ANY aggregat är inget vi kan skriva direkt i Transact SQL. Det är endast en intern funktion som används av frågeoptimeraren och exekveringsmotorn.
Jag är personligen ganska förtjust i ANY sammanlagd, så det var lite nedslående att höra att det är trasigt på ett ganska fundamentalt sätt. Den speciella smaken av "trasig" jag syftar på här är sorten med fel resultat.
I det här inlägget tar jag en titt på två särskilda platser där ANY aggregat dyker ofta upp, visar fel resultatproblem och föreslår lösningar där det behövs.
För bakgrund om ANY aggregat, se mitt tidigare inlägg Odokumenterade frågeplaner:ANY-aggregatet.
1. En rad per gruppfrågor
Detta måste vara ett av de vanligaste frågekraven i dag, med en mycket välkänd lösning. Du skriver förmodligen den här typen av fråga varje dag, automatiskt efter mönstret, utan att egentligen tänka på det.
Tanken är att numrera den inmatade uppsättningen rader med ROW_NUMBER fönsterfunktion, partitionerad av grupperingskolumnen eller -kolumnerna. Det är insvept i ett vanligt tabelluttryck eller härledd tabell , och filtreras ner till rader där det beräknade radnumret är lika med en. Sedan ROW_NUMBER startar om vid en för varje grupp, vilket ger oss den nödvändiga en rad per grupp.
Det är inga problem med det allmänna mönstret. Typen av en rad per gruppfråga som är föremål för ANY aggregerat problem är det där vi inte bryr oss om vilken speciell rad som är vald från varje grupp.
I så fall är det inte klart vilken kolumn som ska användas i den obligatoriska ORDER BY sats i ROW_NUMBER fönsterfunktion. När allt kommer omkring, vi bryr oss uttryckligen inte vilken rad som är vald. Ett vanligt tillvägagångssätt är att återanvända PARTITION BY kolumn(er) i ORDER BY klausul. Det är här problemet kan uppstå.
Exempel
Låt oss titta på ett exempel med en leksaksdatauppsättning:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Kravet är att returnera en komplett rad med data från varje grupp, där gruppmedlemskap definieras av värdet i kolumn c1 .

Följer ROW_NUMBER mönster, kan vi skriva en fråga som följande (lägg märke till ORDER BY sats i ROW_NUMBER fönsterfunktionen matchar PARTITION BY klausul):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Som presenterat körs den här frågan framgångsrikt, med korrekta resultat. Resultaten är tekniskt sett icke-deterministiska eftersom SQL Server giltigt kunde returnera vilken som helst av raderna i varje grupp. Ändå, om du kör den här frågan själv, är det ganska troligt att du ser samma resultat som jag:
Exekveringsplanen beror på vilken version av SQL Server som används och beror inte på databaskompatibilitetsnivå.
På SQL Server 2014 och tidigare är planen:

För SQL Server 2016 eller senare ser du:

Båda planerna är säkra, men av olika anledningar. Distinkt sortering planen innehåller en ANY aggregerad, men Distinkt sortering Operatörsimplementering visar inte felet.
Den mer komplexa SQL Server 2016+-planen använder inte ANY samlas överhuvudtaget. Sortera placerar raderna i den ordning som behövs för radnumreringsoperationen. Segmentet operatören sätter en flagga i början av varje ny grupp. Sequence Project beräknar radnumret. Slutligen, Filtret operatorn skickar endast de rader som har ett beräknat radnummer på ett.
Feget
För att få felaktiga resultat med denna datamängd måste vi använda SQL Server 2014 eller tidigare, och ANY aggregat måste implementeras i ett Strömaggregat eller Eager Hash Aggregate operator (Flow Distinct Hash Match Aggregate producerar inte felet).
Ett sätt att uppmuntra optimeraren att välja ett Stream Aggregate istället för Distinkt sortering är att lägga till ett klustrat index för att ge ordning efter kolumn c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Efter den ändringen blir genomförandeplanen:

ANY aggregat är synliga i Egenskaper fönstret när Stream Aggregate operatören är vald:

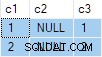
Resultatet av frågan är:
Det här är fel . SQL Server har returnerat rader som inte existerar i källdata. Det finns inga källrader där c2 = 1 och c3 = 1 till exempel. Som en påminnelse är källdata:
Exekveringsplanen beräknar felaktigt separat ANY aggregat för c2 och c3 kolumner, ignorerar nollor. Varje sammanställs oberoende returnerar den första icke-null värde den stöter på, vilket ger ett resultat där värdena för c2 och c3 kommer från olika källrader . Detta är inte vad den ursprungliga SQL-frågaspecifikationen begärde.
Samma felaktiga resultat kan produceras med eller utan det klustrade indexet genom att lägga till en OPTION (HASH GROUP) tips om att skapa en plan med ett Eager Hash Aggregate istället för ett Strömaggregat .
Villkor
Detta problem kan bara uppstå när flera ANY aggregat finns och den aggregerade informationen innehåller nollvärden. Som nämnts påverkar problemet bara Stream Aggregate och Eager Hash Aggregate operatörer; Distinkt sortering och Flödes distinkt påverkas inte.
SQL Server 2016 och framåt anstränger sig för att undvika att införa flera ANY aggregerar för frågemönstret för en rad per grupp radnumrering när källkolumnerna är nullbara. När detta händer kommer exekveringsplanen att innehålla Segment , Sekvensprojekt och Filter operatörer istället för ett aggregat. Denna planform är alltid säker, eftersom ingen ANY aggregat används.
Reproducera buggen i SQL Server 2016+
SQL Server-optimeraren är inte perfekt för att upptäcka när en kolumn ursprungligen var begränsad till att vara NOT NULL kan fortfarande producera ett noll mellanvärde genom datamanipulationer.
För att återskapa detta börjar vi med en tabell där alla kolumner deklareras som NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Vi kan producera nollvärden från denna datamängd på många sätt, varav de flesta kan upptäcka optimeraren framgångsrikt, och så undviker vi att introducera ANY samlas under optimering.
Ett sätt att lägga till nollor som råkar glida under radarn visas nedan:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
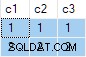
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Den frågan ger följande utdata:
Nästa steg är att använda den frågespecifikationen som källdata för standardfrågan "en rad per grupp":
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; På alla versioner av SQL Server, som producerar följande plan:
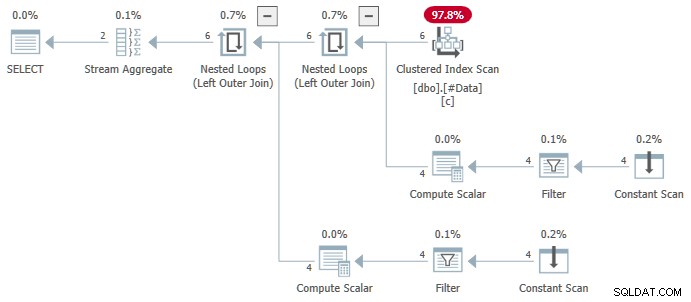
Strömaggregatet innehåller flera ANY samlas, och resultatet är fel . Ingen av de returnerade raderna visas i källdatauppsättningen:
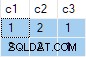
db<>fiddle online demo
Lösning
Den enda helt tillförlitliga lösningen tills det här felet är åtgärdat är att undvika mönstret där ROW_NUMBER har samma kolumn i ORDER BY sats som är i PARTITION BY klausul.
När vi inte bryr oss vilket en rad väljs från varje grupp, det är olyckligt att en ORDER BY klausul behövs överhuvudtaget. Ett sätt att kringgå problemet är att använda en körtidskonstant som ORDER BY @@SPID i fönsterfunktionen.
2. Icke-deterministisk uppdatering
Problemet med flera ANY aggregat på nullbara indata är inte begränsat till frågemönster med en rad per grupp. Frågeoptimeraren kan introducera en intern ANY samlas under ett antal omständigheter. Ett av dessa fall är en icke-deterministisk uppdatering.
En icke-deterministisk uppdatering är där uttalandet inte garanterar att varje målrad kommer att uppdateras högst en gång. Med andra ord finns det flera källrader för minst en målrad. Dokumentationen varnar uttryckligen för detta:
Var försiktig när du anger FROM-satsen för att tillhandahålla kriterierna för uppdateringsåtgärden.Resultaten av en UPDATE-sats är odefinierad om satsen innehåller en FROM-sats som inte är specificerad på ett sådant sätt att endast ett värde är tillgängligt för varje kolumnförekomst som uppdateras, att är om UPDATE-satsen inte är deterministisk.
För att hantera en icke-deterministisk uppdatering grupperar optimeraren raderna efter en nyckel (index eller RID) och tillämpar ANY aggregeras till de återstående kolumnerna. Grundidén där är att välja en rad från flera kandidater och använda värden från den raden för att utföra uppdateringen. Det finns uppenbara paralleller till föregående ROW_NUMBER problem, så det är ingen överraskning att det är ganska lätt att visa en felaktig uppdatering.
Till skillnad från föregående nummer tar SQL Server för närvarande inga särskilda steg för att undvika flera ANY aggregerar på nollbara kolumner när en icke-deterministisk uppdatering utförs. Följande gäller därför alla SQL Server-versioner , inklusive SQL Server 2019 CTP 3.0.
Exempel
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
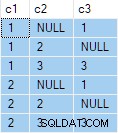
SELECT * FROM @Target AS T; db<>fiddle online demo
Logiskt sett bör den här uppdateringen alltid ge ett fel:Måltabellen tillåter inte nollvärden i någon kolumn. Oavsett vilken matchande rad som väljs från källtabellen, ett försök att uppdatera kolumn c2 eller c3 till null måste inträffa.
Tyvärr lyckas uppdateringen, och det slutliga tillståndet för måltabellen är inkonsekvent med de angivna data:
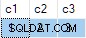
Jag har rapporterat detta som ett fel. Arbetet runt är att undvika att skriva icke-deterministisk UPDATE uttalanden, alltså ANY aggregat behövs inte för att lösa tvetydigheten.
Som nämnts kan SQL Server introducera ANY aggregeras under fler omständigheter än de två exemplen som ges här. Om detta händer när den aggregerade kolumnen innehåller nollvärden finns det risk för felaktiga resultat.