Den här artikeln använder en enkel fråga för att utforska några djupa interna delar angående uppdateringsfrågor.
Exempel på data och konfiguration
Exempel på dataskapande skriptet nedan kräver en tabell med siffror. Om du inte redan har en av dessa kan skriptet nedan användas för att skapa ett effektivt. Den resulterande taltabellen kommer att innehålla en enda heltalskolumn med tal från en till en miljon:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Skriptet nedan skapar en klustrad exempeldatatabell med 10 000 ID:n, med cirka 100 olika startdatum per ID. Kolumnen för slutdatum är initialt inställd på det fasta värdet '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Även om punkterna i den här artikeln gäller ganska generellt för alla nuvarande versioner av SQL Server, kan konfigurationsinformationen nedan användas för att säkerställa att du ser liknande exekveringsplaner och prestandaeffekter:
- SQL Server 2012 Service Pack 3 x64 Developer Edition
- Max serverminne inställt på 2048 MB
- Fyra logiska processorer tillgängliga för instansen
- Inga spårningsflaggor har aktiverats
- Standard läs committed isoleringsnivå
- RCSI- och SI-databasalternativ inaktiverade
Aggregerade hashspill
Om du kör skriptet för att skapa data ovan med faktiska exekveringsplaner aktiverade, kan hashaggregatet spilla till tempdb och generera en varningsikon:

När den körs på SQL Server 2012 Service Pack 3, visas ytterligare information om utsläppet i verktygstipset:
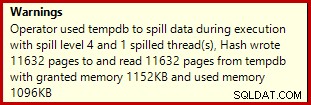
Detta spill kan vara förvånande, med tanke på att indataradsuppskattningarna för Hash Match är exakt korrekta:
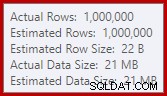
Vi är vana vid att jämföra uppskattningar på indata för sortering och hash-kopplingar (endast bygginput), men ivriga hashaggregat är olika. Ett hashaggregat fungerar genom att samla grupperade resultatrader i hashtabellen, så det är antalet output rader som är viktiga:
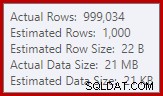
Kardinalitetsuppskattaren i SQL Server 2012 gör en ganska dålig gissning på antalet distinkta värden som förväntas (1 000 mot 999 034 faktiska); hashaggregatet spills rekursivt till nivå 4 vid körning som en konsekvens. Den "nya" kardinalitetsuppskattaren som är tillgänglig i SQL Server 2014 och framåt råkar producera en mer exakt uppskattning för hash-utdata i den här frågan, så du kommer inte att se ett hashspill i så fall:

Antalet faktiska rader kan vara något annorlunda för dig, givet användningen av en pseudo-slumptalsgenerator i skriptet. Det viktiga är att Hash Aggregate-spill beror på antalet unika värden som matas ut, inte på indatastorleken.
Uppdateringsspecifikationen
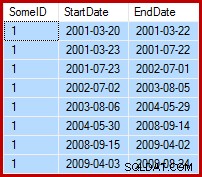
Uppgiften är att uppdatera exempeldata så att slutdatumen ställs in till dagen före följande startdatum (per SomeID). Till exempel kan de första raderna med exempeldata se ut så här före uppdateringen (alla slutdatum inställda på 9999-12-31):

Sedan så här efter uppdateringen:
1. Baslinjeuppdateringsfråga
Ett någorlunda naturligt sätt att uttrycka den nödvändiga uppdateringen i T-SQL är följande:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Utförandeplanen efter genomförandet (faktisk) är:
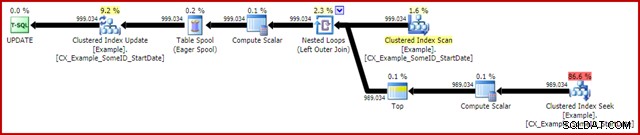
Den mest anmärkningsvärda funktionen är användningen av en Eager Table Spool för att ge Halloween-skydd. Detta krävs för korrekt funktion här på grund av självkopplingen av uppdateringsmåltabellen. Effekten är att allt till höger om spolen körs till slut, och lagrar all information som behövs för att göra ändringar i en tempdb-arbetstabell. När läsningen är klar, spelas innehållet i arbetstabellen upp igen för att tillämpa ändringarna på Clustered Index Update iteratorn.
Prestanda
För att fokusera på den maximala prestandapotentialen för den här exekveringsplanen kan vi köra samma uppdateringsfråga flera gånger. Det är uppenbart att endast den första körningen kommer att resultera i några ändringar av data, men detta visar sig vara ett mindre övervägande. Om detta stör dig, återställ gärna kolumnen för slutdatum före varje körning med följande kod. De allmänna punkter jag kommer att göra beror inte på antalet dataändringar som faktiskt har gjorts.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Med insamling av exekveringsplan inaktiverad, alla nödvändiga sidor i buffertpoolen och ingen återställning av slutdatumsvärdena mellan körningar, körs denna fråga vanligtvis på cirka 5700ms på min bärbara dator. Statistikens IO-utgång är som följer:(läser framåt och LOB-räknare var noll och utelämnas av utrymmesskäl)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Skanningsräkningen representerar antalet gånger en skanningsoperation påbörjades. För exempeltabellen är detta 1 för Clustered Index Scan, och 999 034 för varje gång den korrelerade Clustered Index Seek är tillbaka. Arbetsbordet som används av Eager Spool har en skanningsoperation som startas bara en gång.
Logiska läsningar
Den mer intressanta informationen i IO-utgången är antalet logiska läsningar:över 6 miljoner för exempeltabellen och nästan 3 miljoner för arbetsbordet.
Exempeltabellens logiska läsningar är för det mesta associerade med sökningen och uppdateringen. Sökningen ådrar sig 3 logiska läsningar för varje iteration:1 vardera för indexets rot-, mellan- och bladnivåer. Uppdateringen kostar likaså 3 läsningar varje gång en rad uppdateras när motorn navigerar ner i b-trädet för att lokalisera målraden. Clustered Index Scan är ansvarig för endast några tusen läsningar, en per sida läs.
Spoolarbetsbordet är också strukturerat internt som ett b-träd och räknar flera läsningar när spolen lokaliserar insättningspositionen samtidigt som den förbrukar dess input. Kanske kontraintuitivt räknar spoolen inga logiska läsningar medan den läses för att driva Clustered Index Update. Detta är helt enkelt en konsekvens av implementeringen:en logisk läsning räknas när koden kör BPool::Get metod. Att skriva till spolen anropar denna metod på varje nivå i indexet; läsning från spoolen följer en annan kodsökväg som inte anropar BPool::Get överhuvudtaget.
Lägg också märke till att statistikens IO-utdata rapporterar en enda summa för exempeltabellen, trots att den nås av tre olika iteratorer i exekveringsplanen (Skanna, sök och uppdatera). Detta senare faktum gör det svårt att koppla logiska läsningar till iteratorn som orsakade dem. Jag hoppas att denna begränsning åtgärdas i en framtida version av produkten.
2. Uppdatera med radnummer
Ett annat sätt att uttrycka uppdateringsfrågan är att numrera raderna per ID och gå med:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Planen efter genomförandet är följande:
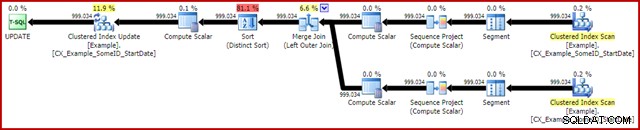
Den här frågan körs vanligtvis i 2950ms på min bärbara dator, vilket jämförs positivt med de 5700ms (under samma omständigheter) som sågs för det ursprungliga uppdateringsförklaringen. Statistikens IO-utgång är:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Detta visar två skanningar startade för exempeltabellen (en för varje Clustered Index Scan iterator). De logiska läsningarna är återigen ett aggregat över alla iteratorer som kommer åt denna tabell i frågeplanen. Liksom tidigare gör avsaknaden av en uppdelning det omöjligt att avgöra vilken iterator (av de två skanningarna och uppdateringen) som var ansvarig för de 3 miljoner läsningarna.
Ändå kan jag berätta att Clustered Index Scans bara räknar några tusen logiska läsningar var. Den stora majoriteten av de logiska läsningarna orsakas av att Clustered Index Update navigerar ner i index b-trädet för att hitta uppdateringspositionen för varje rad som den bearbetar. Du får ta mitt ord för det för stunden; mer förklaring kommer inom kort.
Nackdelarna
Det är i stort sett slutet på de goda nyheterna för den här formen av frågan. Den presterar mycket bättre än originalet, men den är mycket mindre tillfredsställande av ett antal andra skäl. Huvudproblemet orsakas av en optimeringsbegränsning, vilket innebär att den inte känner igen att radnumreringsoperationen producerar ett unikt nummer för varje rad inom en SomeID-partition.
Detta enkla faktum leder till ett antal oönskade konsekvenser. För det första är sammanslagningen konfigurerad att köras i många-till-många-anslutningsläge. Detta är anledningen till den (oanvända) arbetstabellen i statistik-IO (mång-till-många sammanslagning kräver en arbetstabell för dubbletter av kopplingsnyckel tillbakaspolar). Att förvänta sig en många-till-många-join betyder också att kardinalitetsuppskattningen för sammanfogningen är hopplöst fel:
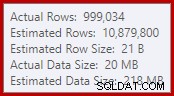
Som en konsekvens av det begär Sorten alldeles för mycket minnesanslag. Rotnodens egenskaper visar att Sortering skulle ha velat ha 812 752 KB minne, även om det bara beviljades 379 440 KB på grund av den begränsade maxserverminnesinställningen (2048 MB). Sorteringen använde faktiskt maximalt 58 968 KB vid körning:
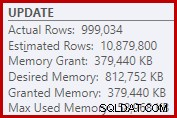
Överdrivet minne ger stjäl minne från andra produktiva användningsområden och kan leda till att frågor väntar tills minnet blir tillgängligt. I många avseenden kan överdrivna minnesanslag vara ett mer problem än att underskatta.
Optimeringsbegränsningen förklarar också varför ett ledtråd för sammanfogning var nödvändigt i frågan för bästa prestanda. Utan denna antydan bedömer optimeraren felaktigt att en hash-join skulle vara billigare än fler-till-många-sammanfogningen. Hash-anslutningsplanen körs i 3350ms i genomsnitt.
Som en sista negativ konsekvens, lägg märke till att sorteringen i planen är en distinkt sortering. Nu finns det ett par anledningar till den sorteringen (inte minst för att den kan ge det erforderliga Halloween-skyddet) men det är bara en Distinkt Sortera eftersom optimeraren missar unikhetsinformationen. Sammantaget är det svårt att tycka mycket om den här genomförandeplanen utöver prestationen.
3. Uppdatera med LEAD Analytic Function
Eftersom den här artikeln främst är inriktad på SQL Server 2012 och senare, kan vi uttrycka uppdateringsfrågan ganska naturligt med hjälp av LEAD-analysfunktionen. I en idealisk värld skulle vi kunna använda en mycket kompakt syntax som:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Tyvärr är detta inte lagligt. Det resulterar i felmeddelande 4108, "Fönsterfunktioner kan endast visas i SELECT- eller ORDER BY-satserna". Detta är lite frustrerande eftersom vi hoppades på en genomförandeplan som skulle kunna undvika en självanslutning (och den tillhörande uppdateringen Halloween Protection).
Den goda nyheten är att vi fortfarande kan undvika självanslutningen genom att använda ett gemensamt tabelluttryck eller härledd tabell. Syntaxen är lite mer utförlig, men idén är ungefär densamma:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Planen efter genomförandet är:

Detta tar vanligtvis 3400ms på min bärbara dator, som är långsammare än radnummerlösningen (2950ms) men fortfarande mycket snabbare än originalet (5700ms). En sak som sticker ut från utförandeplanen är typen av spill (igen, ytterligare spillinformation tack vare förbättringarna i SP3):
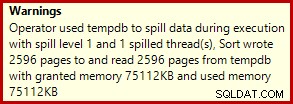
Detta är ett ganska litet spill, men det kan fortfarande påverka prestandan i viss mån. Det konstiga med det är att indatauppskattningen till sorteringen är exakt korrekt:
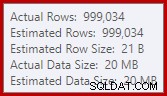
Lyckligtvis finns det en "fix" för detta specifika tillstånd i SQL Server 2012 SP2 CU8 (och andra utgåvor – se KB-artikeln för detaljer). Att köra frågan med fixen och den obligatoriska spårningsflaggan 7470 aktiverad innebär att sorteringen begär tillräckligt med minne för att säkerställa att den aldrig kommer att spillas till disken om den uppskattade inmatningssorteringsstorleken inte överskrids.
LEAD Update Query utan sorteringsspill
För variation använder den fixaktiverade frågan nedan härledd tabellsyntax istället för en CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Den nya planen efter genomförandet är:

Att eliminera det lilla utsläppet förbättrar prestandan från 3400ms till 3250ms . Statistikens IO-utgång är:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Om du jämför detta med de logiska läsningarna för den radnummererade frågan, kommer du att se att de logiska läsningarna har minskat från 3 001 808 till 2 999 455 – en skillnad på 2 353 läsningar. Detta motsvarar exakt borttagningen av en enda Clustered Index Scan (en läsning per sida).
Du kanske minns att jag nämnde att den stora majoriteten av de logiska läsningarna för dessa uppdateringsfrågor är associerade med Clustered Index Update, och att skanningarna var associerade med "bara ett par tusen läsningar". Vi kan nu se detta lite mer direkt genom att köra en enkel radräkningsfråga mot exempeltabellen:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
IO-utgången visar exakt de 2 353 logiska lässkillnaderna mellan radnumret och uppdateringarna av lead:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Ytterligare förbättringar?
Den spillfixerade lead-frågan (3250ms) är fortfarande ganska långsammare än den numrerade frågan med dubbla rader (2950ms), vilket kan vara lite överraskande. Intuitivt kan man förvänta sig att en enda skanning och analysfunktion (Window Spool och Stream Aggregate) är snabbare än två skanningar, två uppsättningar radnumrering och en sammanfogning.
Oavsett vilket är det som hoppar ut från exekveringsplanen för lead-frågor sorteringen. Den fanns också i den radnumrerade frågan, där den bidrog med Halloween-skydd samt en optimerad sorteringsordning för Clustered Index Update (som har DMLRequestSort-egenskapsuppsättningen).
Saken är den att denna sortering är helt onödig i lead-frågeplanen. Det behövs inte för Halloweenskydd eftersom självanslutningen har gått. Det behövs inte heller för optimerad infogningssorteringsordning:raderna läses i Clustered Key-ordning, och det finns inget i planen som stör den ordningen. Det verkliga problemet kan ses genom att titta på Sorteringsegenskaperna:

Lägg märke till avsnittet Order By där. Sorteringen sorteras efter SomeID och StartDate (de klustrade indexnycklarna) men också efter [Uniq1002], som är uniquiifier. Detta är en konsekvens av att inte deklarera det klustrade indexet som unikt, även om vi vidtog steg i datapopulationsfrågan för att säkerställa att kombinationen av SomeID och StartDate faktiskt skulle vara unik. (Detta var avsiktligt, så jag kunde prata om det här.)
Trots det är detta en begränsning. Rader läses från det klustrade indexet i ordning, och de nödvändiga interna garantierna finns så att optimeraren säkert kan undvika denna sortering. Det är helt enkelt en förbiseende att optimeraren inte känner igen att den inkommande strömmen sorteras efter uniquifier samt efter SomeID och StartDate. Den känner igen att (SomeID, StartDate) ordning kan bevaras, men inte (SomeID, StartDate, uniquifier). Återigen, jag hoppas att detta kommer att tas upp i en framtida version.
För att kringgå detta kan vi göra vad vi borde ha gjort i första hand:bygga det klustrade indexet som unikt:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
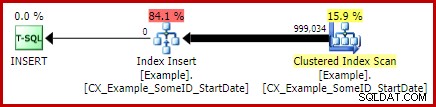
Jag lämnar det som en övning för läsaren att visa att de två första (icke-LEAD) frågorna inte drar nytta av denna indexeringsändring (utelämnas enbart av utrymmesskäl – det finns mycket att täcka).
Den slutliga formen för frågan om uppdatering av potentiella kunder
Med den unika klustrade index på plats, exakt samma LEAD-fråga (CTE eller härledd tabell som du vill) producerar den beräknade (förutförande) plan som vi förväntar oss:

Detta verkar ganska optimalt. En enda läs- och skrivoperation med ett minimum av operatorer emellan. Visst verkar det mycket bättre än den tidigare versionen med den onödiga sorteringen, som kördes på 3250 ms när det undvikbara utsläppet togs bort (på bekostnad av att öka minnesanslaget lite).
Planen efter utförande (faktisk) är nästan exakt densamma som planen före utförande:

Alla uppskattningar är exakt korrekta, förutom utdata från Window Spool, som är avstängd med 2 rader. Statistikens IO-information är exakt densamma som innan sorteringen togs bort, som du kan förvänta dig:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
För att kort sammanfatta, är den enda uppenbara skillnaden mellan denna nya plan och den omedelbart föregående att sorteringen (med ett beräknat kostnadsbidrag på nästan 80 %) har tagits bort.
Det kan komma som en överraskning då att få veta att den nya frågan – utan sortering – körs på 5000ms . Detta är mycket värre än 3250ms med Sortering, och nästan lika länge som den ursprungliga loop-anslutningsfrågan på 5700ms. Lösningen för numrering med dubbla rader ligger fortfarande långt fram på 2950 ms.
Förklaring
Förklaringen är något esoterisk och relaterar till hur spärrarna hanteras för den senaste frågan. Vi kan visa denna effekt på flera sätt, men det enklaste är förmodligen att titta på vänte- och låsstatistiken med hjälp av DMV:er:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; När det klustrade indexet inte är unikt och det finns en sortering i planen, finns det inga betydande väntan, bara ett par PAGEIOLATCH_UP-väntningar och de förväntade SOS_SCHEDULER_YIELDs.
När det klustrade indexet är unikt och sorteringen tas bort är väntan:
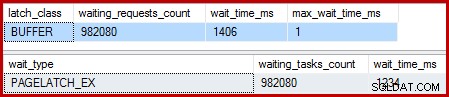
Det finns 982 080 exklusiva sidspärrar där, med en väntetid som förklarar i stort sett hela den extra exekveringstiden. För att betona, det är nästan en spärrvänta per uppdaterad rad! Vi kan förvänta oss en ändring av spärren per rad, men inte en spärr vänta , särskilt när testfrågan är den enda aktiviteten på instansen. Väntorna på spärren är korta, men det finns väldigt många av dem.
Lata spärrar
Efter exekveringen av frågan med en debugger och analysator kopplad, är förklaringen följande.
Clustered Index Scan använder lata spärrar – en optimering som innebär att spärrarna bara släpps när en annan tråd kräver åtkomst till sidan. Normalt släpps spärrarna omedelbart efter läsning eller skrivning. Lata spärrar optimerar fallet där en hel sida annars skulle få och släppa samma sidspärr för varje rad. När lazy latching används utan tvekan, tas endast en latch för hela sidan.
Problemet är att exekveringsplanens rörliga karaktär (inga blockerande operatörer) innebär att läsningar överlappar med skrivningar. När Clustered Index Update försöker skaffa en EX-spärr för att ändra en rad, kommer den nästan alltid att upptäcka att sidan redan är låst SH (den lata spärren som tas av Clustered Index Scan). Denna situation resulterar i en låst väntan.
Som en del av förberedelserna för att vänta och byta till nästa körbara objekt på schemaläggaren, är koden noga med att släppa alla lata spärrar. Att släppa den lata spärren signalerar den första kvalificerade servitören, som råkar vara sig själv. Så vi har den konstiga situationen där en tråd blockerar sig själv, släpper sin lata spärr och sedan signalerar sig själv att den är körbar igen. Tråden tar fart igen och fortsätter, men först efter att allt det bortkastade suspendera och växla, signalera och återuppta arbete har gjorts. Som jag sa tidigare, väntan är kort, men det finns många av dem.
För allt jag vet är detta udda händelseförlopp genom design och av goda interna skäl. Trots det går det inte att komma ifrån att det har en ganska dramatisk inverkan på prestanda här. Jag kommer att göra några förfrågningar om detta och uppdatera artikeln om det finns ett offentligt uttalande att göra. Under tiden kan överdrivna självlåsande väntan vara något att se upp med med pipelined uppdateringsfrågor, även om det inte är klart vad som ska göras åt det från frågeskrivarens synvinkel.
Betyder detta att den dubbla radnumreringsmetoden är det bästa vi kan göra för den här frågan? Inte riktigt.
4. Manuellt Halloweenskydd
Det här sista alternativet kan låta och se lite galet ut. Den allmänna idén är att skriva all information som behövs för att göra ändringarna i en tabellvariabel och sedan utföra uppdateringen som ett separat steg.
I brist på en bättre beskrivning kallar jag detta "manuella HP"-metoden eftersom det konceptuellt liknar att skriva all ändringsinformation till en Eager Table Spool (som ses i den första frågan) innan uppdateringen körs från den spoolen.
Hur som helst, koden är som följer:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Den koden använder medvetet en tabellvariabel för att undvika kostnaden för automatiskt skapad statistik som skulle medföra att använda en tillfällig tabell. Detta är OK här eftersom jag vet vilken planform jag vill ha, och det beror inte på kostnadsuppskattningar eller statistisk information.
Den enda nackdelen med tabellvariabeln (utan en spårningsflagga) är att optimeraren vanligtvis uppskattar en enda rad och väljer kapslade loopar för uppdateringen. För att förhindra detta har jag använt en sammanfogningstips. Återigen, detta drivs av att veta exakt vilken planform som ska uppnås.
Efterkörningsplanen för tabellvariabelinsättningen ser exakt likadan ut som frågan som hade problemet med latch waits:

Fördelen med denna plan är att den inte ändrar samma tabell som den läser från. Inget Halloween-skydd krävs, och det finns ingen risk för spärrstörningar. Dessutom finns det betydande interna optimeringar för tempdb-objekt (låsning och loggning) och andra normala bulkladdningsoptimeringar tillämpas också. Kom ihåg att massoptimeringar endast är tillgängliga för infogning, inte uppdateringar eller borttagningar.
Planen efter genomförandet av uppdateringssatsen är:
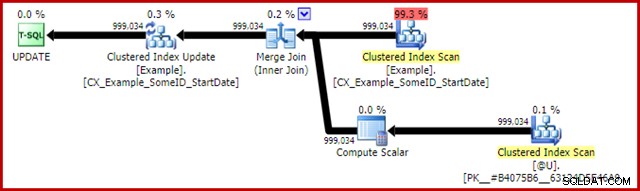
Sammanfogningen här är den effektiva en-till-många-typen. Mer till punkten, denna plan kvalificerar sig för en speciell optimering som innebär att Clustered Index Scan och Clustered Index Update delar samma raduppsättning. Den viktiga konsekvensen är att uppdateringen inte längre behöver hitta raden som ska uppdateras – den är redan korrekt placerad vid läsningen. Detta sparar en hel del logiska läsningar (och annan aktivitet) vid uppdateringen.
Det finns inget i normala exekveringsplaner som visar var denna optimering av delad raduppsättning tillämpas, men att aktivera odokumenterad spårningsflagga 8666 avslöjar extra egenskaper på uppdateringen och skanningen som visar att raduppsättningsdelning används, och att åtgärder vidtas för att säkerställa att uppdateringen är säker från Halloween-problemet.
Statistikens IO-utgång för de två frågorna är som följer:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Båda läsningarna av exempeltabellen involverar en enda skanning och en logisk läsning per sida (se den enkla radräkningsfrågan tidigare). #B9C034B8-tabellen är namnet på det interna tempdb-objektet som backar tabellvariabeln. Den totala logiska läsningen för båda frågorna är 3 * 2353 =7 059. Arbetsbordet är det interna minnet i minnet som används av Window Spool.
Den typiska körtiden för den här frågan är 2300ms . Slutligen har vi något som slår den dubbla radnumreringsfrågan (2950ms), hur osannolikt det än kan verka.
Sluta tankar
Det kan finnas ännu bättre sätt att skriva den här uppdateringen som presterar ännu bättre än den "manuella HP"-lösningen ovan. Prestandaresultaten kan till och med vara olika på din hårdvara och SQL Server-konfiguration, men ingen av dessa är huvudpoängen i den här artikeln. Därmed inte sagt att jag inte är intresserad av att se bättre frågor eller resultatjämförelser – det är jag.
Poängen är att det händer mycket mer inuti SQL Server än vad som avslöjas i exekveringsplaner. Förhoppningsvis kommer några av detaljerna som diskuteras i denna ganska långa artikel att vara intressanta eller till och med användbara för vissa människor.
Det är bra att ha förväntningar på prestanda och veta vilka planformer och egenskaper som generellt är fördelaktiga. Den typen av erfarenhet och kunskap kommer att tjäna dig väl för 99 % eller mer av de frågor du någonsin kommer att bli ombedd att ställa in. Ibland är det dock bra att prova något lite konstigt eller ovanligt bara för att se vad som händer och för att bekräfta dessa förväntningar.