Ett engagemang för prestationsjustering kan sluta med att ta många varv när du arbetar igenom det – allt beror på vad som dyker upp som problemet och vad data säger dig. Vissa dagar landar den på en specifik fråga, eller en uppsättning frågor, som kan förbättras med index – antingen nya eller modifieringar av befintliga index. En av mina favoritdelar av trimning är att arbeta med index och när jag tänkte på det här inlägget blev jag frestad att kalla indexjustering som en "enklare" uppgift ... men det är det verkligen inte.
Jag tänker på indexjustering som en konst och en vetenskap. Du måste försöka tänka som optimeraren, och du måste förstå tabellschemat och frågan (eller frågorna) du försöker ställa in. Båda dessa är datadrivna och därmed i kategorin vetenskap. Konstkomponenten spelar in när du tänker på den andra index på tabellen och alla den andra frågor som involverar tabellen som kan påverkas av indexändringar.
Steg 1 :Identifiera frågan och granska planen
När jag identifierar en fråga som kan dra nytta av ett index får jag omedelbart dess plan. Jag hämtar ofta exekveringsplanen från planens cache eller frågebutik och använder sedan SSMS för att få exekveringsplanen plus Run-Time Statistics (aka Faktisk Execution Plan). Många gånger är formen på de två planerna densamma; men det är ingen garanti, det är därför jag gillar att se båda.
Planen kan ha en saknad indexrekommendation, den kan ha en klustrad indexskanning (eller heapscan om det inte finns något klustrat index), den kan använda ett icke-klustrat index men sedan ha en uppslagning för att hämta ytterligare kolumner. Att fixa vart och ett av dessa problem individuellt låter ganska enkelt. Lägg bara till det saknade indexet, eller hur? Om det finns en skanning av ett klustrat index eller en hög, skapa indexet som jag behöver för frågan och vara klar? Eller om det finns ett index som används men det går till tabellen för att hämta de ytterligare kolumnerna, lägg bara till kolumnerna i det indexet?
Det är vanligtvis inte så lätt, och även när det är så går jag fortfarande igenom processen som jag beskriver här.
Steg 2:Bestäm vilka tabeller som ska granskas
Nu när jag har min fråga måste jag ta reda på vilka tabeller som inte är korrekt indexerade. Förutom att se över planen så aktiverar jag även IO- och TIME-statistik i SSMS. Detta är förmodligen gammaldags av mig, eftersom utförandeplaner innehåller mer och mer information – inklusive varaktighet och IO-nummer per operatör – med varje release, men jag gillar IO-statistiken eftersom jag snabbt kan se läsningarna för varje tabell. För frågor som är komplexa med flera kopplingar, eller underfrågor, eller CTE, eller kapslade vyer, förståelse för var IO och/eller tid spenderas i frågestationerna där jag tillbringar min tid. När det är möjligt från denna punkt, tar jag den större, komplexa frågan och parar den ner till den del som orsakar det största problemet.
Till exempel, om det finns en fråga som ansluter till 10 tabeller och har två underfrågor, hjälper planen (tillsammans med information om IO och varaktighet) mig att identifiera var problemet finns. Sedan kommer jag att dra ut den delen av frågan – den problematiska tabellen och kanske ett par andra som den ansluter till – och fokusera på det. Ibland är det bara underfrågan, så jag börjar där.
Steg 3 :Titta på befintliga index
Med frågan (eller en del av frågan) definierad fokuserar jag på de befintliga indexen för de inblandade tabellerna. För detta steg litar jag på Kimberlys version av sp_helpindex. Jag föredrar mycket hennes version framför standarden sp_helpindex eftersom den också listar INKLUDERADE kolumner och filterdefinitionen (om en sådan finns). Beroende på antalet index som dyker upp för en tabell kommer jag ofta att kopiera detta och klistra in det i Excel och sedan beställa baserat på indexnyckeln och sedan de inkluderade kolumnerna. Detta gör att jag snabbt kan hitta eventuella övertaligheter.
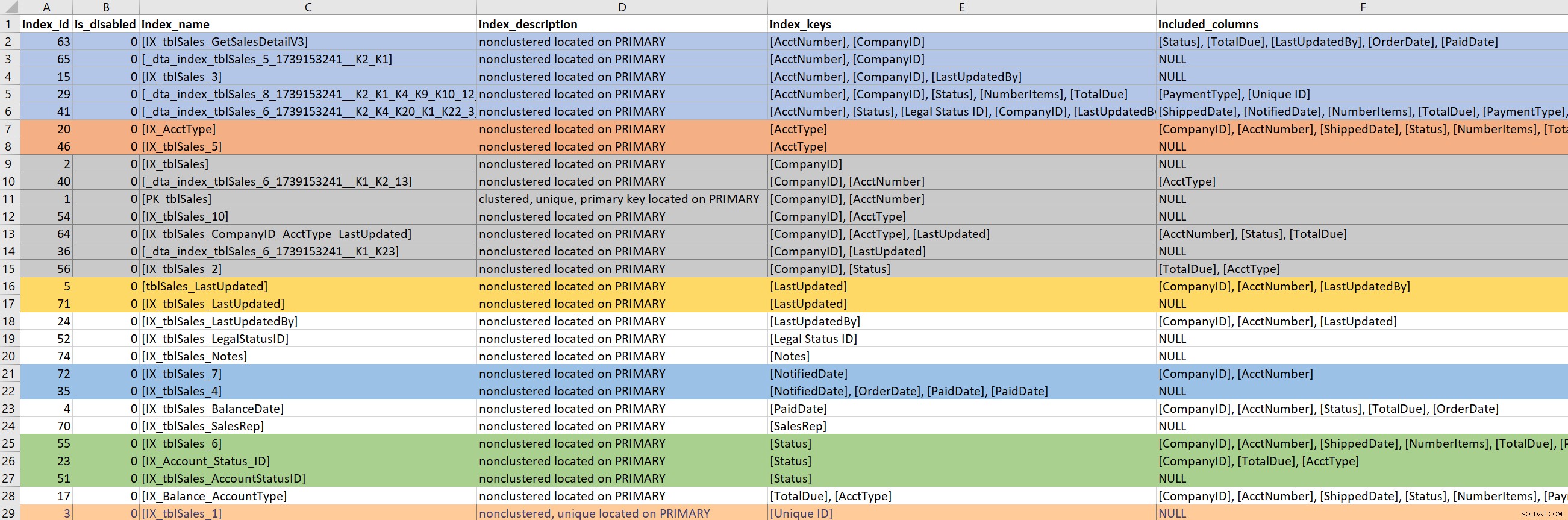
Baserat på exemplet ovan finns det sju index som börjar med CompanyID, fem som börjar med AcctNumber och några andra potentiella redundanser. Även om det verkar idealiskt att bara ha en index som leder på en viss kolumn (t.ex. CompanyID), för vissa frågemönster som inte räcker.
När jag tittar på befintliga index är det väldigt lätt att gå ner i ett kaninhål. Jag tittar på utgången ovan och börjar genast fråga varför det finns sju index som börjar med CompanyID, och jag vill veta vem som skapade dem, och varför, och för vilken fråga. Men... om min problematiska fråga inte använder CompanyID, borde jag bry mig? Ja... för i allmänhet är jag där för att förbättra prestanda, och om det innebär att titta på andra index på bordet längs vägen, så är det så. Men det är här det är lätt att tappa koll på tiden (och det verkliga syftet).
Om min problematiska fråga behöver ett index som leder på PaidDate, behöver jag bara ta itu med ett befintligt index. Om min problematiska fråga behöver ett index som leder på AcctNumber blir det knepigt. När befintliga index liksom täcker en fråga och jag funderar på att utöka ett index (lägga till fler kolumner) eller konsolidera (sammanfoga två eller kanske tre index till ett), då måste jag gräva i mig.
Steg 4:Indexera användningsstatistik
Jag tycker att många människor inte fångar statistik över indexanvändning på en kontinuerlig basis. Detta är olyckligt, eftersom jag tycker att data är till hjälp när jag bestämmer vilka index som ska behållas och vilka som ska släppas eller slås samman. I det fall jag inte har historisk användningsstatistik kontrollerar jag åtminstone hur användningen ser ut för närvarande (sedan den senaste omstarten av tjänsten):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
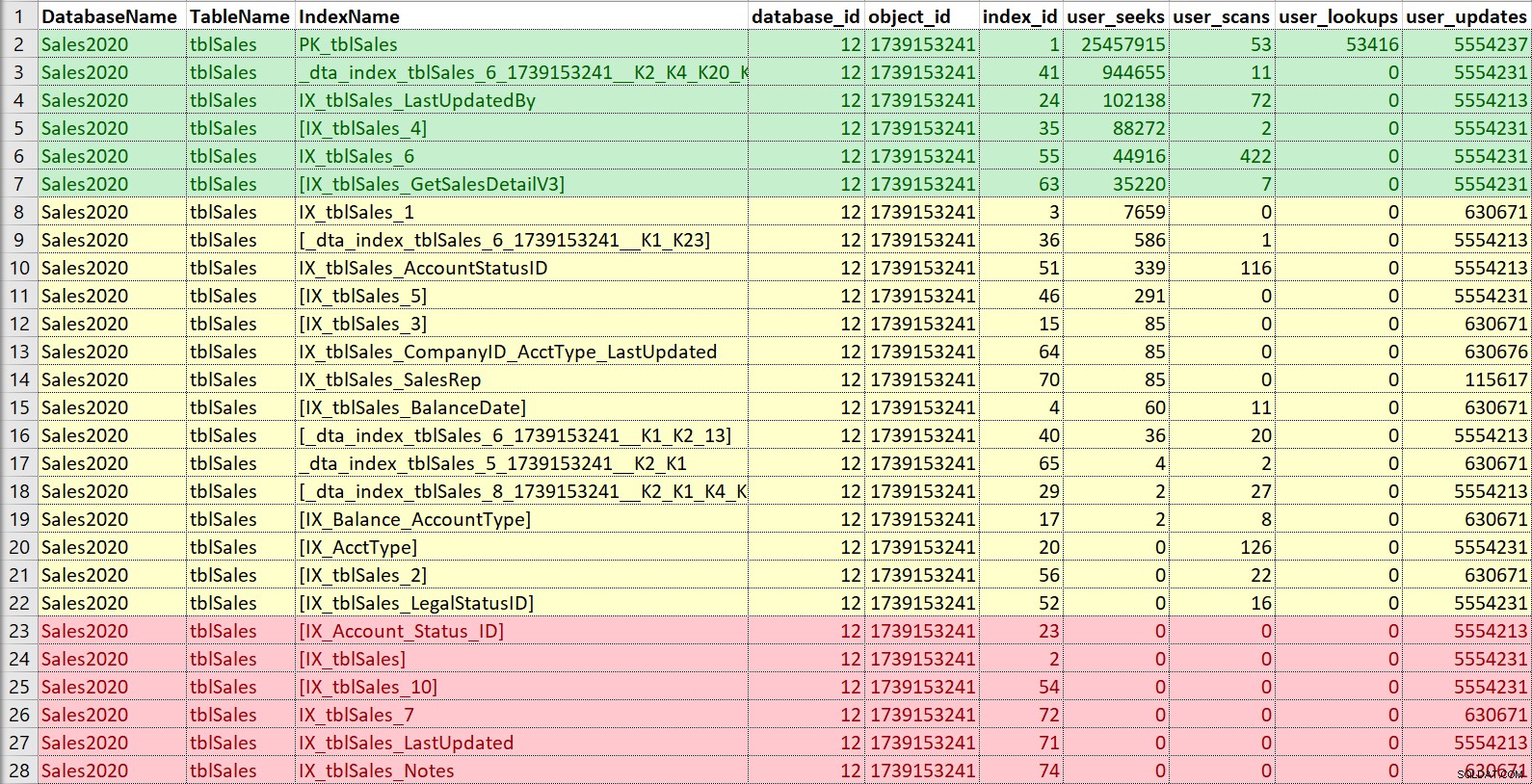
Återigen, jag gillar att lägga in detta i Excel, sortera efter sökningar och sedan skannar, och även ta del av uppdateringar. För det här exemplet är indexen i rött de utan sökningar, skanningar eller uppslagningar... bara uppdateringar. De är kandidater för att bli inaktiverade och potentiellt avbrutna, om de verkligen inte används (återigen, att ha användningshistorik skulle hjälpa här). Indexen i grönt används definitivt, jag vill behålla dem (även om de kanske i vissa fall kan justeras). De i gult... vissa används typ, andra används knappt. Återigen, historik skulle vara till hjälp här, eller sammanhang från andra – ibland kan ett index vara avgörande för en rapport eller process som inte körs hela tiden.
Om jag bara vill modifiera eller lägga till ett nytt index, jämfört med sann sanering och konsolidering, är jag mest bekymrad över alla index som liknar det jag vill lägga till eller ändra. Jag kommer dock att se till att påpeka användningsinformationen för kunden och, om tiden tillåter, hjälpa till med den övergripande indexeringsstrategin för tabellen.
Vad är nästa steg?
Vi är inte klara! Det här är del 1 av min strategi för indexjustering, och min nästa del kommer att lista ut resten av mina steg. Under tiden, om du inte fångar statistik över indexanvändning, är det något du kan sätta på plats med hjälp av frågan ovan, eller en annan variant. Jag skulle rekommendera att fånga användningsstatistik för alla användardatabaser, inte bara en specifik tabell och databas som jag har gjort ovan, så ändra predikatet vid behov. Och slutligen, som en del av det schemalagda jobbet att ta en ögonblicksbild av informationen till en tabell, glöm inte ett annat steg för att rensa upp tabellen efter att data har funnits där ett tag (jag behåller den i minst sex månader; vissa kanske säger en år är nödvändigt).