Varje lönsamt företag kräver hög tillgänglighet. Webbplatser och bloggar är inte annorlunda eftersom även mindre företag och privatpersoner kräver att deras sajter håller sig live för att behålla sitt rykte.
WordPress är överlägset det mest populära CMS i världen som driver miljontals webbplatser från små till stora. Men hur kan du säkerställa att din webbplats förblir live. Mer specifikt, hur kan jag säkerställa att min databas inte är tillgänglig kommer att påverka min webbplats?
I det här blogginlägget kommer vi att visa hur du uppnår failover för din WordPress-webbplats med ClusterControl.
Inställningen vi kommer att använda för den här bloggen kommer att använda Percona Server 5.7. Vi kommer att ha en annan värd som innehåller applikationerna Apache och Wordpress. Vi kommer inte att röra applikationens högtillgänglighetsdel, men det här är också något du vill vara säker på att ha. Vi kommer att använda ClusterControl för att hantera databaser för att säkerställa tillgängligheten och vi kommer att använda en tredje värd för att installera och konfigurera själva ClusterControl.
Förutsatt att ClusterControl är igång måste vi importera vår befintliga databas till den.
Importera ett databaskluster med ClusterControl
Gå till alternativet Importera befintlig server/databas i distributionsguiden.
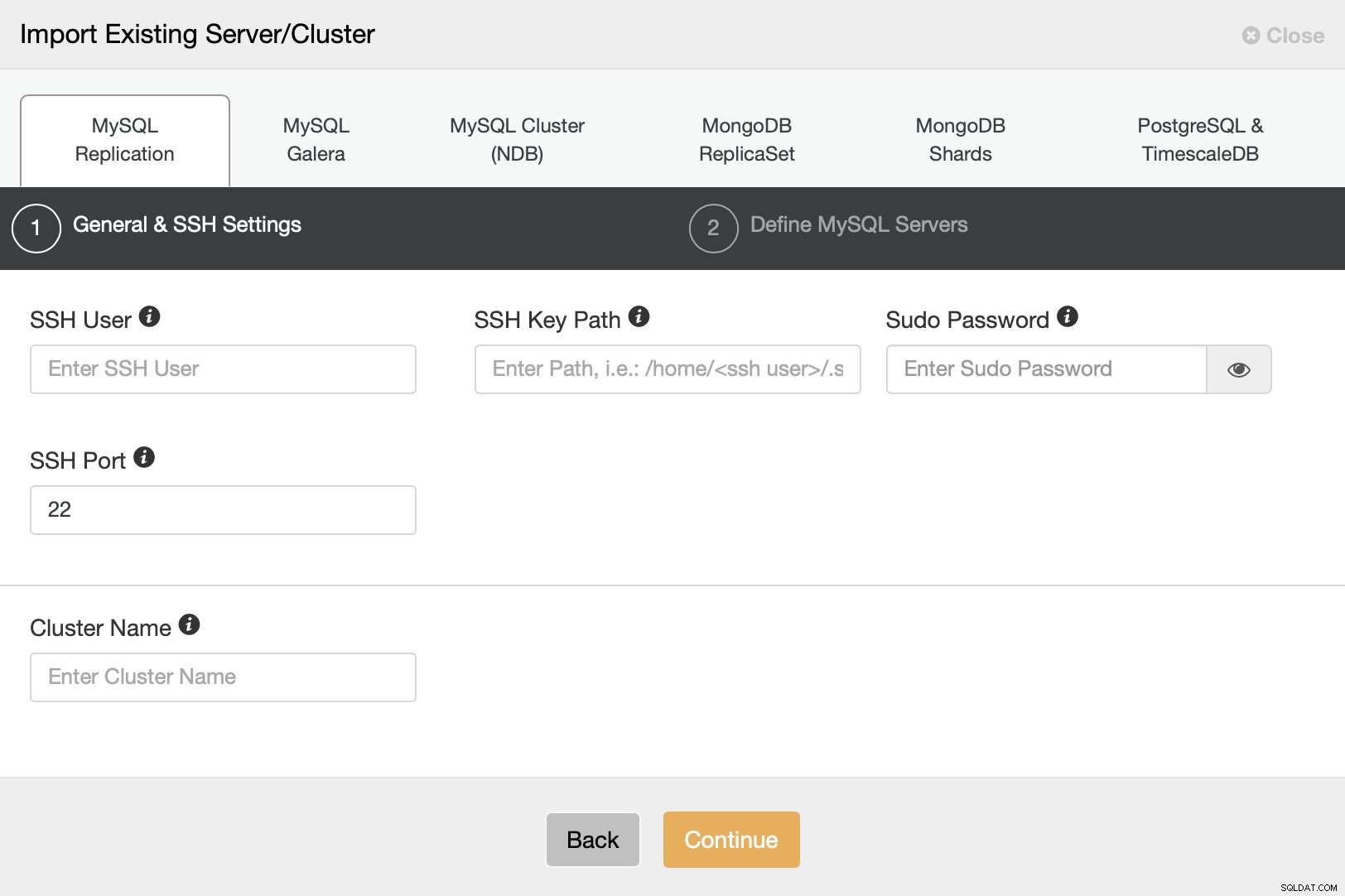
Vi måste konfigurera SSH-anslutningen eftersom detta är ett krav för ClusterControl att kunna hantera noderna.
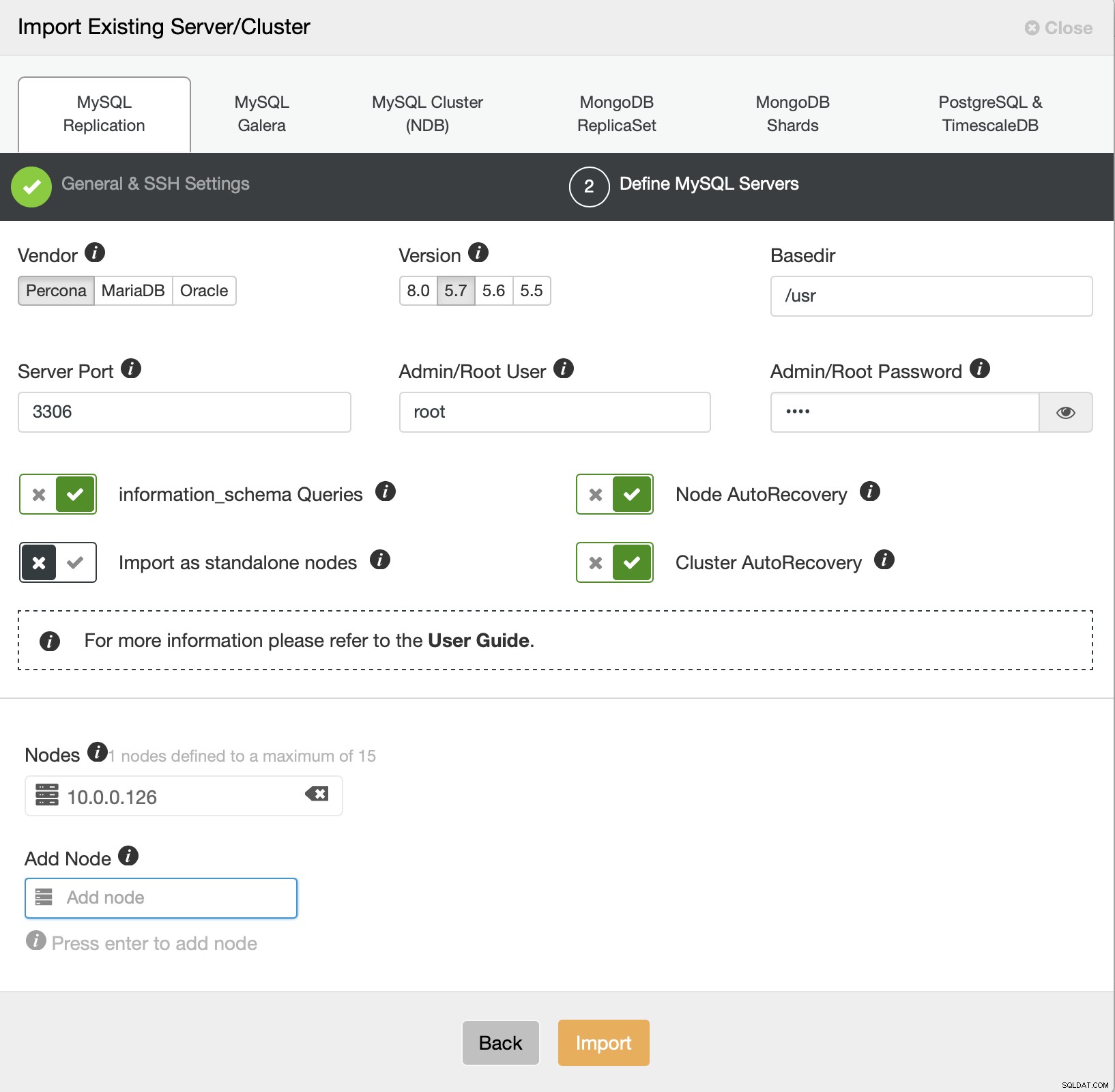
Vi måste nu definiera några detaljer om leverantören, versionen, rootanvändaren access, själva noden och om vi vill att ClusterControl ska hantera autoåterställning åt oss eller inte. Det är allt, när jobbet har lyckats kommer du att presenteras med ett kluster på listan.
För att ställa in den mycket tillgängliga miljön måste vi köra ett par av åtgärder. Vår miljö kommer att bestå av...
- Master - slavpar
- Två ProxySQL-instanser för läs/skrivdelning och topologidetektering
- Två Keepalive-instanser för virtuell IP-hantering
Idén är enkel - vi kommer att distribuera slaven till vår mästare så vi kommer att ha en andra instans att failover till om mastern misslyckas. ClusterControl kommer att ansvara för feldetektering och kommer att främja slaven om mastern skulle bli otillgänglig. ProxySQL kommer att hålla reda på replikeringstopologin och den kommer att omdirigera trafiken till rätt nod - skrivningar kommer att skickas till mastern, oavsett vilken nod den är i, läsningar kan antingen skickas till master-only eller distribueras över master och slavar . Slutligen kommer Keepalived att samlokaliseras med ProxySQL och det kommer att tillhandahålla VIP för applikationen att ansluta till. Denna VIP kommer alltid att tilldelas en av ProxySQL-instanserna och Keepalived kommer att flytta den till den andra, om den "huvudsakliga" ProxySQL-noden skulle misslyckas.
När det är sagt, låt oss konfigurera detta med ClusterControl. Allt kan göras med bara ett par klick. Vi börjar med att lägga till slaven.
Lägga till en databasslav med ClusterControl

Vi börjar med att välja "Lägg till replikeringsslav". Sedan ombeds vi att fylla i ett formulär:
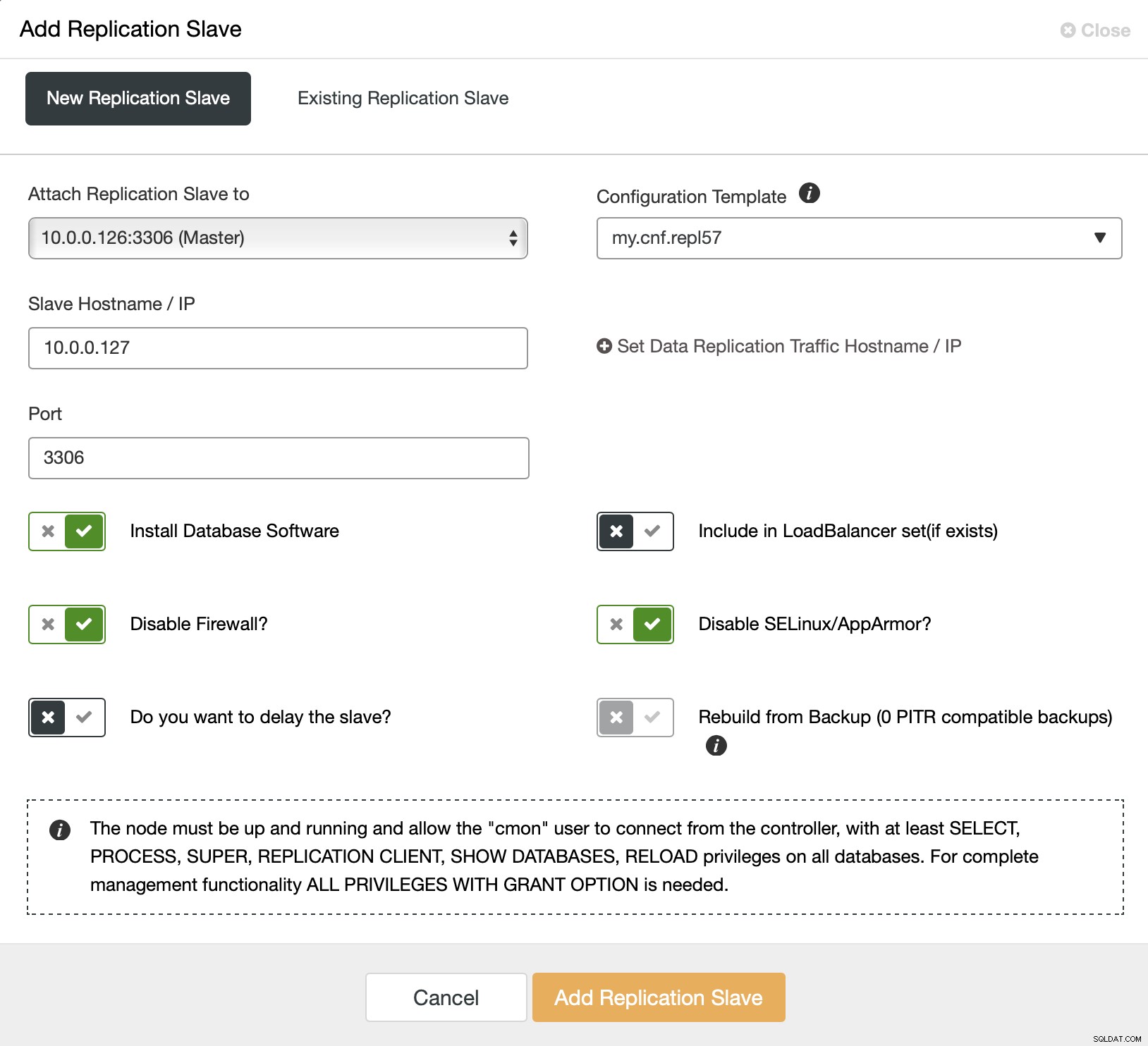
Vi måste välja mastern (i vårt fall gör vi inte riktigt har många alternativ), måste vi skicka IP:n eller värdnamnet för den nya slaven. Om vi hade skapat säkerhetskopior tidigare, kunde vi använda en av dem för att tillhandahålla slaven. I vårt fall är detta inte tillgängligt och ClusterControl kommer att tillhandahålla slaven direkt från mastern. Det är allt, jobbet startar och ClusterControl utför nödvändiga åtgärder. Du kan övervaka framstegen på fliken Aktivitet.

Slutligen, när jobbet har slutförts framgångsrikt, bör slaven vara synlig på klusterlista.

Nu fortsätter vi med att konfigurera ProxySQL-instanserna. I vårt fall är miljön minimal så, för att göra saker enklare, kommer vi att lokalisera ProxySQL på en av databasnoderna. Detta är dock inte det bästa alternativet i en verklig produktionsmiljö. Helst skulle ProxySQL antingen placeras på en separat nod eller samlokaliseras med de andra programvärdarna.
Platsen för att börja jobbet är Hantera -> Lastbalanserare.
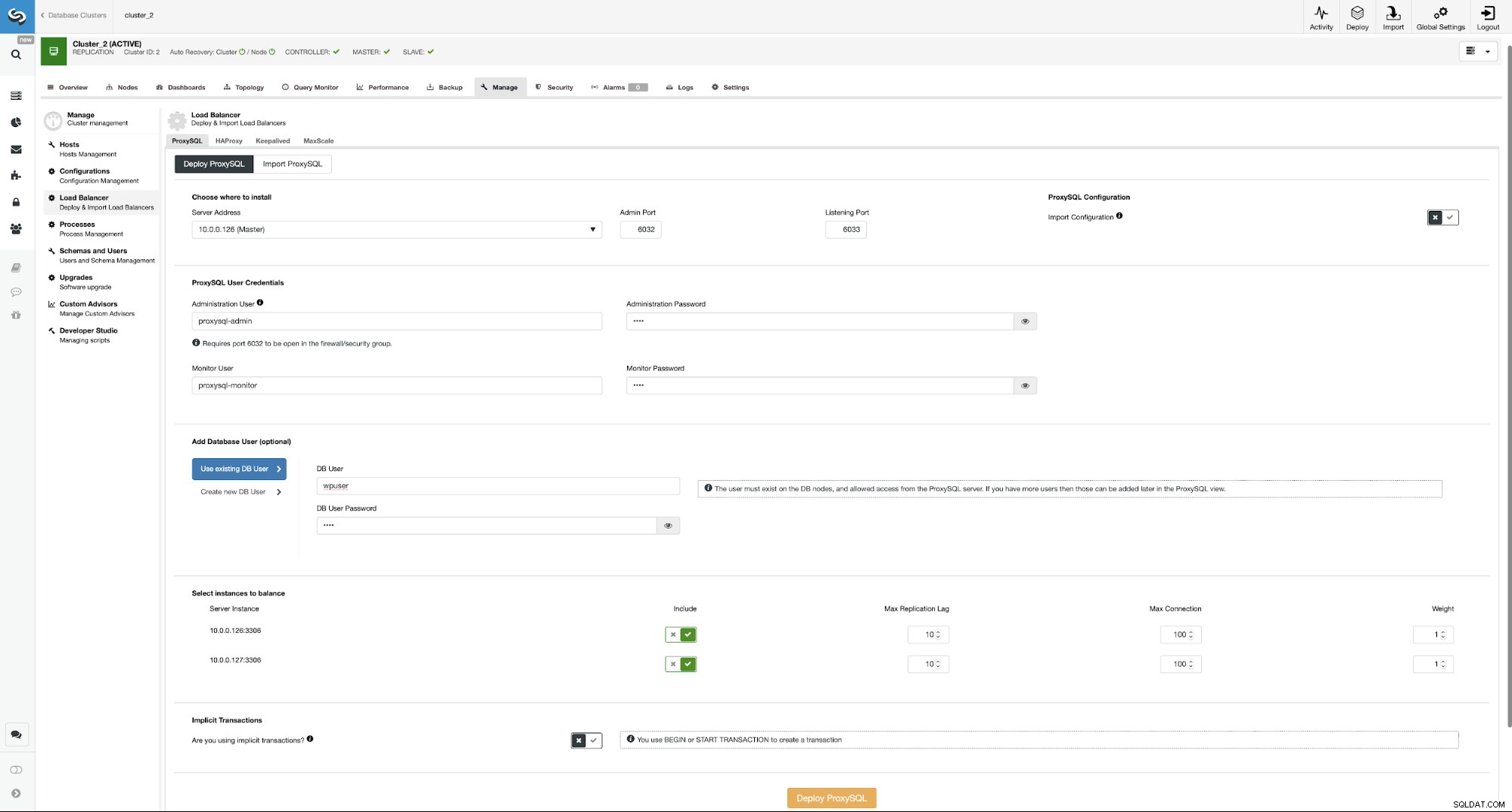
Här måste du välja var ProxySQL ska installeras, skicka administrativa autentiseringsuppgifter , och lägg till en databasanvändare. I vårt fall kommer vi att använda vår befintliga användare eftersom vår WordPress-applikation redan använder den för att ansluta till databasen. Vi måste sedan välja vilka noder som ska användas i ProxySQL (vi vill ha både master och slav här) och låta ClusterControl veta om vi använder explicita transaktioner eller inte. Detta är inte riktigt relevant i vårt fall, eftersom vi kommer att konfigurera om ProxySQL när det kommer att distribueras. När du har det alternativet aktiverat kommer läs/skrivdelning inte att vara aktiverat. Annars kommer ClusterControl att konfigurera ProxySQL för läs/skrivdelning. I vår minimala inställning bör vi seriöst fundera på om vi vill att läs/skrivdelningen ska ske. Låt oss analysera det.
Fördelar och nackdelar med läs-/skrivspett i ProxySQL
Den största fördelen med att använda läs/skrivdelningen är att all SELECT-trafik kommer att fördelas mellan mastern och slaven. Detta innebär att belastningen på noderna blir lägre och svarstiden bör också vara lägre. Detta låter bra, men kom ihåg att om en nod skulle misslyckas måste den andra noden kunna ta emot all trafik. Det är ingen mening med att ha automatiserad failover på plats om förlusten av en nod innebär att den andra noden kommer att vara överbelastad och, de facto, också otillgänglig.
Det kan vara vettigt att fördela belastningen om du har flera slavar - att förlora en nod av fem är mindre påverkande än att förlora en av två. Oavsett vad du bestämmer dig för kan du enkelt ändra beteendet genom att gå till ProxySQL-noden och klicka på fliken Regler.
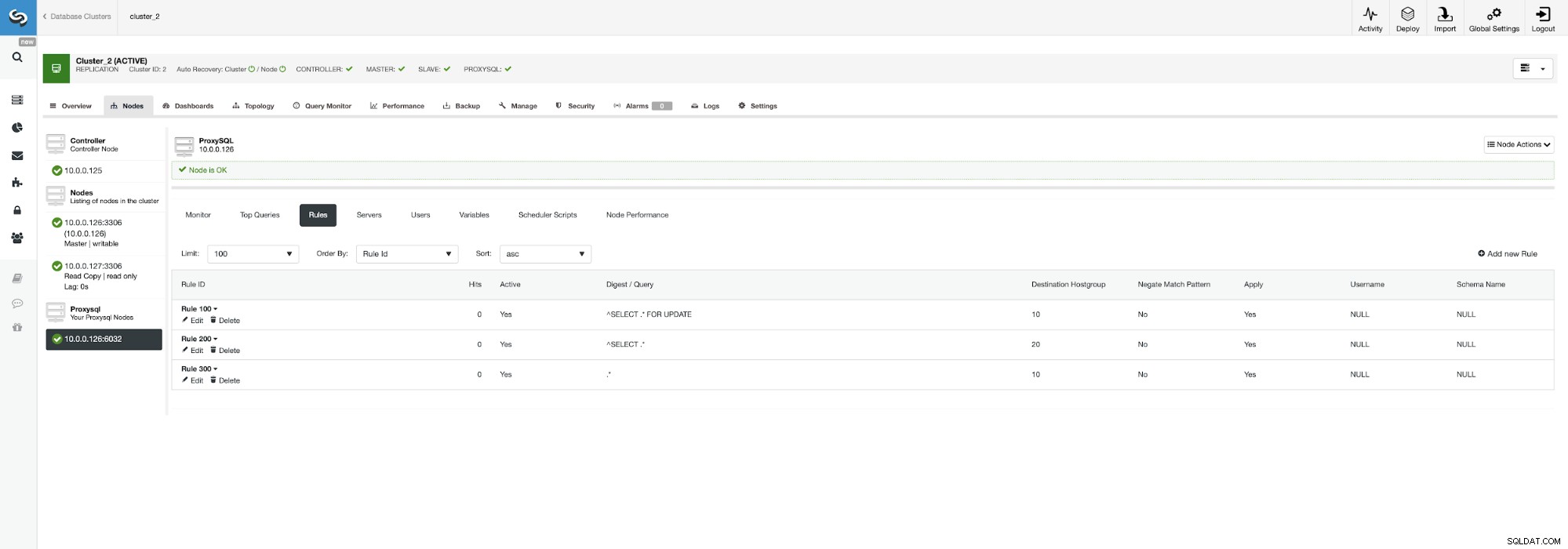
Se till att titta på regel 200 (den som fångar alla SELECT-satser ). På skärmdumpen nedan kan du se att destinationsvärdgruppen är 20, vilket betyder att alla noder i klustret - läs/skrivdelning och utskalning är aktiverad. Vi kan enkelt inaktivera detta genom att redigera den här regeln och ändra destinationsvärdgruppen till 10 (den som innehåller master).
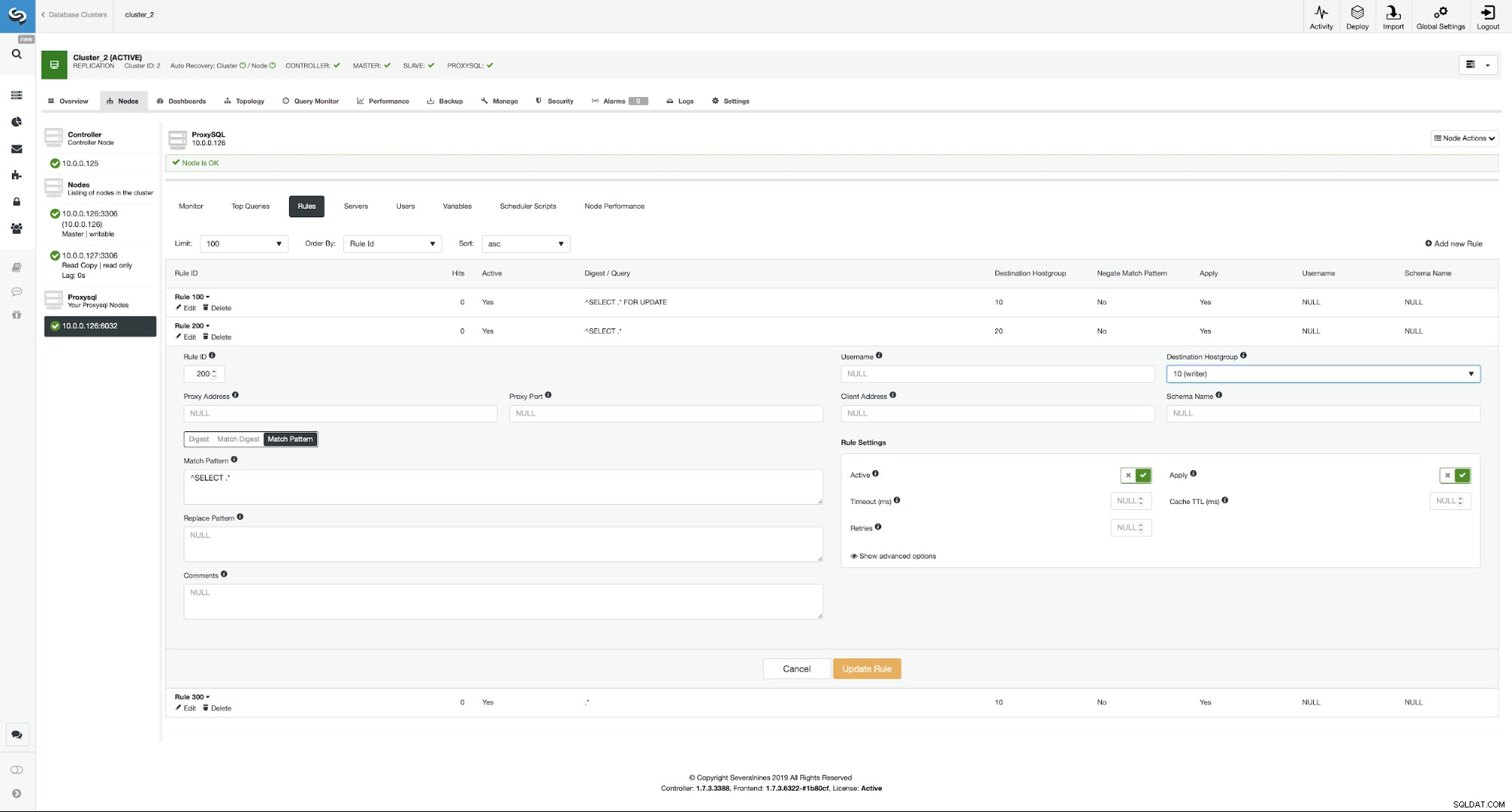
Om du vill aktivera läs/skrivdelning kan du enkelt gör det genom att redigera den här frågeregeln igen och ställa tillbaka destinationsvärdgruppen till 20.
Nu, låt oss distribuera andra ProxySQL.
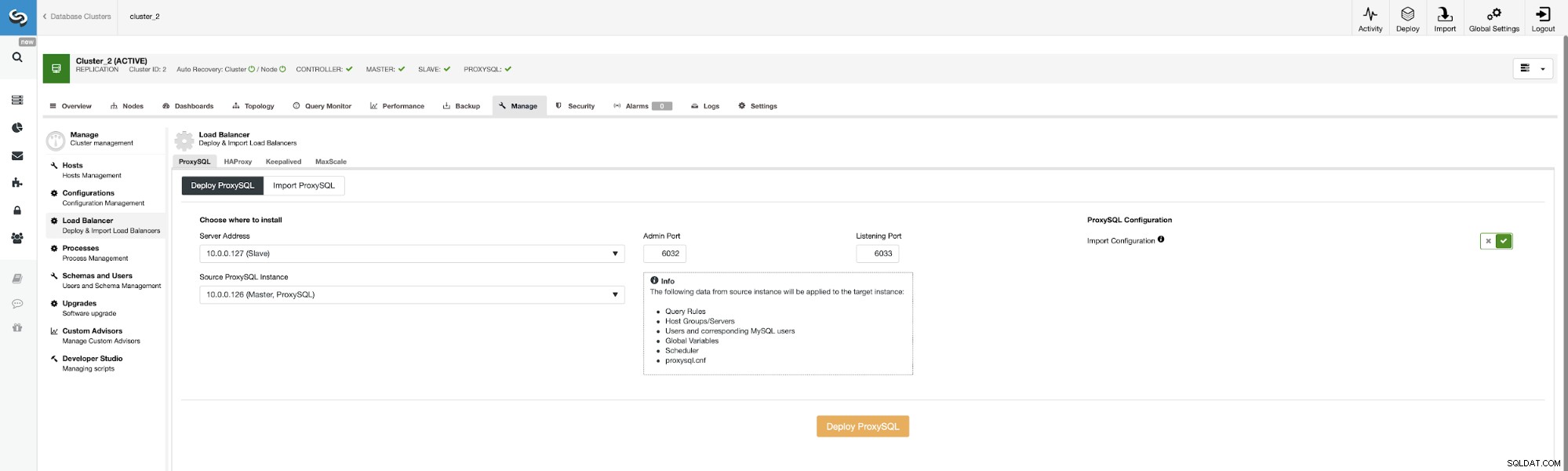
För att undvika att skicka alla konfigurationsalternativ igen kan vi använda "Importera konfiguration" ” och välj vår befintliga ProxySQL som källa.
När det här jobbet är klart måste vi fortfarande utföra det sista steget för att ställa in vår miljö. Vi måste distribuera Keepalived ovanpå ProxySQL-instanserna.
Distribuera Keepalived ovanpå ProxySQL-instanser
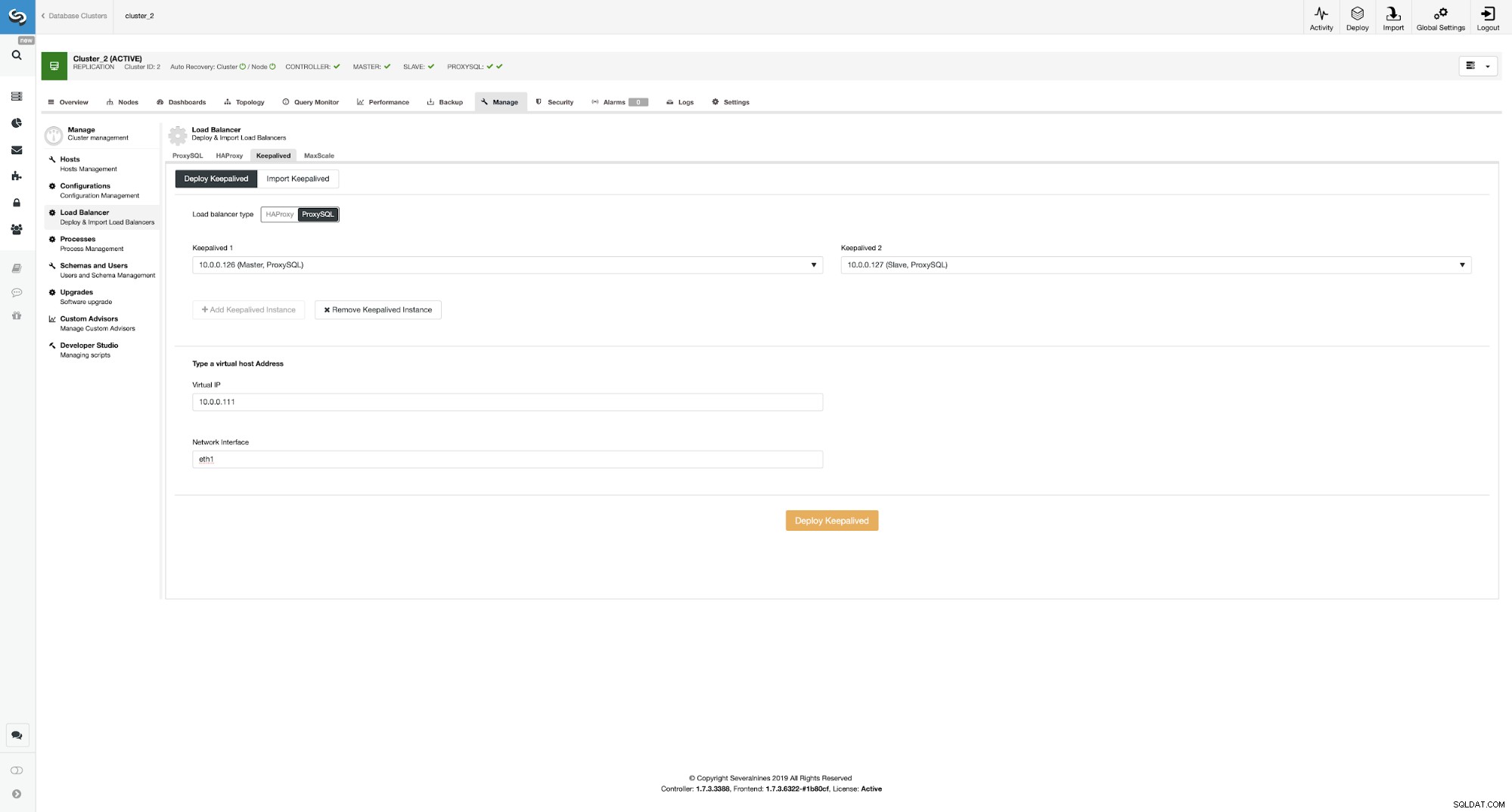
Här valde vi ProxySQL som belastningsbalanseringstyp, passerade båda ProxySQL-instanserna för Keepalved för att installeras på och vi skrev vårt VIP- och nätverksgränssnitt.
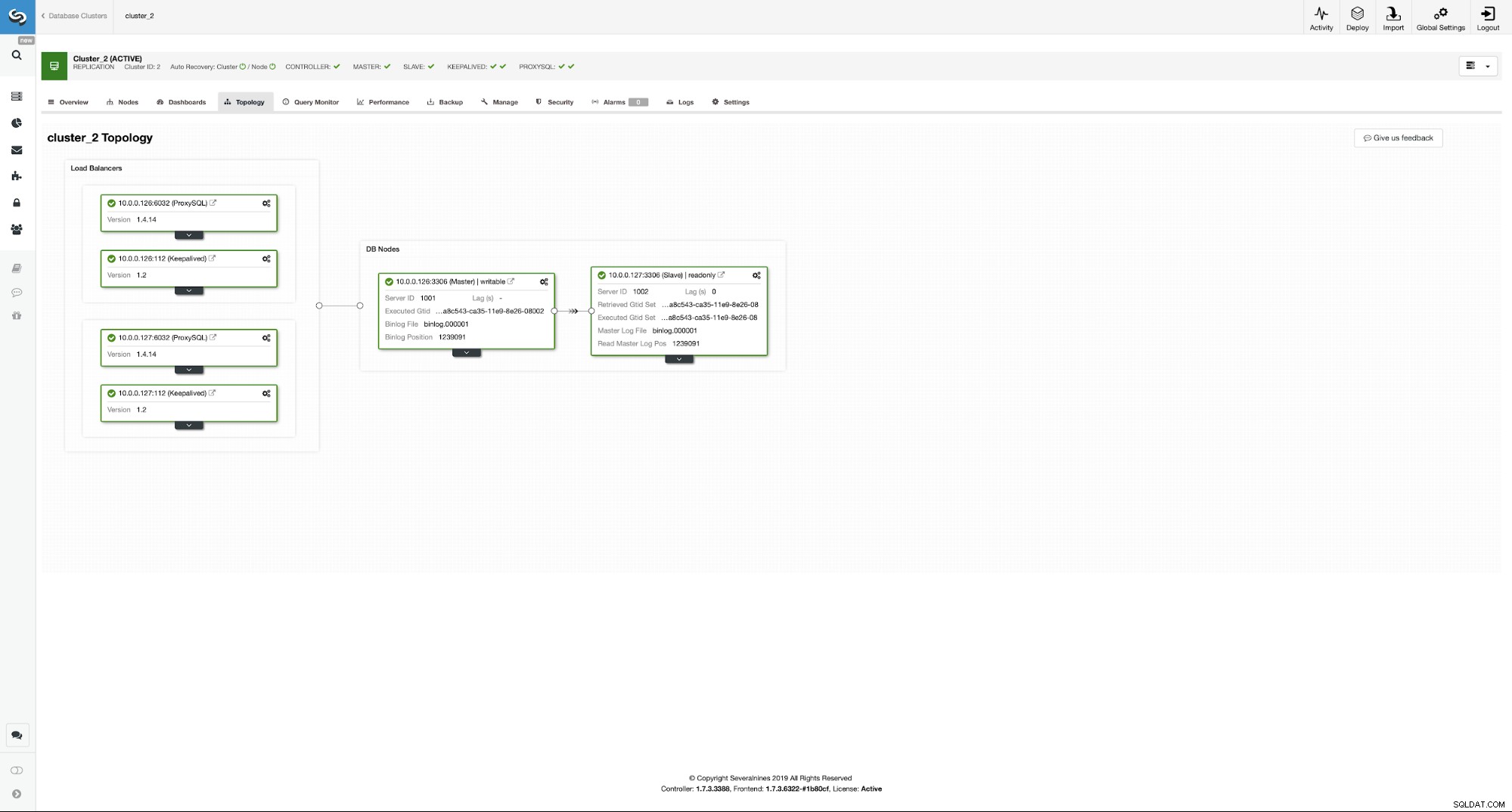
Som du kan se har vi nu hela installationen klar och klar. Vi har en VIP på 10.0.0.111 som är tilldelad en av ProxySQL-instanserna. ProxySQL-instanser kommer att omdirigera vår trafik till rätt backend MySQL-noder och ClusterControl kommer att hålla ett öga på miljön som utför failover om det behövs. Den sista åtgärden vi måste vidta är att konfigurera om Wordpress för att använda den virtuella IP:n för att ansluta till databasen.
För att göra det måste vi redigera wp-config.php och ändra variabeln DB_HOST till vår virtuella IP:
/** MySQL hostname */
define( 'DB_HOST', '10.0.0.111' );Slutsats
Från och med nu kommer Wordpress att ansluta till databasen med VIP och ProxySQL. Om masternoden misslyckas kommer ClusterControl att utföra failover.
Som ni ser har ny master valts och ProxySQL pekar också mot ny master i värdgruppen 10.
Vi hoppas att det här blogginlägget ger dig en uppfattning om hur du designar en mycket tillgänglig databasmiljö för en Wordpress-webbplats och hur ClusterControl kan användas för att distribuera alla dess element.