
Jag blev nyligen utskälld för att antyda att i vissa fall kommer ett icke-klustrat index att prestera bättre för en viss fråga än det klustrade indexet. Den här personen uppgav att det klustrade indexet alltid är bäst eftersom det alltid täcker per definition, och att alla icke-klustrade index med några eller alla av samma nyckelkolumner alltid var överflödiga.
Jag håller gärna med om att det klustrade indexet alltid täcker (och för att undvika tvetydigheter här kommer vi att hålla oss till diskbaserade tabeller med traditionella B-trädindex).
 Jag håller dock inte med om att ett klustrat index alltid är snabbare än ett icke-klustrat index. Jag håller inte med om att det alltid är överflödigt att skapa ett icke-klustrat index eller en unik begränsning som består av samma (eller några av samma) kolumner i klustringsnyckeln.
Jag håller dock inte med om att ett klustrat index alltid är snabbare än ett icke-klustrat index. Jag håller inte med om att det alltid är överflödigt att skapa ett icke-klustrat index eller en unik begränsning som består av samma (eller några av samma) kolumner i klustringsnyckeln.
Låt oss ta det här exemplet, Warehouse.StockItemTransactions , från WideWorldImporters. Det klustrade indexet implementeras genom en primärnyckel på bara StockItemTransactionID kolumn (ganska typiskt när du har något slags surrogat-ID genererat av en IDENTITET eller en SEKVENS).
Det är en ganska vanlig sak att kräva en räkning av hela tabellen (även om det i många fall finns bättre sätt). Detta kan vara för tillfällig inspektion eller som en del av ett pagineringsförfarande. De flesta kommer att göra så här:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Med det aktuella schemat kommer detta att använda ett icke-klustrat index:
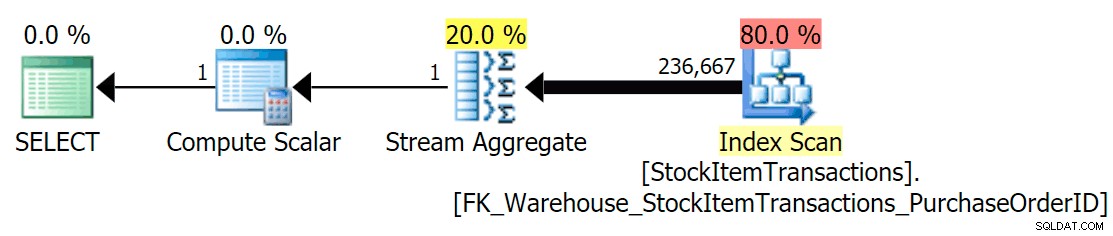
Vi vet att det icke-klustrade indexet inte innehåller alla kolumner i det klustrade indexet. Räkneoperationen behöver bara vara säker på att alla rader är inkluderade, utan att bry sig om vilka kolumner som finns, så SQL Server kommer vanligtvis att välja indexet med det minsta antalet sidor (i detta fall har det valda indexet ~414 sidor).
Låt oss nu köra frågan igen, denna gång genom att jämföra den med en antydd fråga som tvingar fram användningen av det klustrade indexet.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Vi får en nästan identisk planform, men vi kan se en enorm skillnad i läsningar (414 för det valda indexet mot 1 982 för det klustrade indexet):
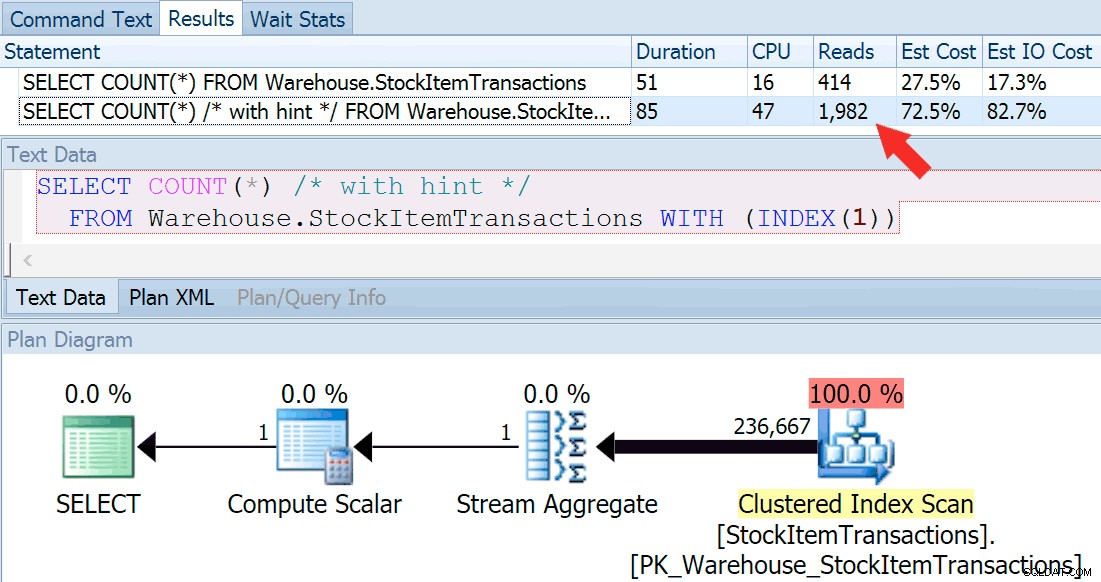
Varaktigheten är något högre för det klustrade indexet, men skillnaden är försumbar när vi har att göra med en liten mängd cachad data på en snabb disk. Den avvikelsen skulle vara mycket mer uttalad med mer data, på en långsam disk eller på ett system med minnestryck.
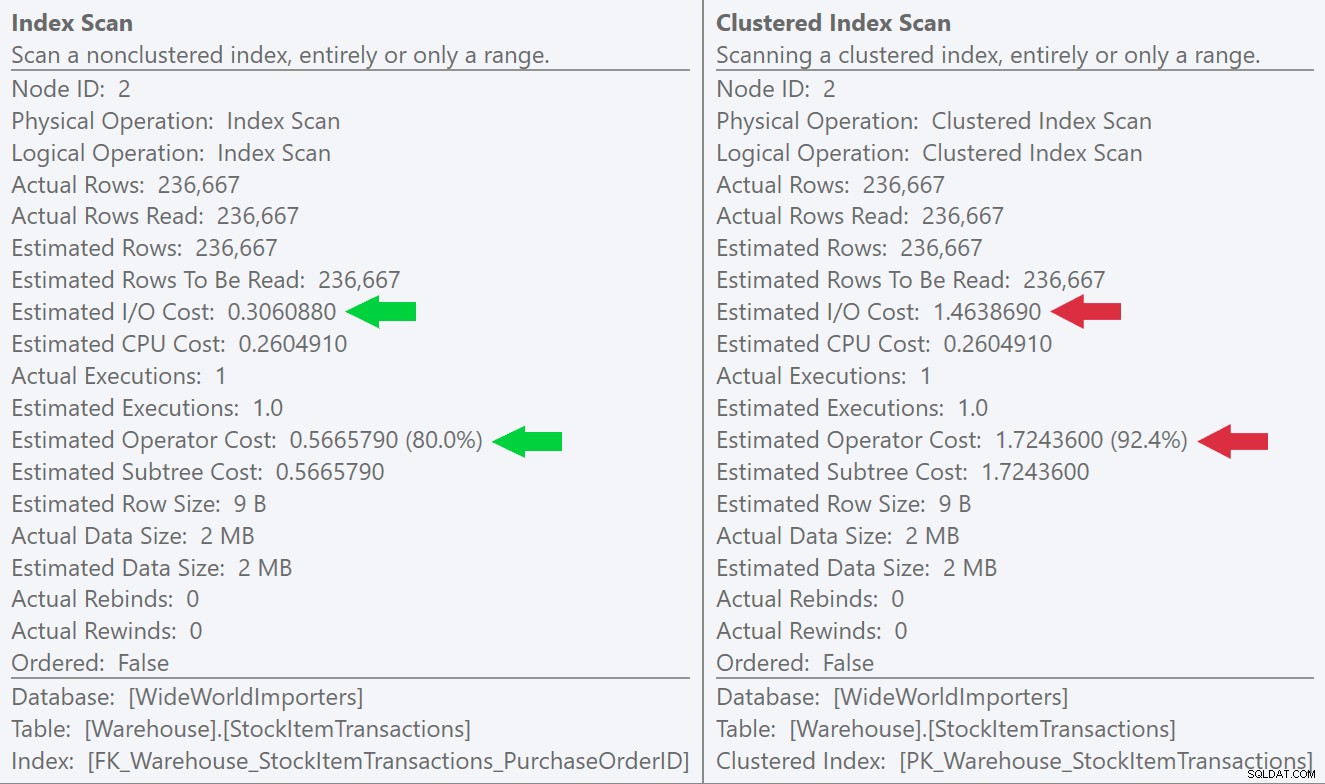
Om vi tittar på verktygstipsen för skanningsoperationerna kan vi se att även om antalet rader och uppskattade CPU-kostnader är identiska, kommer den stora skillnaden från den uppskattade I/O-kostnaden (eftersom SQL Server vet att det finns fler sidor i klustrade index än det icke-klustrade indexet):
Vi kan se denna skillnad ännu tydligare om vi skapar ett nytt, unikt index på bara ID-kolumnen (gör det "överflödigt" med det klustrade indexet, eller hur?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
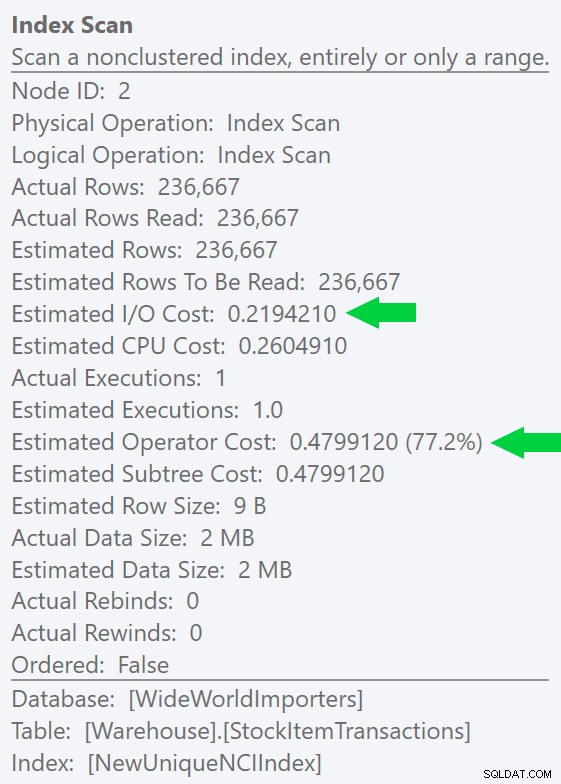 Att köra en liknande fråga med ett explicit indextips ger samma planform, men en ännu lägre uppskattad I/O kostnad (och ännu lägre varaktighet) – se bilden till höger. Och om du kör den ursprungliga frågan utan ledtråden kommer du att se att SQL Server nu också väljer detta index.
Att köra en liknande fråga med ett explicit indextips ger samma planform, men en ännu lägre uppskattad I/O kostnad (och ännu lägre varaktighet) – se bilden till höger. Och om du kör den ursprungliga frågan utan ledtråden kommer du att se att SQL Server nu också väljer detta index.
Det kan tyckas självklart, men många skulle tro att det klustrade indexet är det bästa valet här. SQL Server kommer nästan alltid att i hög grad favorisera vilken metod som helst som ger det billigaste sättet att utföra all I/O, och i fallet med en fullständig genomsökning kommer det att vara det "smalaste" indexet. Detta kan också hända med båda typerna av sökningar (singleton och range scans), åtminstone när indexet täcker.
Nu, som alltid, gör det inte det på något sätt betyder att du bör gå och skapa ytterligare index på alla dina tabeller för att tillfredsställa räkningsfrågor. Det är inte bara ett ineffektivt sätt att kontrollera tabellstorleken (igen, se den här artikeln), utan ett index för stöd som måste betyda att du kör den frågan oftare än du uppdaterar data. Kom ihåg att varje index kräver utrymme på disk, utrymme på minne, och alla skrivningar mot tabellen måste också röra varje index (filtrerade index åt sidan).
Sammanfattning
Jag skulle kunna komma med många andra exempel som visar när en icke-klustrad kan vara användbar och värd kostnaden för underhåll, även när man duplicerar nyckelkolumnen(erna) i det klustrade indexet. Icke-klustrade index kan skapas med samma nyckelkolumner men i en annan nyckelordning, eller med olika ASC/DESC på själva kolumnerna för att bättre stödja en alternativ presentationsordning. Du kan också ha icke-klustrade index som bara bär en liten delmängd av raderna genom att använda ett filter. Slutligen, om du kan tillfredsställa dina vanligaste frågor med smalare, icke-klustrade index, är det också bättre för minnesförbrukningen.
Men egentligen är min poäng med den här serien bara att visa ett motexempel som illustrerar dårskapet i att göra allmänna uttalanden som denna. Jag lämnar er med en förklaring från Paul White som i ett DBA.SE-svar förklarar varför ett sådant icke-klusterat index faktiskt kan prestera mycket bättre än ett klustrat index. Detta gäller även när båda använder endera typen av sökning:
- Skillnaden mellan klustrad indexsökning och icke-klustrad indexsökning