Detta är den andra delen av en serie i fem delar som tar en djupdykning i hur parallella planer för SQL Server-radläge startar. I slutet av den första delen hade vi skapat exekveringskontext noll för föräldrauppgiften. Det här sammanhanget innehåller hela trädet med körbara operatorer, men de är ännu inte redo för den iterativa exekveringsmodellen för frågebearbetningsmotorn.
Iterativ körning
SQL Server kör en fråga genom en process som kallas frågesökning . Initiering av planen börjar vid roten genom att frågeprocessorn anropar Open på rotnoden. Open anrop går igenom trädet av iteratorer som rekursivt anropar Open på varje barn tills hela trädet öppnas.
Processen att returnera resultatrader är också rekursiv, utlöst av frågeprocessorn som anropar GetRow vid roten. Varje rotanrop returnerar en rad åt gången. Frågeprocessorn fortsätter att anropa GetRow på rotnoden tills inga fler rader är tillgängliga. Körningen stängs av med en sista rekursiv Close ringa upp. Detta arrangemang gör det möjligt för frågeprocessorn att initiera, exekvera och stänga alla godtyckliga planer genom att anropa samma gränssnittsmetoder precis vid roten.
För att omvandla trädet med körbara operatorer till ett som är lämpligt för rad-för-rad-bearbetning, lägger SQL Server till en frågesökning omslag till varje operatör. Frågesökningen objektet tillhandahåller Open , GetRow och Close metoder som behövs för iterativ exekvering.
Frågeskanningsobjektet upprätthåller också tillståndsinformation och avslöjar andra operatörsspecifika metoder som behövs under exekvering. Till exempel, frågeskanningsobjektet för en Start-Up Filter-operatör (CQScanStartupFilterNew ) avslöjar följande metoder:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
De ytterligare metoderna för denna iterator används oftast i markörplaner.
Initiera sökfrågan
Omslutningsprocessen kallas initiering av sökfrågan . Det utförs av ett anrop från frågeprocessorn till CQueryScan::InitQScanRoot . Den överordnade uppgiften utför denna process för hela planen (finns i exekveringskontext noll). Översättningsprocessen är i sig själv rekursiv, börjar vid roten och arbetar sig ner i trädet.
Under denna process är varje operatör ansvarig för att initiera sina egna data och skapa eventuella runtime-resurser det behöver. Detta kan innefatta att skapa ytterligare objekt utanför frågeprocessorn, till exempel de strukturer som behövs för att kommunicera med lagringsmotorn för att hämta data från beständig lagring.
En påminnelse om genomförandeplanen, med nodnummer tillagda (klicka för att förstora):
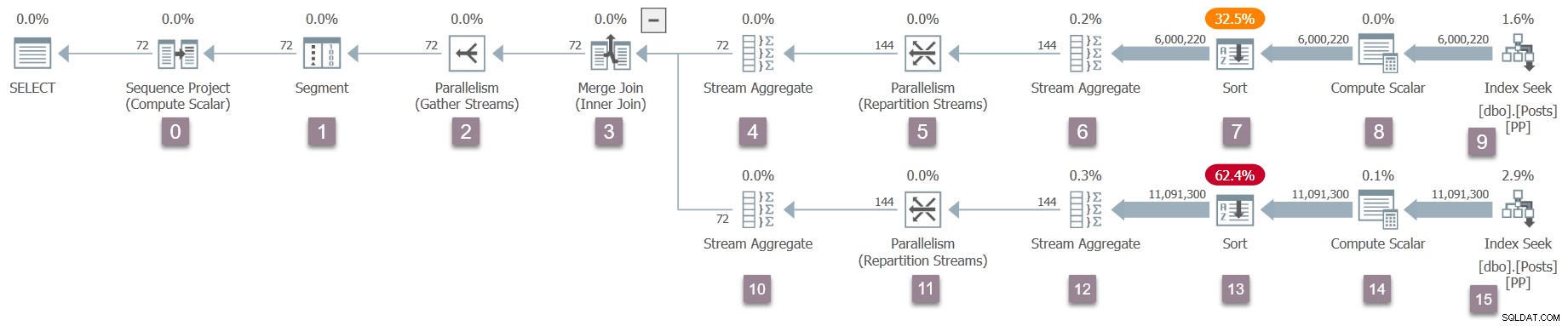
Operatören vid roten (nod 0) i det körbara planträdet är ett sekvensprojekt . Den representeras av en klass som heter CXteSeqProject . Som vanligt är det här den rekursiva transformationen börjar.
Frågeavsökningsomslag
Som nämnts, CXteSeqProject objektet är inte utrustat för att delta i den iterativa frågesökningen process — den har inte den nödvändiga Open , GetRow och Close metoder. Frågeprocessorn behöver ett omslag runt den körbara operatören för att tillhandahålla det gränssnittet.
För att få det frågeavsökningsomslaget anropar den överordnade uppgiften CXteSeqProject::QScanGet för att returnera ett objekt av typen CQScanSeqProjectNew . Den länkade kartan av operatorer som skapats tidigare uppdateras för att referera till det nya frågeskanningsobjektet, och dess iteratormetoder är kopplade till planens rot.
Sekvensprojektets underordnade är ett segment operatör (nod 1). Anropar CXteSegment::QScanGet returnerar ett frågeavsökningsobjekt av typen CQScanSegmentNew . Den länkade kartan uppdateras igen, och iteratorfunktionspekare kopplas till den överordnade sekvensprojektets frågesökning.
Ett halvt utbyte
Nästa operatör är ett utbyte för samla strömmar (nod 2). Anropar CXteExchange::QScanGet returnerar en CQScanExchangeNew som du kanske förväntar dig vid det här laget.
Detta är den första operatören i trädet som behöver utföra betydande extra initiering. Det skapar konsumentsidan av börsen via CXTransport::CreateConsumerPart . Detta skapar porten (CXPort ) — en datastruktur i delat minne som används för synkronisering och datautbyte — och en pipe (CXPipe ) för pakettransport. Observera att producenten sidan av utbytet är inte skapad just nu. Vi har bara ett halvt utbyte!
Mer omslag
Processen att ställa in frågeprocessorskanningen fortsätter sedan med sammanfogningen (nod 3). Jag kommer inte alltid att upprepa QScanGet och CQScan* från och med nu, men de följer det etablerade mönstret.
Sammanslagningen har två barn. Inställningen av sökfrågesökning fortsätter som tidigare med den yttre (översta) ingången – ett strömaggregat (nod 4), sedan strömmar en ompartition utbyte (nod 5). Ompartitionsströmmarna skapar återigen bara konsumentsidan av utbytet, men den här gången skapas två rör eftersom DOP är två. Konsumentsidan av denna typ av växel har DOP-anslutningar till sin moderoperatör (en per tråd).
Därefter har vi en annan strömsamling (nod 6) och en sortering (nod 7). Sorteringen har ett underordnat som inte är synligt i exekveringsplaner – en raduppsättning för lagringsmotorer som används för att implementera spill till tempdb . Den förväntade CQScanSortNew åtföljs därför av en underordnad CQScanRowsetNew i det inre trädet. Det är inte synligt i showplan-utgången.
I/O-profilering och uppskjutna operationer
sorteringen operator är också den första vi har initierat hittills som kan vara ansvarig för I/O . Förutsatt att exekveringen har begärt I/O-profileringsdata (t.ex. genom att begära en "faktisk" plan) skapar sorteringen ett objekt för att registrera denna runtime-profileringsdata via CProfileInfo::AllocProfileIO .
Nästa operator är en beräkningsskalär (nod 8), kallat ett projekt internt. Konfigurationsanropet för söksökning till CXteProject::QScanGet gör det inte returnera ett frågeskanningsobjekt eftersom beräkningarna som utförs av denna beräkningsskalär är uppskjutna till den första överordnade operatören som behöver resultatet. I den här planen är den operatören den sorten. Sorteringen kommer att utföra allt arbete som tilldelats beräkningsskalären, så projektet vid nod 8 utgör inte en del av frågeskanningsträdet. Beräkningsskalären körs verkligen inte under körning. För mer information om uppskjutna beräkningsskalärer, se Beräkna skalärer, uttryck och prestanda för exekveringsplan.
Parallell scan
Den sista operatorn efter beräkningsskalären på denna gren av planen är en indexsökning (CXteRange ) vid nod 9. Detta producerar den förväntade frågeskanningsoperatorn (CQScanRangeNew ), men det kräver också en komplex sekvens av initieringar för att ansluta till lagringsmotorn och underlätta en parallell skanning av indexet.
Täcker bara höjdpunkterna, initierar indexsökningen:
- Skapar ett profileringsobjekt för I/O (
CProfileInfo::AllocProfileIO). - Skapar en parallell raduppsättning sökfråga (
CQScanRowsetNew::ParallelGetRowset). - Ställer in en synkronisering objekt för att koordinera körtidsparallellt intervallavsökning (
CQScanRangeNew::GetSyncInfo). - Skapar lagringsmotorns tabellmarkör och en skrivskyddad transaktionsbeskrivning .
- Öppnar den överordnade raduppsättningen för läsning (åtkomst till HoBt och tar de nödvändiga spärrarna).
- Ställer in tidsgränsen för låsning.
- Ställer in förhämtning (inklusive tillhörande minnesbuffertar).
Lägga till radlägesprofileringsoperatorer
Vi har nu nått bladnivån för denna gren av planen (indexsökningen har inget barn). När du precis har skapat frågesökningsobjektet för indexsökningen är nästa steg att sluta frågesökningen med en profileringsklass (förutsatt att vi begärde en faktisk plan). Detta görs genom ett anrop till sqlmin!PqsWrapQScan . Observera att profiler läggs till efter att frågesökningen har skapats, när vi börjar stiga upp i iteratorträdet.
PqsWrapQScan skapar en ny profileringsoperatör som förälder av indexsökningen, via ett anrop till CProfileInfo::GetOrCreateProfileInfo . profileringsoperatören (CQScanProfileNew ) har de vanliga sökgränssnittsmetoderna. Förutom att samla in de data som behövs för faktiska planer, exponeras profildata även via DMV sys.dm_exec_query_profiles .
Att fråga efter att DMV vid detta exakta ögonblick för den aktuella sessionen visar att endast en enda planoperatör (nod 9) existerar (vilket betyder att det är den enda som lindas av en profilerare):

Den här skärmdumpen visar hela resultatuppsättningen från DMV för närvarande (den har inte redigerats).
Nästa, CQScanProfileNew anropar query performance counter API (KERNEL32!QueryPerformanceCounterStub ) tillhandahålls av operativsystemet för att registrera den första och sista aktiva tiden för den profilerade operatören:

Den senaste aktiva tiden kommer att uppdateras med hjälp av frågeprestandaräknaren API varje gång koden för den iteratorn körs.
Profileraren ställer sedan in det uppskattade antalet rader vid denna punkt i planen (CProfileInfo::SetCardExpectedRows ), som står för valfritt radmål (CXte::CardGetRowGoal ). Eftersom detta är en parallell plan delar den resultatet med antalet trådar (CXte::FGetRowGoalDefinedForOneThread ) och sparar resultatet i körningskontexten.
Det uppskattade antalet rader är inte synligt via DMV vid denna tidpunkt, eftersom den överordnade uppgiften inte kommer att köra denna operatör. Istället kommer uppskattningen per tråd att exponeras senare i parallella exekveringssammanhang (som inte har skapats ännu). Ändå sparas numret per tråd i den överordnade uppgiftens profiler – det är helt enkelt inte synligt via DMV.
Det vänliga namnet för planoperatören ("Index Seek") ställs sedan in via ett anrop till CXteRange::GetPhysicalOp :

Innan dess kanske du har märkt att efterfrågan på DMV visade namnet som "???". Detta är det permanenta namnet som visas för osynliga operatörer (t.ex. kapslade slingor förhämtning, batchsortering) som inte har ett vänligt namn definierat.
Till sist, indexera metadata och aktuell I/O-statistik för den inslagna indexsökningen läggs till via ett anrop till CQScanRowsetNew::GetIoCounters :

Räknarna är noll för tillfället, men kommer att uppdateras när indexsökningen utför I/O under avslutad planexekvering.
Mer bearbetning av sökfrågor
Med profileringsoperatorn skapad för indexsökningen flyttas söksökningsbehandlingen tillbaka upp i trädet till den överordnade sorteringen (nod 7).
Sorteringen utför följande initieringsuppgifter:
- Registrerar dess minnesanvändning med frågan minneshanterare (
CQryMemManager::RegisterMemUsage) - Beräknar det minne som krävs för sorteringsingången (
CQScanIndexSortNew::CbufInputMemory) och utdata (CQScanSortNew::CbufOutputMemory). - Sorteringstabellen skapas, tillsammans med dess tillhörande raduppsättning för lagringsmotorn (
sqlmin!RowsetSorted). - En fristående systemtransaktion (inte begränsat av användartransaktionen) skapas för sortering av spilldisktilldelningar, tillsammans med en falsk arbetstabell (
sqlmin!CreateFakeWorkTable). - Expressionstjänsten initieras (
sqlTsEs!CEsRuntime::Startup) för sorteringsoperatorn att utföra beräkningarna uppskjutna från beräkningsskalären. - Förhämtning för alla typer av körningar spills ut till tempdb skapas sedan via (
CPrefetchMgr::SetupPrefetch).
Slutligen lindas sökningen av sorteringsfrågan av en profileringsoperatör (inklusive I/O) precis som vi såg för indexsökningen:

Lägg märke till att beräkningsskalären (nod 8) saknas från DMV. Det beror på att dess arbete är uppskjutet till sorteringen, inte är en del av frågeskanningsträdet och därför inte har något omslagsprofilobjekt.
Flytta upp till den överordnade typen, strömningsaggregatet frågeavsökningsoperator (nod 6) initierar sina uttryck och körtidsräknare (t.ex. aktuellt antal grupprader). Strömaggregatet lindas med en profileringsoperatör som registrerar dess initiala tider:

Den överordnade ompartitionen strömmar utbyte (nod 5) lindas av en profilerare (kom ihåg att endast konsumentsidan av detta utbyte existerar vid denna tidpunkt):

Detsamma görs för dess överordnade strömaggregat (nod 4), som också initieras som tidigare beskrivits:

Bearbetningen av sökfrågan återgår till den överordnade sammanfogningen (nod 3) men initierar den inte ännu. Istället flyttar vi ner på den inre (nedre) sidan av sammanfogningen och utför samma detaljerade uppgifter för dessa operatörer (noderna 10 till 15) som för den övre (yttre) grenen:
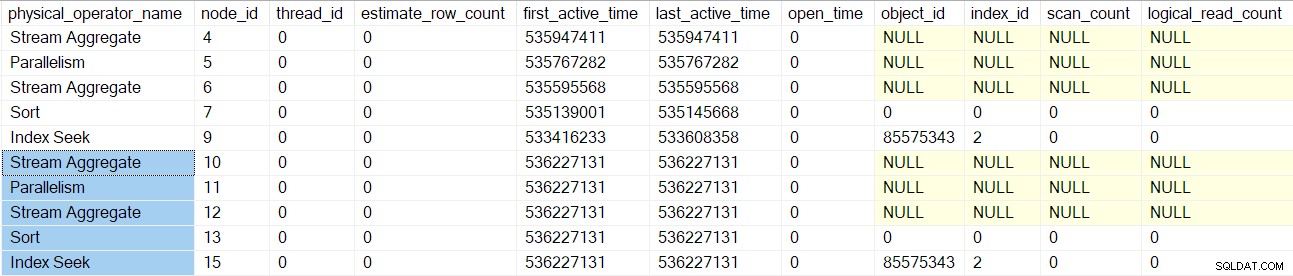
När dessa operatörer har bearbetats, sammanfogning frågesökning skapas, initieras och lindas med ett profileringsobjekt. Detta inkluderar I/O-räknare eftersom en fler-många sammanfogning använder en arbetstabell (även om den aktuella sammanslagningen är en-många):
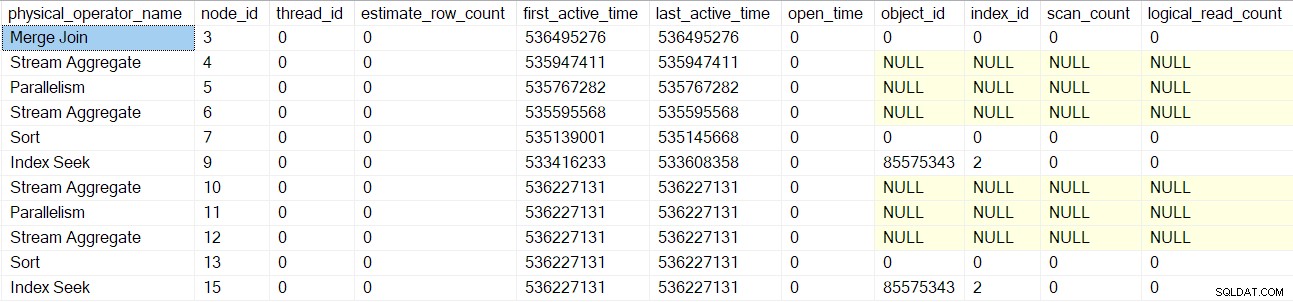
Samma process följs för utbytet för föräldrainsamlingsströmmar (nod 2) endast konsumentsidan, segment (nod 1) och sekvensprojekt (nod 0) operatorer. Jag kommer inte att beskriva dem i detalj.
Frågeprofilerna DMV rapporterar nu en fullständig uppsättning profiler-omslutna frågeskanningsnoder:
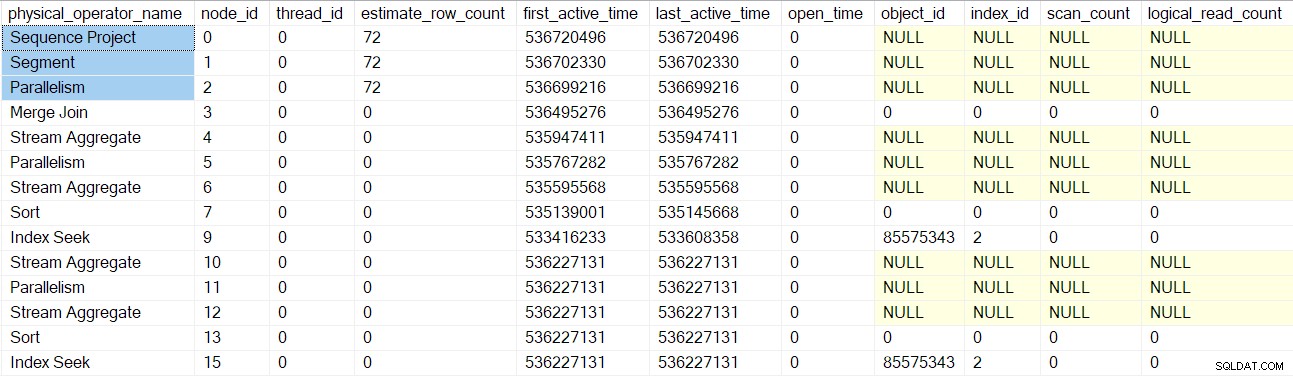
Lägg märke till att sekvensprojekt, segment och samla strömmar konsumenten har ett uppskattat antal rader eftersom dessa operatörer kommer att köras av överordnad uppgift , inte genom ytterligare parallella uppgifter (se CXte::FGetRowGoalDefinedForOneThread tidigare). Den överordnade uppgiften har inget arbete att göra i parallella grenar, så konceptet med beräknat radantal är bara vettigt för ytterligare uppgifter.
De aktiva tidsvärdena som visas ovan är något förvrängda eftersom jag behövde stoppa exekveringen och ta DMV-skärmdumpar vid varje steg. En separat exekvering (utan de artificiella förseningar som introducerades genom att använda en debugger) gav följande tidpunkter:
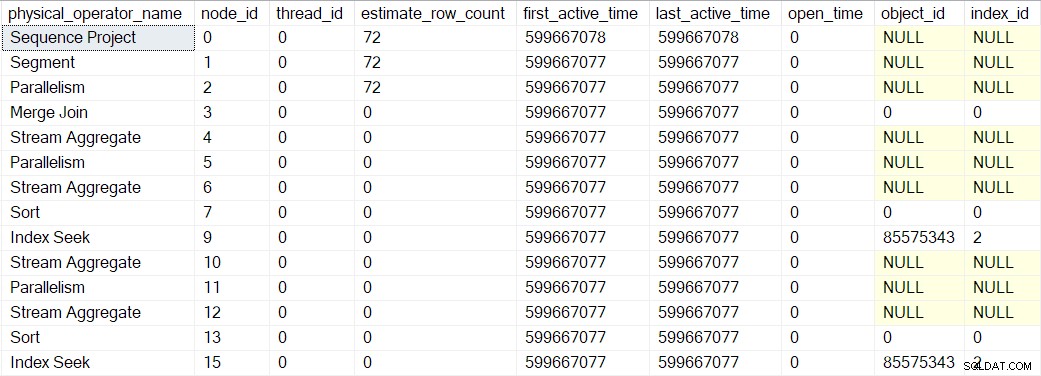
Trädet är konstruerat i samma sekvens som beskrivits tidigare, men processen är så snabb att det bara tar en mikrosekund skillnaden mellan den första lindade operatörens aktiva tid (indexsökningen vid nod 9) och den sista (sekvensprojektet vid nod 0).
Slutet av del 2
Det kan låta som att vi har gjort mycket arbete, men kom ihåg att vi bara har skapat ett sökfrågesökningsträd för förälderuppgiften , och börserna har bara en konsumentsida (ingen producent ännu). Vår parallellplan har också bara en tråd (som visas i den sista skärmdumpen). Del 3 kommer att se skapandet av våra första ytterligare parallella uppgifter.