En lönedatamodell låter dig enkelt beräkna dina anställdas lön. Hur fungerar den här modellen?
Oavsett om du driver ett litet eller stort företag behöver du någon form av lönelösning. Det är där en löneansökan kommer väl till pass. Dessutom, ju större företaget är, desto svårare blir det att hantera de anställdas löneberäkningar; här blir en löneansökan en nödvändighet. För att hjälpa dig att förstå all data som krävs för en sådan applikation går vi igenom en relaterad datamodell.
Låt oss se hur vår lönedatamodell fungerar!
Datamodell
Med att skapa denna datamodell försökte jag skapa en modell som är allmänt användbar för alla företag. Naturligtvis kommer det alltid att finnas skillnader i regelverk, företagspolicyer etc. som kommer att kräva att modellen anpassas för att täcka behoven för en specifik lönelista. Principerna som anges i denna modell bör dock vara relevanta för de flesta organisationer.
Det måste noteras att denna modell skapades med flera antaganden:
- Löner enligt anställningsavtal är per år.
- Nettolöner (d.v.s. med vissa avdrag för skatter etc.) betalas ut till anställda.
- Löner betalas ut månadsvis.
Datamodellen består av fjorton tabeller och är indelad i två ämnesområden:
AnställdaLöner
För att bättre förstå modellen är det nödvändigt att gå igenom varje ämnesområde noggrant.
Anställda
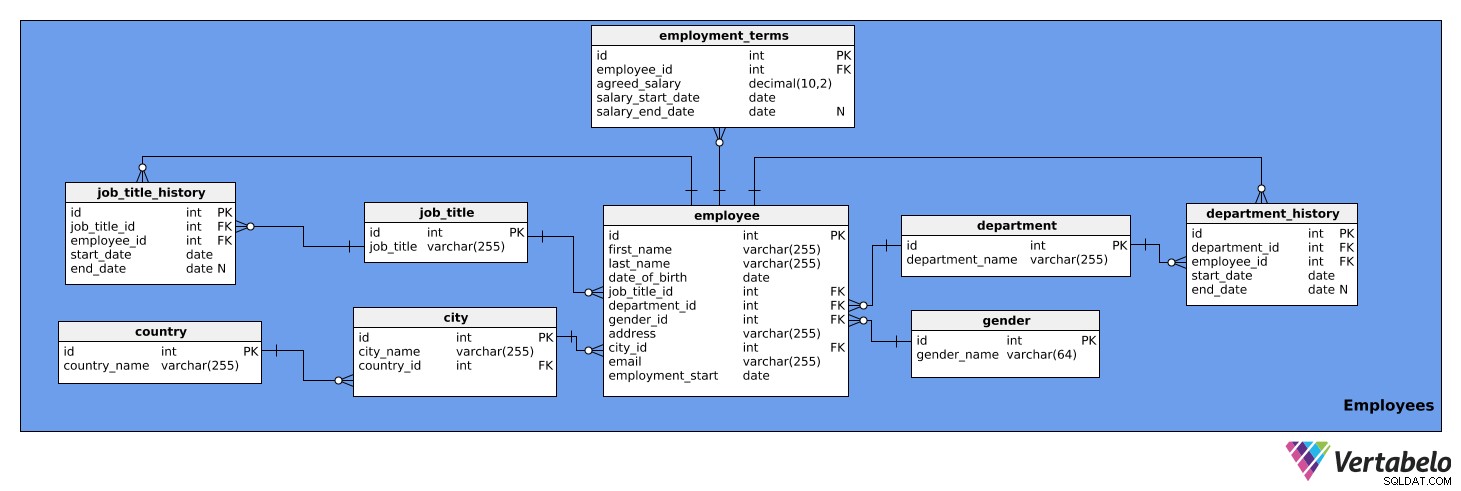
Detta ämnesområde innehåller detaljerad information om anställda. Den består av nio tabeller:
anställdanställningsvillkorjobbtiteljob_title_historyavdelningdepartment_historystadlandkön
Den första tabellen vi ska titta på är anställd tabell. Den innehåller en lista över alla anställda och deras relevanta uppgifter. Tabellens attribut är:
id– Ett unikt ID för varje anställd.förnamn– Den anställdes förnamn.efternamn– Den anställdes efternamn.job_title_id– Refererar tilljobbtiteltabell.avdelnings-id– Refererar tillavdelningentabell.gender_id– Refererar tillkönettabell.adress– Den anställdes adress.stads-id– Refererar tillstadtabell.e-post– Medarbetarens e-post.anställningsstart– Datumet då denna persons anställning började.
Lägg märke till att kolumnerna job_title_id och department_id är överflödiga, eftersom informationen om aktuella befattningar och avdelningar kan nås från job_title_history och department_history tabeller. Vi kommer dock att behålla dessa två kolumner i den här tabellen för snabbare åtkomst till informationen.
Följande är anställningsvillkoren tabell. Den lagrar uppgifter om varje anställds lön, som avtalats i anställningsavtalet, och hur den har förändrats över tiden. Tabellens attribut är:
id– Ett unikt ID för varje uppsättning anställningsvillkor.employee_id– Refererar tillanställdtabell.överenskommen_lön– Den lön som står i anställningsavtalet.lön_startdatum– Startdatum för den avtalade lönen.lön_slutdatum– Slutdatum för den avtalade lönen. Detta kan vara NULL eftersom en lön kanske inte har någon planerad förändring.
jobbtitel tabell är en lista över de befattningar som kan tilldelas olika företagsanställda, t.ex. analytiker, förare, sekreterare, direktör, etc. Tabellen har följande attribut:
id– Ett unikt ID för varje jobbtitel.jobbtitel– Namnet på befattningen. Detta är den alternativa nyckeln.
Vi behöver också en tabell för att lagra varje anställds jobbtitelhistorik. Vi behöver detta eftersom anställda kan befordras, degraderas eller omplaceras inom företaget. job_title_history tabellen kommer att hantera denna information och kommer att bestå av följande attribut:
id– Ett unikt ID för den historiska posten för jobbtiteln.job_title_id– Refererar tilljobbtiteltabell.employee_id– Refererar tillanställdtabell.startdatum– Det datum då den anställde först hade den tjänstetiteln.slutdatum– När den anställde slutade ha den tjänstetiteln. Detta kan vara NULL eftersom den anställde för närvarande kan ha den tjänstetiteln.
Kombinationen av job_title_id , employee_id och startdatum är den alternativa nyckeln för tabellen ovan. En anställd kan endast ha en jobbtitel tilldelad vid ett givet datum.
Nästa tabell är avdelningen tabell. Detta kommer helt enkelt att lista alla företagets avdelningar, såsom IT, Accounting, Legal, etc. Den innehåller två attribut:
id– Ett unikt ID för varje avdelning.avdelningsnamn– Namnet på varje avdelning. Detta är den alternativa nyckeln.
Anställda kan också byta avdelning inom företaget. Därför måste vi ha en department_history tabell. Den här tabellen lagrar följande:
id– Ett unikt ID för den avdelningens historiska post.avdelnings-id– Refererar tillavdelningentabell.employee_id– Refererar tillanställdtabell.startdatum– Det datum då en anställd började arbeta på en avdelning.slutdatum– Datumet då en anställd slutade arbeta på den avdelningen. Detta kan vara NULL eftersom den anställde fortfarande kan arbeta där.
Kombinationen av department_id , employee_id och startdatum är den alternativa nyckeln. En anställd kan endast arbeta på en avdelning åt gången.
Nästa tabell vi kommer att prata om är staden tabell. Detta är en lista över alla relevanta städer. Den har följande attribut:
id– Ett unikt ID för varje stad.stadsnamn– Namnet på staden.country_id– Refererar tilllandtabell.
landet tabellen är nästa i vår modell. Det är helt enkelt en lista över länder och den innehåller följande information:
id– Ett unikt ID för varje land.landsnamn– Namnet på landet. Detta är den alternativa nyckeln.
Den sista tabellen i detta ämnesområde är kön tabell. Denna tabell listar alla kön. Den innehåller följande attribut:
id– Ett unikt ID för varje kön.gender_name– Namnet på kön.
Låt oss nu analysera det andra ämnesområdet.
Löner
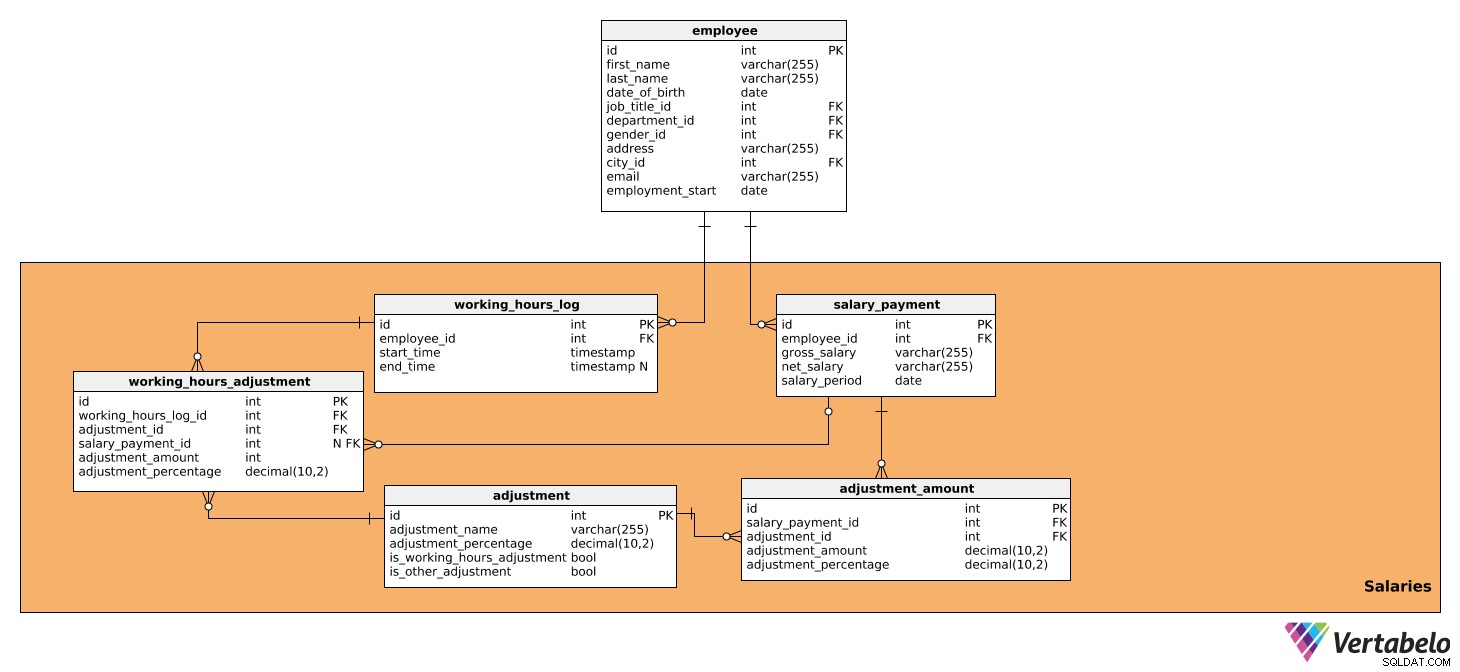
Detta ämnesområde består av tabeller som innehåller all data som direkt påverkar löneberäkningarna för varje period samt det belopp som ska betalas ut. Den består av fem tabeller:
lön_betalningworking_hours_logarbetstidsjusteringjusteringadjustment_amount
Låt oss nu titta på varje tabell.
Den första tabellen är lön_betalning . Den innehåller all relevant information om lönen som betalas ut till varje anställd och har följande attribut:
id– Ett unikt ID för varje lön.employee_id– Refererar tillanställdtabell.bruttolön– Bruttolönen, som kommer att ligga till grund för ytterligare anpassningar.nettolön– Nettolönen (dvs det belopp som den anställde får efter att olika avdrag har gjorts).löneperiod– Den period för vilken lönen beräknas och betalas ut.
Den andra är working_hours_log tabell. Den innehåller uppgifter om antalet arbetade timmar av varje anställd, vilket kan påverka vissa lönejusteringar. Den här tabellen har följande attribut:
id– Ett unikt ID för varje loggpost.employee_id– Refererar tillanställdtabell.starttid– Den tidpunkt då medarbetaren loggade in, det vill säga började arbeta för dagen.sluttid– När medarbetaren loggat ut. Det kan vara NULL eftersom vi inte vet den exakta tiden förrän medarbetaren loggar ut.
Nästa tabell vi kommer att analysera är arbetstidsjustering . Denna tabell kommer endast att användas vid beräkning av justeringar baserat på arbetade timmar, dvs. de som har ett TRUE-värde i is_working_hours_adjustment i justering tabell. Attributen är följande:
id– Ett unikt ID för varje justering.working_hours_log_id– Refererar tillworking_hours_logtabell.adjustment_id- Refererar tilljusteringentabell.lön_betalnings-id– Refererar tilllönebetalning tabell. Detta värde kan vara NULL eftersom lön_betalnings-idkommer endast användas en gång i månaden, när vi påbörjar en löneberäkning.adjustment_amount– Justeringens storlek.justeringsprocent– Det procentuella beloppet av justeringen. Detta kommer att användas i historiska syften, eftersom andelen kan ändras över tiden.
Nästa tabell vi kommer att prata om är justeringen tabell. Den innehåller information om alla justeringar som används för löneberäkning, det vill säga alla skatter och avgifter som påverkar lönebeloppet. Den kommer också att innehålla alla justeringar som beror på antalet arbetade och inte arbetade timmar, såsom bonusar, övertid, sjukskrivning och mamma-/faderskapsledighet. För det behöver vi följande data:
id– Ett unikt ID för varje justering.justeringsnamn– Ett namn som beskriver den justeringen.justeringsprocent– Det procentuella beloppet för den specifika justeringen.is_working_hours_adjustment– Det här är en flaggmarkering om en justering direkt beror på arbetstiden, t.ex. övertid, sjukskrivning etc.is_other_adjustment– Detta är en flaggmarkeringsjustering som inte gör är direkt beroende av arbetade timmar, såsom skatteavdrag, sociala avgifter, arbetsgivaravgifter etc.
Efter det behöver vi adjustment_amount tabell. Den kommer att användas för att beräkna alla lönejusteringar förutom de som redan finns i arbetstidsjustering , dvs. de som har ett TRUE-värde i is_other_adjustment i justering tabell. Tabellen innehåller följande attribut:
id– Ett unikt ID för varje justeringsbeloppspost.lön_betalnings-id– Refererar tilllönebetalning tabell. adjustment_id– Refererar tilljusteringentabell.adjustment_amount– Beloppet för varje beräknad justering.justeringsprocent- Det procentuella beloppet för justeringen. Den kommer att användas i historiska syften, eftersom andelen kan ändras över tiden.
Låt mig ge dig ett exempel på hur tabellerna working_hours_log , arbetstidsjustering , justering och adjustment_amount arbeta tillsammans för att beräkna en lön. Varje dag loggar medarbetaren när han eller hon kommer till jobbet och när han eller hon går. Dessa data kan ses i working_hours_log tabell. Låt oss säga att vår anställd har arbetat 10 timmar övertid under en månad och enligt företagets policy kommer han eller hon att få 20 % mer betalt per timme för varje övertidstimme. Genom att referera till justeringen tabell, kommer vi att kunna hitta den nödvändiga justeringen, dvs övertid, som kommer att ha ett visst procentuellt belopp (20%). Vi kommer också att ha is_working_hours_adjustment inställd på TRUE. Genom att använda data från dessa två tabeller kommer vi att kunna beräkna justeringen och lagra den i arbetstidsjustering tabell.
Nu kan vi beräkna alla andra justeringar som inte gör beror på antalet arbetade timmar. Detta kommer att göras i adjustment_amount tabell. Precis som vi gjorde ovan kommer vi att referera till justeringen tabell och hitta de justeringar som vi behöver – t.ex. skatteavdrag, socialförsäkringsavgift eller arbetsgivaravgift – och deras relevanta procentsatser. is_other_adjustment flagga i justering Tabellen ställs in på TRUE för dessa justeringar.
Baserat på dessa beräkningar kan vi lagra bruttolön och nettolöndata i lönebetalning tabell.
Genom att gå igenom det här exemplet har vi täckt allt i vår datamodell!
Tyckte du om lönedatamodellen?
Jag försökte skapa en modell som kunde användas i nästan alla situationer. Det är dock omöjligt att inkludera alla specifika parametrar som påverkar löneberäkningen i en artikel av denna längd. Genom att täcka allmänna principer har jag försökt göra denna modell användbar som en solid grund för din lönedatamodell.
Vad tycker du om lönedatamodellen? Är det tillämpbart som en lösning för dina lönebehov? Har du kommit på något annat? Finns det specifika problem du har hittat som väsentligt skulle förändra datamodellen? Säg din mening i kommentarsfältet.