
Det är den där tisdagen i månaden – du vet, den då bloggarblockfesten känd som T-SQL Tuesday inträffar. Denna månad är den värd av Russ Thomas (@SQLJudo), och ämnet är "Calling All Tuners and Gear Heads." Jag kommer att behandla ett prestationsrelaterat problem här, även om jag ber om ursäkt för att det kanske inte är helt i linje med riktlinjerna som Russ angav i hans inbjudan (jag kommer inte att använda tips, spårningsflaggor eller planguider) .
På SQLBits förra veckan höll jag en presentation om triggers, och min gode vän och kollega MVP Erland Sommarskog råkade vara med. Vid ett tillfälle föreslog jag att innan du skapar en ny trigger på en tabell, bör du kontrollera om det redan finns några triggers och överväga att kombinera logiken istället för att lägga till en extra trigger. Mina skäl var främst för kodunderhållbarhet, men också för prestanda. Erland frågade om jag någonsin hade testat för att se om det fanns någon extra overhead i att flera triggers utlöstes för samma åtgärd, och jag måste erkänna att nej, jag hade inte gjort något omfattande. Så det ska jag göra nu.
I AdventureWorks2014 skapade jag en enkel uppsättning tabeller som i princip representerar sys.all_objects (~2 700 rader) och sys.all_columns (~9 500 rader). Jag ville mäta effekten på arbetsbelastningen av olika metoder för att uppdatera båda tabellerna – i huvudsak har du användare som uppdaterar kolumntabellen, och du använder en utlösare för att uppdatera en annan kolumn i samma tabell och några kolumner i objekttabellen.
- T1:Baslinje :Antag att du kan kontrollera all dataåtkomst genom en lagrad procedur; i detta fall kan uppdateringarna mot båda tabellerna utföras direkt, utan behov av triggers. (Detta är inte praktiskt i den verkliga världen, eftersom du inte på ett tillförlitligt sätt kan förbjuda direkt åtkomst till borden.)
- T2:Enkel utlösare mot annan tabell :Anta att du kan styra uppdateringssatsen mot den berörda tabellen och lägga till andra kolumner, men uppdateringarna till den sekundära tabellen måste implementeras med en utlösare. Vi uppdaterar alla tre kolumnerna med ett påstående.
- T3:Enkel utlösare mot båda tabellerna :I det här fallet har vi en utlösare med två satser, en som uppdaterar den andra kolumnen i den berörda tabellen och en som uppdaterar alla tre kolumnerna i den sekundära tabellen.
- T4:Enkel utlösare mot båda tabellerna :Som T3, men den här gången har vi en trigger med fyra satser, en som uppdaterar den andra kolumnen i den berörda tabellen och en sats för varje kolumn uppdaterad i den sekundära tabellen. Det här kan vara så det hanteras om kraven läggs till med tiden och ett separat uttalande anses säkrare när det gäller regressionstestning.
- T5:Två utlösare :En utlösare uppdaterar bara den berörda tabellen; den andra använder en enda sats för att uppdatera de tre kolumnerna i den sekundära tabellen. Det kan vara så det görs om de andra triggerna inte uppmärksammas eller om det är förbjudet att ändra dem.
- T6:Fyra utlösare :En utlösare uppdaterar bara den berörda tabellen; de andra tre uppdaterar varje kolumn i den sekundära tabellen. Återigen, det kan vara så det görs om du inte vet att de andra triggarna finns, eller om du är rädd för att röra de andra triggarna på grund av regressionsproblem.
Här är källdata vi har att göra med:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Nu, för vart och ett av de 6 testerna, kommer vi att köra våra uppdateringar 1 000 gånger och mäta hur lång tid det tar
T1:Baslinje
Detta är scenariot där vi har turen att undvika triggers (igen, inte särskilt realistiskt). I det här fallet kommer vi att mäta avläsningarna och varaktigheten för denna batch. Jag sätter /*real*/ in i frågetexten så att jag enkelt kan dra statistiken för just dessa påståenden, och inte några påståenden inifrån triggarna, eftersom mätvärdena i slutändan rullar upp till de påståenden som anropar utlösarna. Observera också att de faktiska uppdateringarna jag gör egentligen inte är meningsfulla, så ignorera att jag ställer in sorteringen till servern/instansens namn och objektets principal_id till den aktuella sessionens session_id .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Enkel utlösare
För detta behöver vi följande enkla trigger, som bara uppdaterar dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Då behöver vår batch bara uppdatera de två kolumnerna i den primära tabellen:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Enkel trigger mot båda tabellerna
För det här testet ser vår trigger ut så här:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Och nu måste den batch vi testar bara uppdatera den ursprungliga kolumnen i den primära tabellen; den andra hanteras av triggern:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Enkel trigger mot båda tabellerna
Detta är precis som T3, men nu har utlösaren fyra påståenden:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testsatsen är oförändrad:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Två utlösare
Här har vi en trigger för att uppdatera den primära tabellen, och en trigger för att uppdatera den sekundära tabellen:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testsatsen är återigen väldigt enkel:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Fyra triggers
Den här gången har vi en trigger för varje kolumn som påverkas; en i den primära tabellen och tre i de sekundära tabellerna.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Och testbatchen:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Mäta påverkan på arbetsbelastningen
Slutligen skrev jag en enkel fråga mot sys.dm_exec_query_stats för att mäta avläsningar och varaktighet för varje test:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Resultat
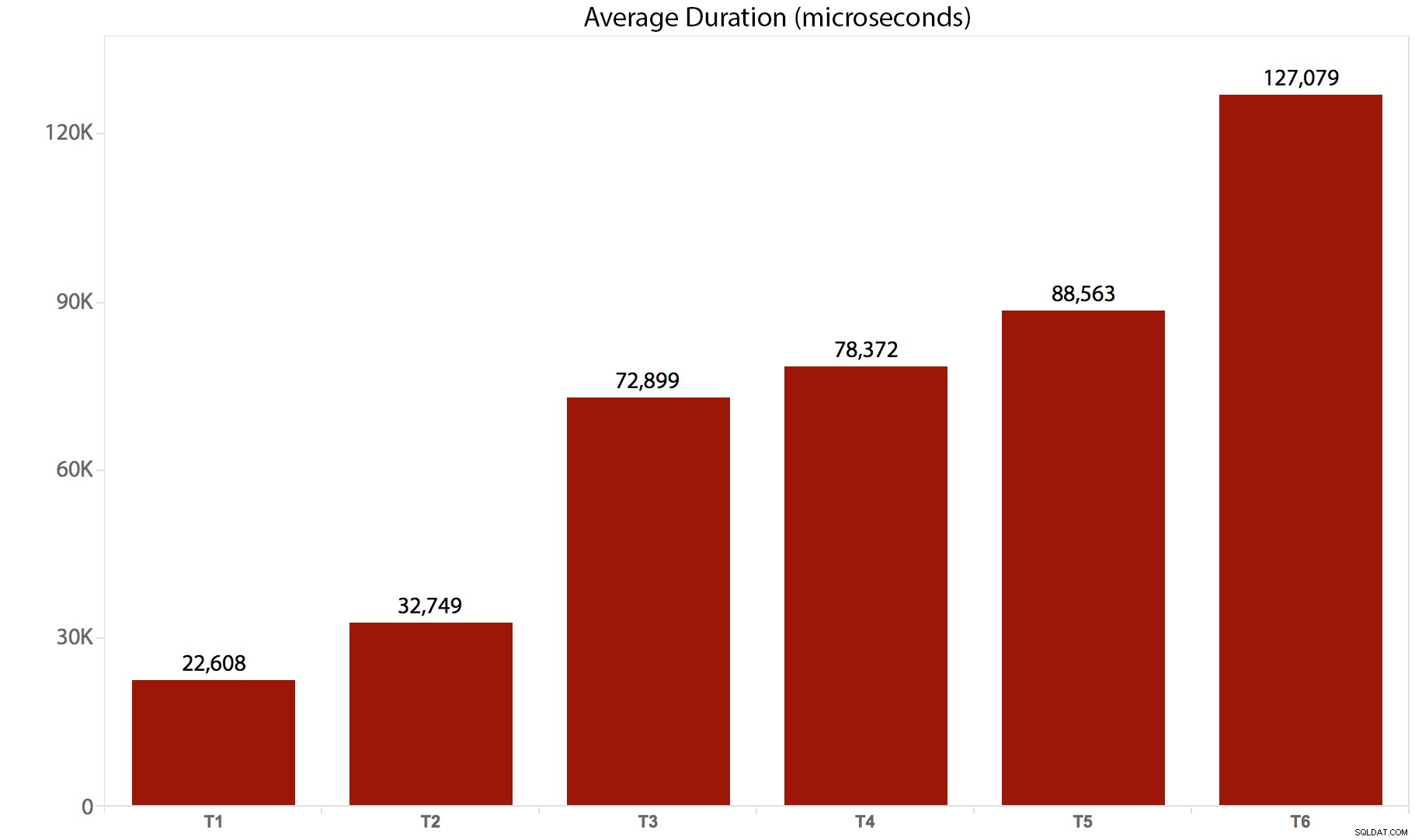
Jag körde testerna 10 gånger, samlade in resultaten och tog ett genomsnitt av allt. Så här gick det sönder:
| Test/batch | Genomsnittlig varaktighet (mikrosekunder) | Totalt antal läsningar (8 000 sidor) |
|---|---|---|
| T1 :UPPDATERING /*real*/ dbo.tr1 … | 22 608 | 205 134 |
| T2 :UPPDATERING /*real*/ dbo.tr2 … | 32 749 | 11 331 628 |
| T3 :UPPDATERING /*real*/ dbo.tr3 … | 72 899 | 22 838 308 |
| T4 :UPPDATERING /*real*/ dbo.tr4 … | 78 372 | 44 463 275 |
| T5 :UPPDATERING /*real*/ dbo.tr5 … | 88 563 | 41 514 778 |
| T6 :UPPDATERING /*real*/ dbo.tr6 … | 127 079 | 100 330 753 |
Och här är en grafisk representation av varaktigheten:
Slutsats
Det är tydligt att det i det här fallet finns en del betydande omkostnader för varje utlösare som anropas – alla dessa batcher påverkade i slutändan samma antal rader, men i vissa fall berördes samma rader flera gånger. Jag kommer förmodligen att utföra ytterligare uppföljningstestning för att mäta skillnaden när samma rad aldrig berörs mer än en gång – ett mer komplicerat schema, kanske, där 5 eller 10 andra tabeller måste beröras varje gång, och dessa olika uttalanden kan vara i en enda trigger eller i flera. Min gissning är att överheadskillnaderna kommer att drivas mer av saker som samtidighet och antalet rader som påverkas än av själva utlösarens overhead – men vi får se.
Vill du prova demot själv? Ladda ner skriptet här.