Den här artikeln är den tolfte delen i en serie om namngivna tabelluttryck. Hittills har jag täckt härledda tabeller och CTE:er, som är namngivna tabelluttryck med satsomfattning, och vyer, som är återanvändbara namngivna tabelluttryck. Den här månaden introducerar jag inline-tabellvärderade funktioner, eller iTVFs, och beskriver deras fördelar jämfört med de andra namngivna tabelluttrycken. Jag jämför dem också med lagrade procedurer, främst med fokus på skillnader när det gäller standardoptimeringsstrategi, och planera cachning och återanvändningsbeteende. Det finns mycket att täcka när det gäller optimering, så jag börjar diskussionen den här månaden och fortsätter nästa månad.
I mina exempel kommer jag att använda en exempeldatabas som heter TSQLV5. Du kan hitta skriptet som skapar och fyller det här och dess ER-diagram här.
Vad är en inline-tabellvärderad funktion?
Jämfört med de tidigare täckta namngivna tabelluttrycken, liknar iTVFs mestadels vyer. Liksom vyer skapas iTVFs som ett permanent objekt i databasen och kan därför återanvändas av användare som har behörighet att interagera med dem. Den största fördelen iTVFs har jämfört med vyer är det faktum att de stöder indataparametrar. Så det enklaste sättet att beskriva en iTVF är som en parametriserad vy, även om du tekniskt sett skapar den med en CREATE FUNCTION-sats och inte med en CREATE VIEW-sats.
Det är viktigt att inte blanda ihop iTVFs med multi-statement table-valued functions (MSTVFs). Det förra är ett inlinerbart namngivet tabelluttryck baserat på en enda fråga som liknar en vy och är i fokus för den här artikeln. Den senare är en programmatisk modul som returnerar en tabellvariabel som dess utdata, med ett flöde av flera påståenden i kroppen vars syfte är att fylla den returnerade tabellvariabeln med data.
Syntax
Här är T-SQL-syntaxen för att skapa en iTVF:
SKAPA [ ELLER ÄNDRA ] FUNKTION [[ () ]
RETURBORD
[ MED
SOM
RETURNERA
Observera i syntaxen möjligheten att definiera indataparametrar.
Syftet med SCHEMABIDNING-attributet är detsamma som med vyer och bör utvärderas utifrån liknande överväganden. För detaljer, se del 10 i serien.
Ett exempel
Som ett exempel för en iTVF, anta att du behöver skapa ett återanvändbart namngivet tabelluttryck som accepterar som indata ett kund-ID (@custid) och ett nummer (@n) och returnerar det begärda antalet senaste beställningar från tabellen Sales.Orders för ingångskunden.
Du kan inte implementera den här uppgiften med en vy eftersom vyer saknar stöd för indataparametrar. Som nämnts kan du tänka på en iTVF som en parametriserad vy, och som sådan är det rätt verktyg för denna uppgift.
Innan du implementerar själva funktionen, här är kod för att skapa ett stödjande index i tabellen Sales.Orders:
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
Och här är koden för att skapa funktionen, som heter Sales.GetTopCustOrders:
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Precis som med bastabeller och vyer, när du är ute efter att ha hämtat data, anger du iTVFs i FROM-satsen i en SELECT-sats. Här är ett exempel på de tre senaste beställningarna för kund 1:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
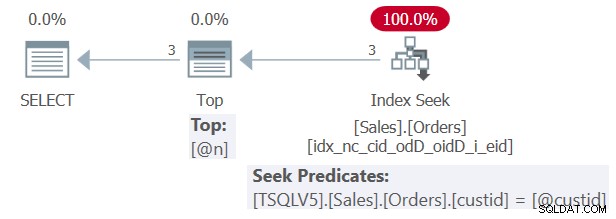
Jag hänvisar till det här exemplet som fråga 1. Planen för fråga 1 visas i figur 1.
 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Vad är inline med iTVFs?
Om du undrar över källan till termen inline i inline-tabellvärderade funktioner har det att göra med hur de blir optimerade. Inlining-konceptet är tillämpligt på alla fyra typer av namngivna tabelluttryck som T-SQL stöder, och involverar delvis vad jag beskrev i del 4 i serien som unnesting/substitution. Se till att du återvänder till det relevanta avsnittet i del 4 om du behöver en uppfräschning.
Som du kan se i figur 1, tack vare det faktum att funktionen blev infogade, kunde SQL Server skapa en optimal plan som interagerar direkt med den underliggande bastabellens index. I vårt fall utför planen en sökning i det stödjande indexet som du skapade tidigare.
iTVFs tar inlining-konceptet ett steg längre genom att tillämpa parameterinbäddningsoptimering som standard. Paul White beskriver parameterinbäddningsoptimering i sin utmärkta artikel Parameter Sniffing, Embedding, and the RECOMPILE Options. Med parameterinbäddningsoptimering ersätts frågeparameterreferenser med de bokstavliga konstantvärdena från den aktuella exekveringen, och sedan optimeras koden med konstanterna.
Observera i planen i figur 1 att både sökpredikatet för Indexsökoperatorn och topputtrycket för topoperatorn visar de inbäddade bokstavliga konstantvärdena 1 och 3 från den aktuella frågekörningen. De visar inte parametrarna @custid respektive @n.
Med iTVF:er används parameterinbäddningsoptimering som standard. Med lagrade procedurer optimeras parametriserade frågor som standard. Du måste lägga till OPTION(RECOMPILE) till en lagrad procedurs fråga för att begära optimering av parameterinbäddning. Mer information om optimering av iTVFs kontra lagrade procedurer, inklusive implikationer, inom kort.
Ändra data genom iTVFs
Minns från del 11 i serien att så länge som vissa krav är uppfyllda kan namngivna tabelluttryck vara ett mål för modifieringssatser. Denna förmåga gäller för iTVFs på samma sätt som den gäller för visningar. Till exempel, här är koden du kan använda för att ta bort de tre senaste beställningarna från kund 1 (kör faktiskt inte detta):
DELETE FROM Sales.GetTopCustOrders(1, 3);
Specifikt i vår databas skulle ett försök att köra den här koden misslyckas på grund av upprätthållande av referensintegritet (de berörda beställningarna råkar ha relaterade orderrader i tabellen Sales.OrderDetails), men det är giltig och stödd kod.
iTVFs kontra lagrade procedurer
Som nämnts tidigare är standardfrågeoptimeringsstrategin för iTVF:er annorlunda än den för lagrade procedurer. Med iTVF är standardinställningen att använda parameterinbäddningsoptimering. Med lagrade procedurer är standarden att optimera parametriserade frågor samtidigt som parametersniffning tillämpas. För att få parameterinbäddning för en lagrad procedurfråga måste du lägga till OPTION(RECOMPILE).
Som med många optimeringsstrategier och -tekniker har parameterinbäddning sina plus- och minus.
Det största pluset är att det möjliggör förenklingar av frågor som ibland kan resultera i mer effektiva planer. Några av dessa förenklingar är verkligen fascinerande. Paul visar detta med lagrade procedurer i sin artikel, och jag kommer att visa detta med iTVFs nästa månad.
Det största minuset med optimering av parameterinbäddning är att du inte får effektiv plancaching och återanvändningsbeteende som du gör för parametriserade planer. Med varje distinkt kombination av parametervärden får du en distinkt frågesträng, och därmed en separat kompilering som resulterar i en separat cachad plan. Med iTVFs med konstanta ingångar kan du få planåteranvändningsbeteende, men bara om samma parametervärden upprepas. Uppenbarligen kommer en lagrad procedurfråga med OPTION(RECOMPILE) inte att återanvända en plan även när samma parametervärden upprepas, på begäran.
Jag ska visa tre fall:
- Återanvändbara planer med konstanter som härrör från standardparameterinbäddningsoptimering för iTVF-frågor med konstanter
- Återanvändbara parametriserade planer som är resultatet av standardoptimeringen av parameteriserade lagrade procedurfrågor
- Ej återanvändbara planer med konstanter som är resultatet av parameterinbäddningsoptimering för lagrade procedurfrågor med OPTION(RECOMPILE)
Låt oss börja med fall #1.
Använd följande kod för att fråga vår iTVF med @custid =1 och @n =3:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Som en påminnelse skulle detta vara den andra exekveringen av samma kod eftersom du redan körde den en gång med samma parametervärden tidigare, vilket resulterar i planen som visas i figur 1.
Använd följande kod för att fråga iTVF med @custid =2 och @n =3 en gång:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
Jag hänvisar till den här koden som fråga 2. Planen för fråga 2 visas i figur 2.
 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
Kom ihåg att planen i figur 1 för fråga 1 hänvisade till det konstanta kund-ID 1 i sökpredikatet, medan denna plan hänvisar till det konstanta kund-ID 2.
Använd följande kod för att undersöka exekveringsstatistik:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
Denna kod genererar följande utdata:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
Det finns två separata planer skapade här:en för frågan med kund-ID 1, som användes två gånger, och en annan för frågan med kund-ID 2, som användes en gång. Med ett mycket stort antal distinkta kombinationer av parametervärden kommer du att få ett stort antal sammanställningar och cachade planer.
Låt oss fortsätta med fall #2:standardoptimeringsstrategin för parameteriserade lagrade procedurfrågor. Använd följande kod för att kapsla in vår fråga i en lagrad procedur som heter Sales.GetTopCustOrders2:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Använd följande kod för att utföra den lagrade proceduren med @custid =1 och @n =3 två gånger:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Den första exekveringen utlöser optimeringen av frågan, vilket resulterar i den parametriserade planen som visas i figur 3:
 Figur 3:Plan för försäljning.GetTopCustOrders2 proc
Figur 3:Plan för försäljning.GetTopCustOrders2 proc
Observera referensen till parametern @custid i sökpredikatet och till parametern @n i det översta uttrycket.
Använd följande kod för att utföra den lagrade proceduren med @custid =2 och @n =3 en gång:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Den cachade parametriserade planen som visas i figur 3 återanvänds igen.
Använd följande kod för att undersöka exekveringsstatistik:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Denna kod genererar följande utdata:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Endast en parametriserad plan skapades och cachelagrades och användes tre gånger, trots de ändrade kund-ID-värdena.
Låt oss gå vidare till fall #3. Som nämnts, med lagrade procedurfrågor kan du få parameterinbäddningsoptimering när du använder OPTION(RECOMPILE). Använd följande kod för att ändra procedurfrågan så att den inkluderar detta alternativ:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
Utför proc med @custid =1 och @n =3 två gånger:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Du får samma plan som visas tidigare i figur 1 med de inbäddade konstanterna.
Utför proc med @custid =2 och @n =3 en gång:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Du får samma plan som visades tidigare i figur 2 med de inbäddade konstanterna.
Granska exekveringsstatistik:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Denna kod genererar följande utdata:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Antalet körningar visar 1, vilket bara reflekterar den senaste exekveringen. SQL Server cachar den senast körda planen, så den kan visa statistik för den körningen, men på begäran återanvänder den inte planen. Om du kontrollerar planen som visas under attributet query_plan, kommer du att upptäcka att det är den som skapades för konstanterna i den senaste exekveringen, som visades tidigare i figur 2.
Om du är ute efter färre kompileringar och effektiv plancachning och återanvändningsbeteende, är standardmetoden för optimering av lagrad procedur för parameteriserade frågor rätt väg att gå.
Det finns en stor fördel som en iTVF-baserad implementering har framför en lagrad procedurbaserad – när du behöver tillämpa funktionen på varje rad i en tabell och skicka kolumner från tabellen som indata. Anta till exempel att du behöver returnera de tre senaste beställningarna för varje kund i tabellen Sales.Customers. Ingen frågekonstruktion gör att du kan tillämpa en lagrad procedur per rad i en tabell. Du kan implementera en iterativ lösning med en markör, men det är alltid en bra dag när du kan undvika markörer. Genom att kombinera APPLY-operatören med ett iTVF-samtal kan du utföra uppgiften snyggt och rent, så här:
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
Denna kod genererar följande utdata (förkortat):
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
Funktionsanropet infogas och referensen till parametern @custid ersätts med korrelationen C.custid. Detta resulterar i planen som visas i figur 4.
 Figur 4:Planera för fråga med APPLY och Sales.GetTopCustOrders iTVF
Figur 4:Planera för fråga med APPLY och Sales.GetTopCustOrders iTVF
Planen skannar något index i tabellen Sales.Customers för att få uppsättningen kund-ID:n och tillämpar en sökning i det stödjande indexet som du skapade tidigare på Sales.Orders per kund. Det finns bara en plan eftersom funktionen infogades i den yttre frågan och förvandlades till en korrelerad eller en lateral koppling. Den här planen är mycket effektiv, särskilt när custid-kolumnen i Sales.Orders är mycket tät, vilket betyder när det finns ett litet antal distinkta kund-ID:n.
Naturligtvis finns det andra sätt att implementera denna uppgift, som att använda en CTE med funktionen ROW_NUMBER. En sådan lösning tenderar att fungera bättre än den APPLY-baserade när custid-kolumnen i Sales.Orders-tabellen har låg densitet. Hur som helst, den specifika uppgift jag använde i mina exempel är inte så viktig för vår diskussion. Min poäng var att förklara de olika optimeringsstrategierna som SQL Server använder med de olika verktygen.
När du är klar använder du följande kod för rengöring:
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
Sammanfattning och vad som händer härnäst
Så vad har vi lärt oss av detta?
En iTVF är ett återanvändbart parameteriserat namngivet tabelluttryck.
SQL Server använder en parameterinbäddningsoptimeringsstrategi med iTVFs som standard, och en parametriserad frågeoptimeringsstrategi med lagrade procedurfrågor. Att lägga till OPTION(RECOMPILE) till en lagrad procedurfråga kan resultera i optimering av parameterinbäddning.
Om du vill få färre kompileringar och effektiv plancachning och återanvändningsbeteende, är parameteriserade procedurfrågeplaner rätt väg att gå.
Planer för iTVF-frågor cachelagras och kan återanvändas, så länge som samma parametervärden upprepas.
Du kan bekvämt kombinera användningen av APPLY-operatorn och en iTVF för att tillämpa iTVF på varje rad från den vänstra tabellen och skicka kolumner från den vänstra tabellen som indata till iTVF.
Som nämnts finns det mycket att täcka om iTVFs optimering. Den här månaden jämförde jag iTVFs och lagrade procedurer när det gäller standardoptimeringsstrategin och plancaching och återanvändningsbeteende. Nästa månad ska jag gräva djupare i förenklingar som är resultatet av optimering av parameterinbäddning.