om 8 Kb vardera) lagrades och lästes i den temporära filen. Operationerna med 8334 block utfördes i cachen.
Operationerna med filsystemet är långsammare än operationer i RAM.
Låt oss försöka öka minneskapaciteten för work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Sorteringsmetod:quicksort Minne:102702kB – hela sorteringen utfördes i RAM.
Indexet är som följer:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Vi har bara Index Scan kvar, vilket avsevärt påverkade sökhastigheten.
LIMIT
Ta bort det tidigare skapade indexet:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Som förväntat används Seq Scan och Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan läser rader i tabellen och jämför dem (Filter) med villkoret. Så snart det finns 10 poster som uppfyller villkoret kommer skanningen att avslutas. I vårt fall, för att få 10 resultatrader, behövde vi bara läsa 3063 poster snarare än hela tabellen. 3053 rader av detta nummer avvisades (rader togs bort med filter).
Detsamma händer med Index Scan.
GÅ MED
Skapa en ny tabell och generera statistik för den:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Frågan för två tabeller är följande:
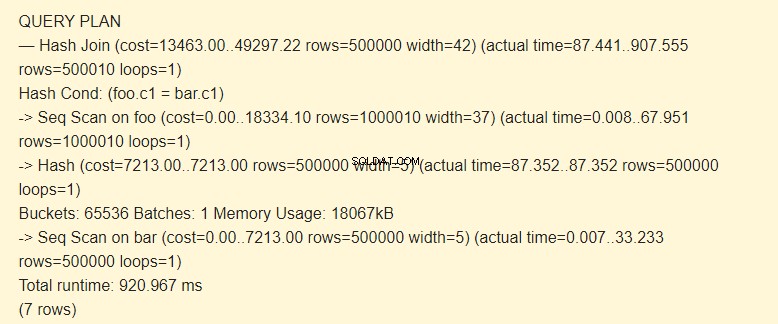
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Först läser sekventiell scan (Seq Scan) stapeltabellen. En hash (hash) beräknas för varje rad.
Sedan skannar den foo-tabellen och för varje rad beräknas en hash som jämförs (Hash Join) med hash för stapeltabellen av Hash Cond-villkoret. Om de matchar, matas en resulterande sträng ut.
18067 kB minne används för att lagra hash för baren.
Lägg till indexet:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash används inte längre. Merge Join och Index Scan på indexen i båda tabellerna förbättrar prestandan avsevärt.
LEFT JOIN:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
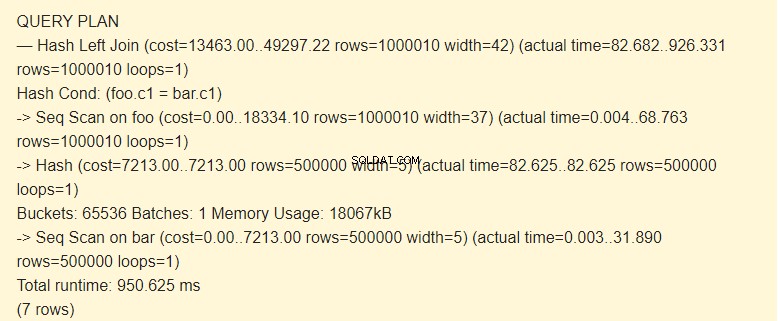
Seq Scan?
Låt oss se vilket resultat vi kommer att få om vi inaktiverar Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Enligt schemaläggaren är det dyrare att använda index än att använda hash. Detta är möjligt med en tillräckligt stor mängd tilldelat minne. Kommer du ihåg att vi ökade work_mem?
Men om du inte har tillräckligt med minne kommer schemaläggaren att bete sig annorlunda:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Om vi inaktiverar Index Scan, vilket resultat kommer EXPLAIN att visas?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
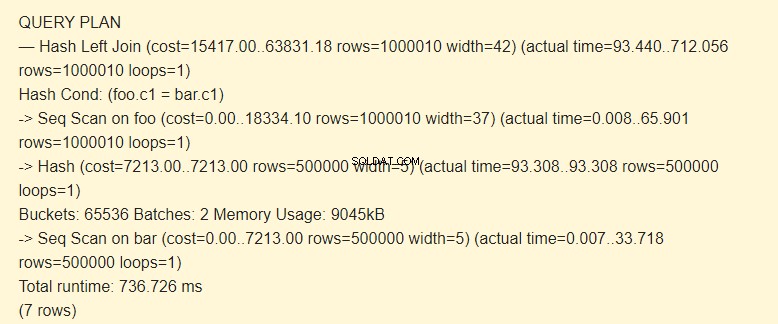
Partier:2 har ökat kostnaden. Hela hashen fick inte plats i minnet; vi var tvungna att dela upp den i två paket på 9045 kB.
Tack för att du läser mina artiklar! Jag hoppas att de var användbara. Om du har några kommentarer eller feedback får du gärna höra av dig.