Detta är den andra delen i en serie om lösningar på nummerseriegeneratorutmaningen. Förra månaden tog jag upp lösningar som genererar raderna i farten med hjälp av en tabellvärdekonstruktor med rader baserade på konstanter. Det fanns inga I/O-operationer involverade i dessa lösningar. Den här månaden fokuserar jag på lösningar som frågar efter en fysisk bastabell som du i förväg fyller i med rader. Av denna anledning, förutom att rapportera tidsprofilen för lösningarna som jag gjorde förra månaden, kommer jag också att rapportera I/O-profilen för de nya lösningarna. Tack igen till Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 och Ed Wagner för att du delar med dig av dina idéer och kommentarer.
Snabbaste lösningen hittills
Först, som en snabb påminnelse, låt oss granska den snabbaste lösningen från förra månadens artikel, implementerad som en inline TVF kallad dbo.GetNumsAlanCharlieItzikBatch.
Jag ska göra mina tester i tempdb, aktivera IO- och TIME-statistik:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Den snabbaste lösningen från förra månaden tillämpar en join med en dummy-tabell som har ett columnstore-index för att få batchbearbetning. Här är koden för att skapa dummy-tabellen:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Och här är koden med definitionen av dbo.GetNumsAlanCharlieItzikBatch-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Förra månaden använde jag följande kod för att testa funktionens prestanda med 100 miljoner rader, efter att ha aktiverat Discard-resultaten efter exekvering i SSMS för att undertrycka returnering av utdataraderna:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Här är tidsstatistiken som jag fick för den här exekveringen:
CPU-tid =16031 ms, förfluten tid =17172 ms.Joe Obbish noterade korrekt att detta test kan saknas i sin reflektion av vissa verkliga scenarier i den meningen att en stor del av körtiden beror på asynkrona nätverks I/O-väntningar (ASYNC_NETWORK_IO väntetyp). Du kan observera de högsta väntetiderna genom att titta på egenskapssidan för rotnoden för den faktiska frågeplanen, eller köra en utökad händelsesession med vänteinformation. Det faktum att du aktiverar Kasta resultat efter körning i SSMS hindrar inte SQL Server från att skicka resultatraderna till SSMS; det hindrar bara SSMS från att skriva ut dem. Frågan är, hur troligt är det att du kommer att returnera stora resultatuppsättningar till klienten i verkliga scenarier även när du använder funktionen för att producera en stor nummerserie? Kanske skriver du oftare frågeresultaten till en tabell, eller använder resultatet av funktionen som en del av en fråga som till slut ger en liten resultatuppsättning. Du måste ta reda på det här. Du kan skriva resultatuppsättningen i en temporär tabell med hjälp av SELECT INTO-satsen, eller så kan du använda Alan Bursteins trick med en tilldelning SELECT-sats, som tilldelar resultatkolumnvärdet till en variabel.
Så här skulle du ändra det senaste testet för att använda alternativet för variabeltilldelning:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Här är tidsstatistiken som jag fick för det här testet:
CPU-tid =8641 ms, förfluten tid =8645 ms.Den här gången har vänteinformationen inga asynkrona nätverks-I/O-väntningar, och du kan se den betydande minskningen i körtid.
Testa funktionen igen, denna gång lägg till beställning:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Jag fick följande prestandastatistik för den här körningen:
CPU-tid =9360 ms, förfluten tid =9551 ms.Kom ihåg att det inte finns något behov av en sorteringsoperator i planen för den här frågan eftersom kolumnen n är baserad på ett uttryck som är ordningsbevarande med avseende på kolumnen rownum. Det är tack vare Charlis ständiga vikningstrick, som jag täckte förra månaden. Planerna för båda frågorna – den utan beställning och den med beställning är desamma, så prestanda tenderar att vara likartad.
Figur 1 sammanfattar prestandasiffrorna som jag fick för förra månadens lösningar, bara denna gång med variabeltilldelning i testerna istället för att kassera resultat efter exekvering.
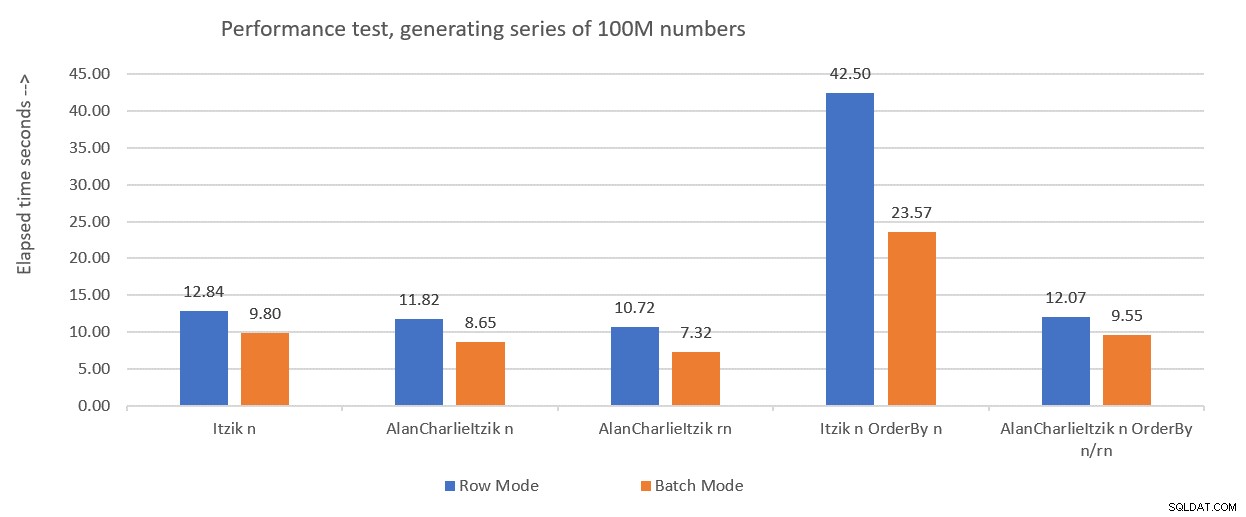 Figur 1:Resultatöversikt hittills med variabeltilldelning
Figur 1:Resultatöversikt hittills med variabeltilldelning
Jag kommer att använda variabeltilldelningstekniken för att testa resten av lösningarna som jag kommer att presentera i den här artikeln. Se till att du justerar dina tester för att bäst återspegla din verkliga situation, med hjälp av variabel tilldelning, SELECT INTO, Kasta resultat efter exekvering eller någon annan teknik.
Tips för att tvinga fram serieplaner utan MAXDOP 1
Innan jag presenterar nya lösningar ville jag bara ge ett litet tips. Kom ihåg att vissa av lösningarna fungerar bäst när du använder en serieplan. Det uppenbara sättet att tvinga fram detta är med en MAXDOP 1-frågetips. Och det är rätt väg att gå om du ibland vill möjliggöra parallellitet och ibland inte. Men vad händer om du alltid vill tvinga fram en serieplan när du använder funktionen, om än ett mindre troligt scenario?
Det finns ett knep för att uppnå detta. Användning av en icke-inlineable skalär UDF i frågan är en parallellismhämmare. En av de skalära UDF-inlining-hämmarna anropar en inneboende funktion som är tidsberoende, såsom SYSDATETIME. Så här är ett exempel på en icke-inlinebar skalär UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Ett annat alternativ är att definiera en UDF med bara en konstant som det returnerade värdet och använda alternativet INLINE =AV i dess rubrik. Men det här alternativet är endast tillgängligt från och med SQL Server 2019, som introducerade skalär UDF-inlining. Med ovan föreslagna funktion kan du skapa den som den är med äldre versioner av SQL Server.
Ändra sedan definitionen av funktionen dbo.GetNumsAlanCharlieItzikBatch så att den har ett dummyanrop till dbo.MySYSDATETIME (definiera en kolumn baserad på den men hänvisa inte till kolumnen i den returnerade frågan), som så:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Du kan nu köra prestandatestet igen utan att ange MAXDOP 1 och fortfarande få en serieplan:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Det är dock viktigt att betona att alla frågor som använder den här funktionen nu kommer att få en serieplan. Om det finns någon chans att funktionen kommer att användas i frågor som kommer att dra nytta av parallella planer, bättre att inte använda det här tricket, och när du behöver en serieplan, använd helt enkelt MAXDOP 1.
Lösning av Joe Obbish
Joes lösning är ganska kreativ. Här är hans egen beskrivning av lösningen:
"Jag valde att skapa ett klustrade kolumnbutiksindex (CCI) med 134 217 728 rader med sekventiella heltal. Funktionen refererar till tabellen upp till 32 gånger för att få alla rader som behövs för resultatuppsättningen. Jag valde en CCI eftersom datan kommer att komprimeras bra (mindre än 3 byte per rad), du får batch-läge "gratis", och tidigare erfarenhet tyder på att det går snabbare att läsa sekventiella nummer från en CCI än att generera dem med någon annan metod. ”Som nämnts tidigare noterade Joe också att min ursprungliga prestandatestning var avsevärt skev på grund av de asynkroniserade nätverkets I/O-väntningar som genererades av att sända raderna till SSMS. Så alla tester som jag kommer att utföra här kommer att använda Alans idé med variabeltilldelningen. Se till att justera dina tester baserat på vad som bäst återspeglar din verkliga situation.
Här är koden Joe använde för att skapa tabellen dbo.GetNumsObbishTable och fylla den med 134 217 728 rader:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Det tog den här koden 1:04 minuter att slutföra på min maskin.
Du kan kontrollera utrymmesanvändningen för den här tabellen genom att köra följande kod:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Jag har använt ungefär 350 MB utrymme. Jämfört med de andra lösningarna som jag kommer att presentera i den här artikeln använder den här betydligt mer utrymme.
I SQL Servers columnstore-arkitektur är en radgrupp begränsad till 2^20 =1 048 576 rader. Du kan kontrollera hur många radgrupper som skapades för den här tabellen med hjälp av följande kod:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Jag har 128 radgrupper.
Här är koden med definitionen av dbo.GetNumsObbish-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
De 32 individuella frågorna genererar de osammanhängande 134 217 728 heltalsunderintervallen som, när de är förenade, producerar det fullständiga oavbrutna intervallet 1 till 4 294 967 296. Det som är riktigt smart med den här lösningen är WHERE-filtrets predikat som de enskilda frågorna använder. Kom ihåg att när SQL Server bearbetar en inline TVF, tillämpar den först parameterinbäddning och ersätter parametrarna med ingångskonstanter. SQL Server kan sedan optimera de frågor som producerar delområden som inte skär ingångsintervallet. Till exempel, när du begär inmatningsintervallet 1 till 100 000 000 är bara den första frågan relevant, och resten optimeras. Planen kommer då i detta fall att innebära en hänvisning till endast en instans av tabellen. Det är ganska briljant!
Låt oss testa funktionens prestanda med intervallet 1 till 100 000 000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Planen för denna fråga visas i figur 2.
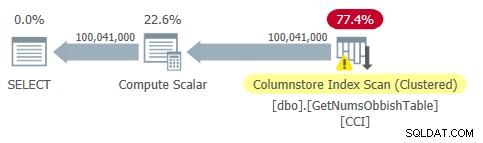 Figur 2:Plan för dbo.GetNumsObbish, 100 miljoner rader, oordnad
Figur 2:Plan för dbo.GetNumsObbish, 100 miljoner rader, oordnad
Observera att det faktiskt bara behövs en referens till tabellens CCI i denna plan.
Jag fick följande tidsstatistik för denna exekvering:
Det är ganska imponerande och mycket snabbare än något annat som jag har testat.
Här är I/O-statistiken som jag fick för den här exekveringen:
Tabell 'GetNumsObbishTable'. Scan count 1, logiskt läser 0, fysiskt läser 0, sidserver läser 0, read-ahead läser 0, sidserver läser framåt läser 0, lob logiskt läser 32928 , lob fysisk läser 0, lob sidserver läser 0, lob read-ahead läser 0, lob sidserver läser framåt 0.Tabell 'GetNumsObbishTable'. Segment lyder 96 , segment hoppade över 32.
I/O-profilen för den här lösningen är en av dess nackdelar jämfört med de andra, och ådrar sig över 30K lob logiska läsningar för den här exekveringen.
För att se att när du korsar flera 134 217 728 heltals underintervall kommer planen att involvera flera referenser till tabellen, fråga efter funktionen med intervallet 1 till 400 000 000, till exempel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Planen för detta utförande visas i figur 3.
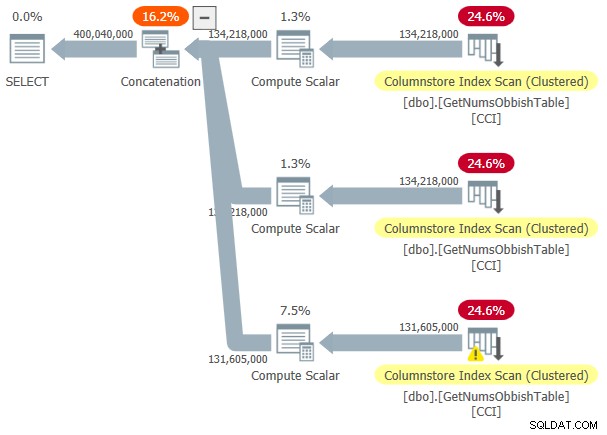 Figur 3:Plan för dbo.GetNumsObbish, 400 miljoner rader, oordnad
Figur 3:Plan för dbo.GetNumsObbish, 400 miljoner rader, oordnad
Det begärda intervallet korsade tre 134 217 728 heltals underintervall, därför visar planen tre referenser till tabellens CCI.
Här är tidsstatistiken som jag fick för den här exekveringen:
CPU-tid =20610 ms, förfluten tid =20628 ms.Och här är dess I/O-statistik:
Tabell 'GetNumsObbishTable'. Scan count 3, logisk läser 0, fysisk läser 0, sidserver läser 0, read-ahead läser 0, sidserver läser framåt läser 0, lob logisk läser 131026 , lob fysisk läser 0, lob sidserver läser 0, lob read-ahead läser 0, lob sidserver läser framåt 0.Tabell 'GetNumsObbishTable'. Segment läser 382 , segment hoppade över 2.
Den här gången resulterade frågekörningen i över 130 000 logiska läsningar.
Om du klarar av I/O-kostnaderna och inte behöver bearbeta nummerserien på ett ordnat sätt, är detta en utmärkt lösning. Men om du behöver bearbeta serien i ordning kommer denna lösning att resultera i en sorteringsoperator i planen. Här är ett test som begär det beställda resultatet:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Planen för detta utförande visas i figur 4.
 Figur 4:Plan för dbo.GetNumsObbish, 100 miljoner rader, beställda
Figur 4:Plan för dbo.GetNumsObbish, 100 miljoner rader, beställda
Här är tidsstatistiken som jag fick för den här exekveringen:
CPU-tid =44516 ms, förfluten tid =34836 ms.Som du kan se försämrades prestandan avsevärt när körtiden ökade med en storleksordning på grund av den explicita sorteringen.
Här är I/O-statistiken som jag fick för den här exekveringen:
Tabell 'GetNumsObbishTable'. Scan count 4, logiskt läser 0, fysiskt läser 0, sidserver läser 0, read-ahead läser 0, sidserver läser framåt läser 0, lob logiskt läser 32928 , lob fysisk läser 0, lob sidserver läser 0, lob read-ahead läser 0, lob sidserver läser framåt 0.Tabell 'GetNumsObbishTable'. Segment lyder 96 , segment hoppade över 32.
Tabell 'Arbetsbord'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, sidserver läser 0, read-ahead läser 0, sidserver läser framåt läser 0, lob logiskt läser 0, lob fysisk läser 0, lob sidserver läser 0, lob läs- ahead läser 0, lob page server read-ahead läser 0.
Observera att en arbetstabell dök upp i utdata från STATISTICS IO. Det beror på att en sort potentiellt kan spilla till tempdb, i vilket fall den skulle använda en arbetstabell. Den här exekveringen spilldes inte, därför är siffrorna alla nollor i denna post.
Lösning av John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 postade en lösning som bara är vacker i sin enkelhet. Dessutom innehåller den idéer och förslag från andra lösningar av Dave, Joe, Alan, Charlie och mig själv.
Precis som med Joes lösning bestämde sig John för att använda en CCI för att få en hög nivå av komprimering och "gratis" batchbearbetning. Bara John bestämde sig för att fylla tabellen med 4B rader med någon dummy NULL-markör i en bitkolumn och låta ROW_NUMBER-funktionen generera siffrorna. Eftersom de lagrade värdena är desamma behöver du med komprimering av upprepade värden betydligt mindre utrymme, vilket resulterar i betydligt mindre I/O jämfört med Joes lösning. Columnstore-komprimering hanterar upprepade värden mycket bra eftersom den kan representera varje sådan på varandra följande sektion inom en radgrupps kolumnsegment endast en gång tillsammans med antalet upprepade händelser i följd. Eftersom alla rader har samma värde (markören NULL), behöver du teoretiskt sett bara en förekomst per radgrupp. Med 4B rader bör du sluta med 4 096 radgrupper. Var och en bör ha ett enda kolumnsegment, med mycket litet utrymmesanvändningsbehov.
Här är koden för att skapa och fylla i tabellen, implementerad som en CCI med arkivkomprimering:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Den största nackdelen med denna lösning är den tid det tar att fylla i tabellen. Det tog den här koden 12:32 minuter att slutföra på min maskin när man tillåter parallellism och 15:17 minuter när man tvingar fram en serieplan.
Observera att du kan arbeta med att optimera databelastningen. Till exempel testade John en lösning som laddade raderna med hjälp av 32 samtidiga anslutningar med OSTRESS.EXE, var och en körde 128 omgångar med insättningar av 2^20 rader (max radgruppstorlek). Denna lösning sänkte Johns laddningstid till en tredjedel. Här är koden John använde:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"MED L0 AS (VÄLJ CAST(NULL SOM BIT) SOM b FRÅN (VÄRDEN(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (VÄLJ A.b FRÅN L0 SOM A CROSS JOIN L0 AS B), L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B), noll(b) AS (VÄLJ A.b FRÅN L2 SOM A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Ändå är laddningstiden i minuter. Den goda nyheten är att du bara behöver utföra denna dataladdning en gång.
Den stora nyheten är den lilla mängd utrymme som behövs för bordet. Använd följande kod för att kontrollera utrymmesanvändningen:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Jag fick 1,64 MB. Det är fantastiskt med tanke på att tabellen har 4B rader!
Använd följande kod för att kontrollera hur många radgrupper som skapades:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Som förväntat är antalet radgrupper 4 096.
Funktionsdefinitionen för dbo.GetNumsJohn2DaveObbishAlanCharlieItzik blir då ganska enkel:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Som du kan se använder en enkel fråga mot tabellen funktionen ROW_NUMBER för att beräkna basradnumren (radnummerkolumnen), och sedan använder den yttre frågan samma uttryck som i dbo.GetNumsAlanCharlieItzikBatch för att beräkna rn, op och n. Även här är både rn och n ordningsbevarande med avseende på rownum.
Låt oss testa funktionens prestanda:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Jag fick planen som visas i figur 5 för det här utförandet.
 Figur 5:Plan för dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figur 5:Plan för dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Här är tidsstatistiken som jag fick för det här testet:
CPU-tid =7593 ms, förfluten tid =7590 ms.
Som du kan se är exekveringstiden inte lika snabb som med Joes lösning, men den är fortfarande snabbare än alla andra lösningar som jag har testat.
Här är I/O-statistiken som jag fick för detta test:
Tabell 'NullBits4B'. Segment lyder 96 , segment hoppade över 0
Observera att I/O-kraven är betydligt lägre än med Joes lösning.
Det andra bra med den här lösningen är att när du behöver bearbeta den beställda nummerserien så betalar du inget extra. Det beror på att det inte kommer att resultera i en explicit sorteringsoperation i planen, oavsett om du beställer resultatet efter rn eller n.
Här är ett test för att visa detta:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Du får samma plan som visas tidigare i figur 5.
Här är tidsstatistiken som jag fick för detta test;
CPU-tid =7578 ms, förfluten tid =7582 ms.Och här är I/O-statistiken:
Tabell 'NullBits4B'. Scan count 1, logisk läser 0, fysisk läser 0, sidserver läser 0, read-ahead läser 0, sidserver läser framåt läser 0, lob logisk läser 194 , lob fysisk läser 0, lob sidserver läser 0, lob read-ahead läser 0, lob sidserver läser framåt 0.Tabell 'NullBits4B'. Segment lyder 96 , segment hoppade över 0.
De är i princip samma som i testet utan beställning.
Lösning 2 av John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
Johns lösning är snabb och enkel. Det är fantastiskt. Den enda nackdelen är laddningstiden. Ibland kommer detta inte att vara ett problem eftersom laddningen bara sker en gång. Men om det är ett problem kan du fylla tabellen med 102 400 rader istället för 4B rader och använda en korskoppling mellan två instanser av tabellen och ett TOP-filter för att generera det önskade maximala antalet 4B rader. Observera att för att få 4B rader skulle det räcka med att fylla tabellen med 65 536 rader och sedan tillämpa en korskoppling; men för att få data att komprimeras omedelbart – i motsats till att laddas in i ett radlagringsbaserat deltalager – måste du ladda tabellen med minst 102 400 rader.
Här är koden för att skapa och fylla i tabellen:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Laddningstiden är försumbar — 43 ms på min maskin.
Kontrollera storleken på tabellen på disken:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Jag har 56 KB utrymme som behövs för data.
Kontrollera antalet radgrupper, deras tillstånd (komprimerade eller öppna) och deras storlek:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Jag fick följande utdata:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Endast en radgrupp behövs här; den är komprimerad och storleken är försumbara 293 byte.
Om du fyller i tabellen med en rad mindre (102 399), får du en radbutiksbaserad okomprimerad öppen deltabutik. I ett sådant fall rapporterar sp_spaceused datastorlek på disk på över 1 MB, och sys.column_store_row_groups rapporterar följande information:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Så se till att du fyller tabellen med 102 400 rader!
Här är definitionen av funktionen dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
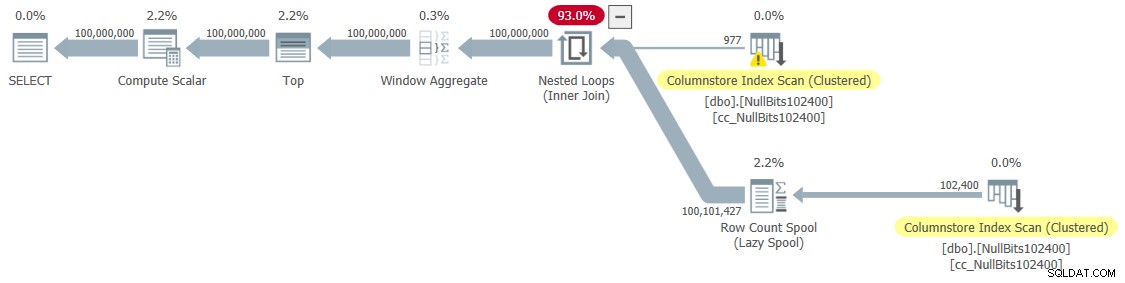 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
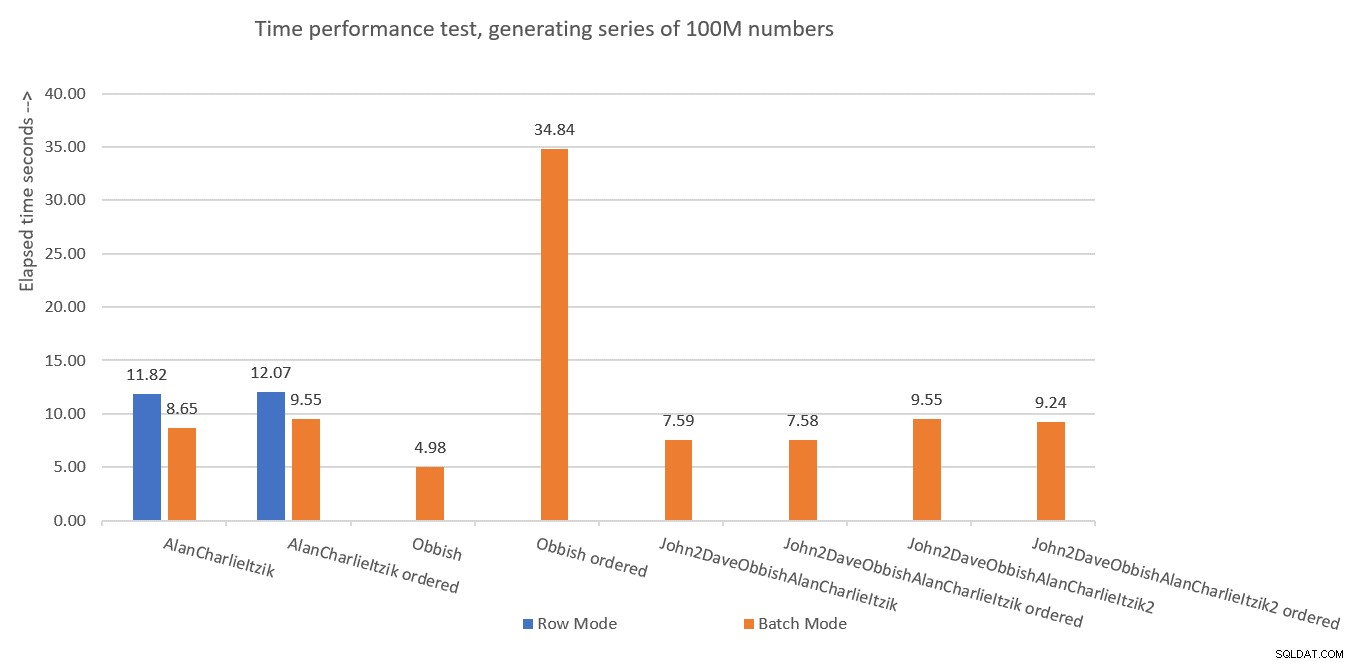 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
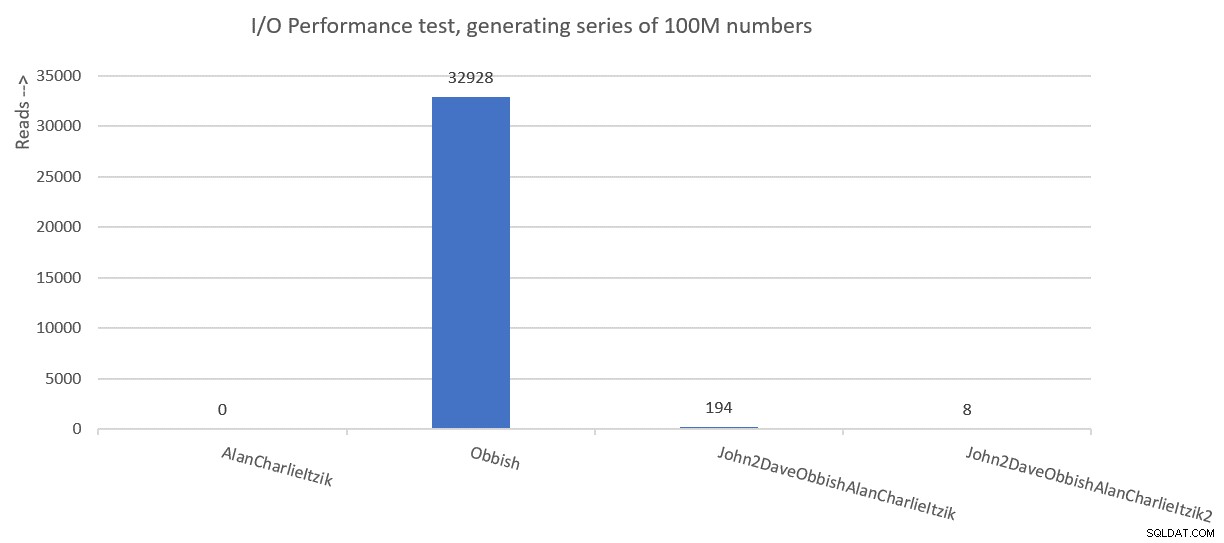 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.