Databaser är utformade på olika sätt. För det mesta kan vi använda "skolexempel":normalisera databasen så kommer allt att fungera bra. Men det finns situationer som kräver ett annat tillvägagångssätt. Vi kan ta bort referenser för att få mer flexibilitet. Men vad händer om vi måste förbättra prestandan när allt gjordes enligt boken? I så fall är denormalisering en teknik som vi bör överväga. I den här artikeln kommer vi att diskutera fördelarna och nackdelarna med denormalisering och vilka situationer som kan motivera det.
Vad är denormalisering?
Denormalisering är en strategi som används på en tidigare normaliserad databas för att öka prestandan. Tanken bakom det är att lägga till redundant data där vi tror att det kommer att hjälpa oss mest. Vi kan använda extra attribut i en befintlig tabell, lägga till nya tabeller eller till och med skapa instanser av befintliga tabeller. Det vanliga målet är att minska körtiden för utvalda frågor genom att göra data mer tillgänglig för frågorna eller genom att generera sammanfattade rapporter i separata tabeller. Den här processen kan ge några nya problem, och vi kommer att diskutera dem senare.
En normaliserad databas är utgångspunkten för denormaliseringsprocessen. Det är viktigt att skilja från databasen som inte har normaliserats och databasen som normaliserades först och sedan denormaliserades senare. Den andra är okej; den första är ofta resultatet av dålig databasdesign eller bristande kunskap.
Exempel:En normaliserad modell för ett mycket enkelt CRM
Modellen nedan kommer att fungera som vårt exempel:
Låt oss ta en snabb titt på tabellerna:
user_accountTabellen lagrar data om användare som loggar in på vår applikation (förenkling av modellen, roller och användarrättigheter utesluts från den).clientTabellen innehåller några grundläggande uppgifter om våra kunder.productTabellen visar produkter som erbjuds våra kunder.tasktabellen innehåller alla uppgifter vi har skapat. Du kan se varje uppgift som en uppsättning relaterade åtgärder mot kunder. Varje uppgift har sina relaterade samtal, möten och listor över erbjudna och sålda produkter.callochmeetingtabeller lagrar data om alla samtal och möten och relaterar dem till uppgifter och användare.- Ordböckerna
task_outcome,meeting_outcomeochcall_outcomeinnehålla alla möjliga alternativ för det slutliga tillståndet för en uppgift, möte eller samtal. - Den
product_offeredlagrar en lista över alla produkter som erbjöds kunder för vissa uppgifter medanproduct_soldinnehåller en lista över alla produkter som kunden faktiskt köpte. supply_orderTabellen lagrar data om alla beställningar vi har gjort ochproducts_on_orderTabellen visar produkter och deras kvantitet för specifika beställningar.-
writeoffTabellen är en lista över produkter som har skrivits av på grund av olyckor eller liknande (t.ex. trasiga speglar).
Databasen är förenklad men den är perfekt normaliserad. Du kommer inte att hitta några uppsägningar och det borde göra jobbet. Vi bör inte uppleva några prestandaproblem i alla fall, så länge vi arbetar med en relativt liten mängd data.
När och varför ska denormalisering användas
Som med nästan allt måste du vara säker på varför du vill tillämpa denormalisering. Du måste också vara säker på att vinsten från att använda den uppväger eventuell skada. Det finns några situationer när du definitivt bör tänka på denormalisering:
- Underhålla historik: Data kan ändras under tiden, och vi måste lagra värden som var giltiga när en post skapades. Vilken typ av förändringar menar vi? Tja, en persons för- och efternamn kan ändras; en kund kan också ändra sitt företagsnamn eller andra uppgifter. Uppgiftsinformation bör innehålla värden som var verkliga när en uppgift genererades. Vi skulle inte kunna återskapa tidigare data korrekt om detta inte hände. Vi skulle kunna lösa detta problem genom att lägga till en tabell som innehåller historiken för dessa ändringar. I så fall skulle en urvalsfråga som returnerar uppgiften och ett giltigt klientnamn bli mer komplicerad. Kanske är ett extra bord inte den bästa lösningen.
- Förbättra frågeprestanda: Vissa av frågorna kan använda flera tabeller för att komma åt data som vi ofta behöver. Tänk på en situation där vi skulle behöva ansluta 10 bord för att returnera kundens namn och de produkter som såldes till dem. Vissa tabeller längs vägen kan också innehålla stora mängder data. I så fall kanske det vore klokt att lägga till ett
client_idattribut direkt tillproducts_soldtabell. - Gör snabbare rapportering: Vi behöver viss statistik mycket ofta. Att skapa dem från livedata är ganska tidskrävande och kan påverka systemets övergripande prestanda. Låt oss säga att vi vill spåra kundförsäljning under vissa år för några eller alla kunder. Att generera sådana rapporter från livedata skulle "gräva" nästan hela databasen och sakta ner mycket. Och vad händer om vi använder den statistiken ofta?
- Beräkning av vanliga värden i förväg: Vi vill ha några värden färdigberäknade så att vi inte behöver generera dem i realtid.
Det är viktigt att påpeka att du inte behöver använda denormalisering om det inte finns några prestandaproblem i applikationen. Men om du märker att systemet saktar ner – eller om du är medveten om att detta kan hända – bör du tänka på att tillämpa denna teknik. Innan du börjar med det, överväg dock andra alternativ, som frågeoptimering och korrekt indexering. Du kan också använda denormalisering om du redan är i produktion, men det är bättre att lösa problem i utvecklingsfasen.
Vilka är nackdelarna med denormalisering?
Uppenbarligen är den största fördelen med denormaliseringsprocessen ökad prestanda. Men vi måste betala ett pris för det, och det priset kan bestå av:
- Diskutrymme: Detta förväntas eftersom vi kommer att ha dubbletter av data.
- Dataavvikelser: Vi måste vara mycket medvetna om att data nu kan ändras på mer än ett ställe. Vi måste justera varje del av dubblettdata därefter. Det gäller även beräknade värden och rapporter. Vi kan uppnå detta genom att använda triggers, transaktioner och/eller procedurer för alla operationer som måste genomföras tillsammans.
- Dokumentation: Vi måste korrekt dokumentera varje denormaliseringsregel som vi har tillämpat. Om vi ändrar databasdesign senare måste vi titta på alla våra undantag och ta hänsyn till dem igen. Kanske behöver vi dem inte längre eftersom vi har löst problemet. Eller så kanske vi behöver lägga till befintliga denormaliseringsregler. (Till exempel:Vi har lagt till ett nytt attribut i klienttabellen och vi vill lagra dess historikvärde tillsammans med allt vi redan lagrar. Vi måste ändra befintliga denormaliseringsregler för att uppnå det).
- Långsamma andra operationer: Vi kan förvänta oss att vi kommer att sakta ner datainsättning, ändring och radering. Om dessa operationer sker relativt sällan kan detta vara en fördel. I grund och botten skulle vi dela upp ett långsamt urval i ett större antal långsammare infoga/uppdatera/ta bort-frågor. Även om en mycket komplex urvalsfråga tekniskt sett kan märkbart sakta ner hela systemet, bör en sakta ner flera "mindre" operationer inte skada användbarheten av vår applikation.
- Mer kodning: Regler 2 och 3 kommer att kräva ytterligare kodning, men samtidigt kommer de att förenkla vissa utvalda frågor mycket. Om vi avnormaliserar en befintlig databas måste vi ändra dessa utvalda frågor för att dra nytta av vårt arbete. Vi måste också uppdatera värden i nyligen tillagda attribut för befintliga poster. Även detta kommer att kräva lite mer kodning.
Exempelmodellen, denormaliserad
I modellen nedan tillämpade jag några av de tidigare nämnda denormaliseringsreglerna. De rosa borden har modifierats medan det ljusblå bordet är helt nytt.
Vilka ändringar tillämpas och varför?

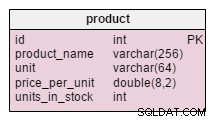
Den enda ändringen i product tabellen är tillägget av units_in_stock attribut. I en normaliserad modell skulle vi kunna beräkna dessa data som beställda enheter – sålda enheter – (erbjudna enheter) – enheter avskrivna . Vi skulle upprepa beräkningen varje gång en kund frågar efter den produkten, vilket skulle vara extremt tidskrävande. Istället kommer vi att beräkna värdet i förväg; när en kund frågar oss har vi den redo. Naturligtvis förenklar detta urvalsfrågan mycket. Å andra sidan, units_in_stock attribut måste justeras efter varje infogning, uppdatering eller radering i products_on_order , writeoff , product_offered och product_sold tabeller.
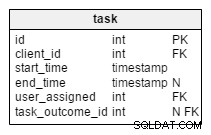
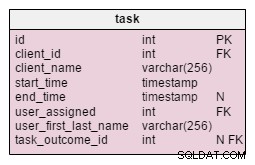
I den ändrade task tabell, hittar vi två nya attribut:client_name och user_first_last_name . Båda lagrar värden när uppgiften skapades. Anledningen är att båda dessa värden kan ändras med tiden. Vi kommer också att behålla en främmande nyckel som relaterar dem till den ursprungliga klienten och användar-ID. Det finns fler värden som vi skulle vilja lagra, som kundadress, momsregistreringsnummer, etc.




Den denormaliserade product_offered tabellen har två nya attribut, price_per_unit och price . price_per_unit attribut lagras eftersom vi måste lagra det faktiska priset när produkten erbjöds . Den normaliserade modellen skulle bara visa sitt nuvarande tillstånd, så när produktpriset ändras skulle våra "historik" priser också ändras. Vår förändring gör inte bara att databasen körs snabbare:den får den också att fungera bättre. price attribut är det beräknade värdet units_sold * price_per_unit . Jag lade till det här för att slippa göra den beräkningen varje gång vi vill ta en titt på en lista över erbjudna produkter. Det är en liten kostnad, men det förbättrar prestandan.
Ändringarna som gjorts på product_sold bord är väldigt lika. Tabellstrukturen är densamma, men den lagrar en lista över sålda föremål.
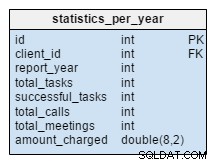
statistics_per_year bord är helt nytt för vår modell. Vi bör se på det som en denormaliserad tabell eftersom all dess data kan beräknas från de andra tabellerna. Tanken bakom denna tabell är att lagra antalet uppgifter, framgångsrika uppgifter, möten och samtal relaterade till en given klient. Den hanterar också summan som debiteras per varje år. Efter att ha infogat, uppdaterat eller tagit bort något i task , meeting , call och product_sold tabeller, bör vi räkna om tabellens data för den kunden och motsvarande år. Vi kan förvänta oss att vi för det mesta bara kommer att ha förändringar för innevarande år. Rapporter för tidigare år bör inte behöva ändras.
Värdena i den här tabellen beräknas i förväg, så vi kommer att spendera mindre tid och resurser när vi behöver beräkningsresultatet. Tänk på de värden du behöver ofta. Du kanske inte behöver dem alla regelbundet och kan riskera att beräkna några av dem live.
Denormalisering är ett mycket intressant och kraftfullt koncept. Även om det inte är det första du bör tänka på för att förbättra prestandan, kan det i vissa situationer vara den bästa eller till och med den enda lösningen.
Innan du väljer att använda denormalisering, se till att du vill ha det. Gör lite analys och spåra prestanda. Du kommer förmodligen att bestämma dig för att gå med denormalisering efter att du redan har gått live. Var inte rädd för att använda den, men spåra ändringar och du bör inte uppleva några problem (dvs. de fruktade dataavvikelserna).