Även om de kommer med många begränsningar och några viktiga implementeringsförbehåll, är indexerade vyer fortfarande en mycket kraftfull SQL Server-funktion när de används korrekt under rätt omständigheter. En vanlig användning är att tillhandahålla en föraggregerad vy av underliggande data, vilket ger användarna möjlighet att fråga efter resultat direkt utan att ta på sig kostnaderna för att bearbeta de underliggande kopplingarna, filtren och aggregaten varje gång en fråga exekveras.
Även om nya Enterprise Edition-funktioner som kolumnär lagring och batchlägesbearbetning har förändrat prestandaegenskaperna för många stora frågor av den här typen, finns det fortfarande inget snabbare sätt att få ett resultat än att helt undvika all underliggande bearbetning, oavsett hur effektiv den behandlingen är. kan ha blivit.
Innan indexerade vyer (och deras mer begränsade kusiner, beräknade kolumner) lades till produkten, skrev databasproffs ibland komplex multitriggerkod för att presentera resultaten av en viktig fråga i en riktig tabell. Den här typen av arrangemang är notoriskt svårt att få till rätta under alla omständigheter, särskilt där samtidiga ändringar av underliggande data är frekventa.
Funktionen för indexerade vyer gör allt detta mycket enklare, där det tillämpas förnuftigt och korrekt. Databasmotorn tar hand om allt som behövs för att säkerställa att data som läses från en indexerad vy matchar den underliggande frågan och tabelldata hela tiden.
Inkrementellt underhåll
SQL Server håller indexerad vydata synkroniserad med den underliggande frågan genom att automatiskt uppdatera vyindexen på lämpligt sätt när data ändras i bastabellerna. Kostnaden för denna underhållsaktivitet bärs av processen som ändrar basdata. De extra operationerna som behövs för att underhålla vyindexen läggs tyst till exekveringsplanen för den ursprungliga infognings-, uppdaterings-, raderings- eller sammanfogningsoperationen. I bakgrunden tar SQL Server också hand om mer subtila frågor som rör transaktionsisolering, till exempel att säkerställa korrekt hantering av transaktioner som körs under ögonblicksbild eller läs committed ögonblicksbildisolering.
Att konstruera de extra exekveringsplanoperationerna som behövs för att upprätthålla vyindexen korrekt är inte en trivial sak, vilket alla som har försökt implementera en "sammanfattningstabell som underhålls av triggerkod" vet. Uppgiftens komplexitet är en av anledningarna till att indexerade vyer har så många begränsningar. Att begränsa den stödda ytan till inre sammanfogningar, projektioner, val (filter) och SUM- och COUNT_BIG-aggregaten minskar implementeringskomplexiteten avsevärt.
Indexerade vyer underhålls inkrementellt . Detta innebär att frågeprocessorn bestämmer nettoeffekten av bastabelländringarna på vyn och tillämpar endast de ändringar som är nödvändiga för att uppdatera vyn. I enkla fall kan den beräkna de nödvändiga deltan från bara ändringarna i bastabellen och de data som för närvarande lagras i vyn. Där vydefinitionen innehåller kopplingar, kommer den indexerade vyunderhållsdelen av exekveringsplanen att behöva komma åt de anslutna tabellerna också, men detta kan vanligtvis utföras effektivt, givet lämpliga bastabellindex.
För att förenkla implementeringen ytterligare använder SQL Server alltid samma grundläggande planform (som utgångspunkt) för att implementera underhållsoperationer för indexerade vyer. De normala faciliteterna som tillhandahålls av frågeoptimeraren används för att förenkla och optimera standardunderhållsformen efter behov. Vi ska nu gå till ett exempel för att hjälpa till att sammanföra dessa koncept.
Exempel 1 – Infoga en rad
Anta att vi har följande enkla tabell och indexerad vy:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Efter att skriptet har körts ser data i exempeltabellen ut så här:

Och den indexerade vyn innehåller:

Det enklaste exemplet på en underhållsplan för indexerad vy för den här inställningen inträffar när vi lägger till en enda rad i bastabellen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Utförandeplanen för detta inlägg visas nedan:
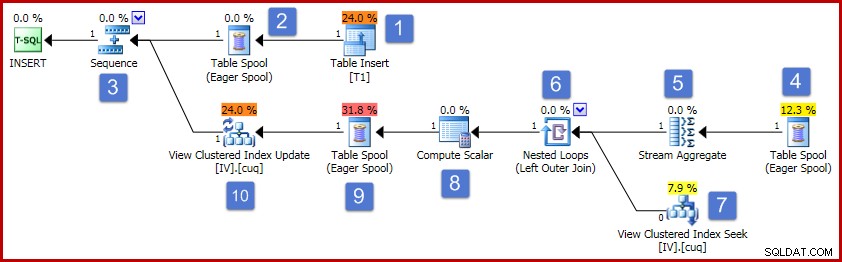
Efter siffrorna i diagrammet fortskrider driften av denna utförandeplan enligt följande:
- Operatorn Tabellinfogning lägger till den nya raden i bastabellen. Detta är den enda planoperatören som är associerad med bastabellinlägget; alla återstående operatörer är intresserade av underhållet av den indexerade vyn.
- Eager Table Spool sparar infogade raddata till tillfällig lagring.
- Sekvensoperatorn säkerställer att planens översta gren körs till slut innan nästa gren i sekvensen aktiveras. I det här speciella fallet (införande av en enstaka rad), skulle det vara giltigt att ta bort sekvensen (och spolarna vid positionerna 2 och 4), genom att direkt ansluta Stream Aggregate-ingången till utgången på Table Insert. Denna möjliga optimering är inte implementerad, så sekvensen och spoolerna finns kvar.
- Denna Eager Table Spool är associerad med spoolen vid position 2 (den har en Primary Nod ID-egenskap som uttryckligen tillhandahåller denna länk). Spolen spelar om rader (en rad i det aktuella fallet) från samma temporära lagring som skrivits till av den primära spolen. Som nämnts ovan är spolarna och positionerna 2 och 4 onödiga och finns helt enkelt för att de finns i den generiska mallen för underhåll av indexerad vy.
- Strömaggregatet beräknar summan av värdekolumndata i den infogade uppsättningen och räknar antalet rader som finns per visningsnyckelgrupp. Utdata är de inkrementella data som behövs för att hålla vyn synkroniserad med basdata. Observera att Stream Aggregate inte har ett Group By-element eftersom frågeoptimeraren vet att bara ett enda värde bearbetas. Optimeraren tillämpar dock inte liknande logik för att ersätta aggregaten med projektioner (summan av ett enstaka värde är bara själva värdet, och räkningen kommer alltid att vara ett för en en rad infogning). Att beräkna summa- och räkningsaggregat för en enskild rad med data är inte en dyr operation, så denna missade optimering är inte mycket att oroa sig för.
- Kombinationen relaterar varje beräknad inkrementell ändring till en befintlig nyckel i den indexerade vyn. Sammanfogningen är en yttre sammanfogning eftersom den nyligen infogade informationen kanske inte motsvarar någon befintlig data i vyn.
- Den här operatorn hittar raden som ska ändras i vyn.
- Compute Scalar har två viktiga ansvarsområden. Först avgör den om varje inkrementell ändring kommer att påverka en befintlig rad i vyn, eller om en ny rad måste skapas. Den gör detta genom att kontrollera om den yttre kopplingen producerade en noll från vysidan av kopplingen. Vår provinlaga är för grupp 3, som för närvarande inte finns i vyn, så en ny rad kommer att skapas. Den andra funktionen i Compute Scalar är att beräkna nya värden för vykolumnerna. Om en ny rad ska läggas till i vyn är detta helt enkelt resultatet av den inkrementella summan från Stream Aggregate. Om en befintlig rad i vyn ska uppdateras, är det nya värdet det befintliga värdet i vyraden plus den inkrementella summan från Stream Aggregate.
- Denna ivriga bordspole är för Halloween-skydd. Det krävs för korrekthet när en infogningsoperation påverkar en tabell som också refereras till på dataåtkomstsidan av frågan. Det krävs tekniskt sett inte om underhållsåtgärden på en rad resulterar i en uppdatering av en befintlig vyrad, men den finns kvar i planen ändå.
- Den sista operatorn i planen är märkt som en uppdateringsoperator, men den kommer att utföra antingen en infogning eller en uppdatering för varje rad den tar emot beroende på värdet på kolumnen "åtgärdskod" som lagts till av Compute Scalar vid nod 8 Mer allmänt kan denna uppdateringsoperatör infoga, uppdatera och ta bort.
Det finns en hel del detaljer där, så för att sammanfatta:
- Aggregerade gruppdata ändras med den unika klustrade nyckeln i vyn. Den beräknar nettoeffekten av förändringarna i bastabellen på varje kolumn per nyckel.
- Den yttre kopplingen kopplar de inkrementella ändringarna per nyckel till befintliga rader i vyn.
- Beräkningsskalären beräknar om en ny rad ska läggas till i vyn eller om en befintlig rad ska uppdateras. Den beräknar de slutliga kolumnvärdena för visningsinfogningen eller uppdateringsoperationen.
- Operatorn för vyuppdatering infogar en ny rad eller uppdaterar en befintlig enligt anvisningarna i åtgärdskoden.
Exempel 2 – Infoga flera rader
Tro det eller ej, exekveringsplanen för den enradiga bastabellen som diskuterades ovan var föremål för ett antal förenklingar. Även om några möjliga ytterligare optimeringar missades (som nämnts), lyckades frågeoptimeraren fortfarande ta bort vissa operationer från den allmänna indexerade vyunderhållsmallen och minska komplexiteten för andra.
Flera av dessa optimeringar var tillåtna eftersom vi bara infogade en enda rad, men andra aktiverades eftersom optimeraren kunde se de bokstavliga värdena som läggs till i bastabellen. Till exempel kan optimeraren se att det infogade gruppvärdet skulle passera predikatet i WHERE-satsen i vyn.
Om vi nu infogar två rader, med värdena "dolda" i lokala variabler, får vi en lite mer komplex plan:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
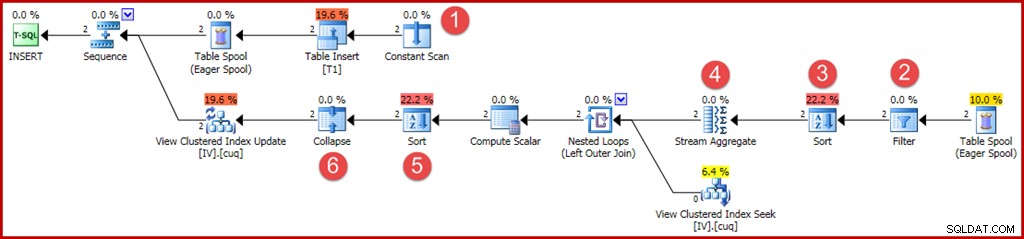
De nya eller ändrade operatorerna är kommenterade som tidigare:
- Constant Scan tillhandahåller värden som ska infogas. Tidigare har en optimering för enradsskär tillät denna operator att utelämnas.
- En explicit filteroperator krävs nu för att kontrollera att grupperna som infogas i bastabellen matchar WHERE-satsen i vyn. Som det händer kommer båda nya raderna att klara testet, men optimeraren kan inte se värdena i variablerna för att veta detta i förväg. Dessutom skulle det inte vara säkert att cachelagra en plan som hoppade över detta filter eftersom en framtida återanvändning av planen kan ha olika värden i variablerna.
- En sortering krävs nu för att säkerställa att raderna anländer till Stream Aggregate i gruppordning. Sorteringen har tidigare tagits bort eftersom det är meningslöst att sortera en rad.
- Strömaggregatet har nu en "grupp efter"-egenskap som matchar vyns unika klustrade nyckel.
- Denna sortering krävs för att presentera rader i view-key, åtgärdskodordning, vilket krävs för korrekt funktion av Collapse-operatorn. Sort är en helt blockerande operatör så det finns inte längre något behov av en ivrig bordspole för Halloween-skydd.
- Den nya Collapse-operatorn kombinerar en intilliggande infogning och radering på samma nyckelvärde till en enda uppdateringsåtgärd. Denna operatör är faktiskt inte obligatorisk i det här fallet eftersom inga raderingsåtgärdskoder kan genereras (endast infogar och uppdateringar). Detta verkar vara ett förbiseende, eller kanske något som lämnats kvar av säkerhetsskäl. De automatiskt genererade delarna av en uppdateringsfrågeplan kan bli extremt komplexa, så det är svårt att veta säkert.
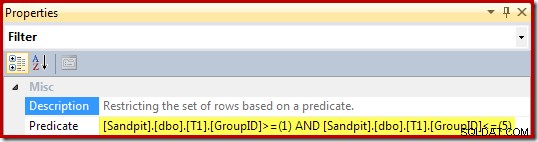
Egenskaperna för filtret (härledda från vyns WHERE-sats) är:
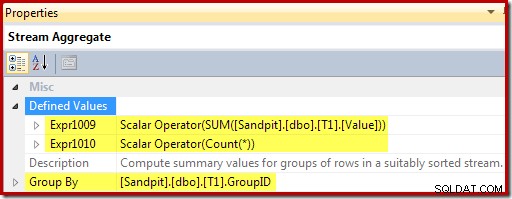
Strömaggregatet grupperar efter vynyckeln och beräknar summan och antalet aggregat per grupp:
Compute Scalar identifierar åtgärden som ska utföras per rad (infoga eller uppdatera i detta fall) och beräknar värdet som ska infogas eller uppdateras i vyn:
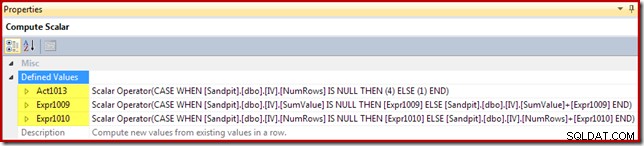
Åtgärdskoden ges uttrycksetiketten [Act1xxx]. Giltiga värden är 1 för en uppdatering, 3 för en borttagning och 4 för en infogning. Detta åtgärdsuttryck resulterar i en infogning (kod 4) om ingen matchande rad hittades i vyn (dvs. den yttre sammanfogningen returnerade en noll för kolumnen NumRows). Om en matchande rad hittades är åtgärdskoden 1 (uppdatering).
Observera att NumRows är namnet på den obligatoriska COUNT_BIG(*) kolumnen i vyn. I en plan som kan resultera i raderingar från vyn, skulle Compute Scalar upptäcka när detta värde skulle bli noll (inga rader för den aktuella gruppen) och generera en raderingsåtgärdskod (3).
De återstående uttrycken behåller summan och räknar aggregat i vyn. Observera dock att uttrycksetiketterna [Expr1009] och [Expr1010] inte är nya; de hänvisar till etiketterna som skapats av Stream Aggregate. Logiken är enkel:om en matchande rad inte hittades är det nya värdet som ska infogas bara det värde som beräknas vid aggregatet. Om en matchande rad i vyn hittades är det uppdaterade värdet det aktuella värdet i raden plus ökningen som beräknats av aggregatet.
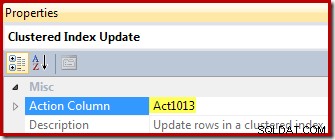
Slutligen visar vyuppdateringsoperatören (visas som en Clustered Index Update i SSMS) åtgärdskolumnreferensen ([Act1013] definierad av Compute Scalar):
Exempel 3 – Flerradsuppdatering
Hittills har vi bara tittat på insatser till basbordet. Utförandeplanerna för en radering är mycket lika, med bara några mindre skillnader i de detaljerade beräkningarna. Detta nästa exempel går därför vidare till att titta på underhållsplanen för en bastabelluppdatering:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Som tidigare använder den här frågan variabler för att dölja bokstavliga värden från optimeraren, vilket förhindrar att vissa förenklingar tillämpas. Det är också noga med att uppdatera två separata grupper, vilket förhindrar optimeringar som kan tillämpas när optimeraren vet att bara en enda grupp (en enda rad i den indexerade vyn) kommer att påverkas. Den kommenterade exekveringsplanen för uppdateringsfrågan finns nedan:
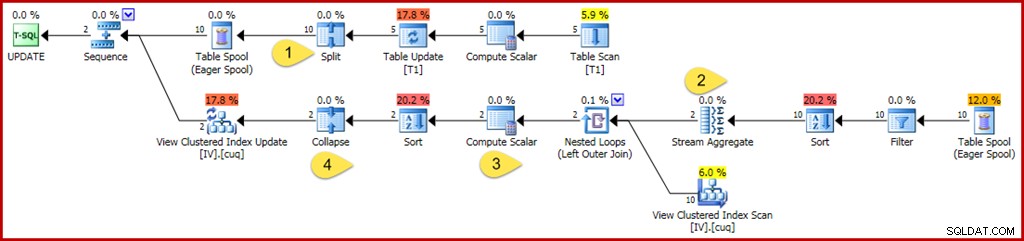
Ändringarna och intressanta platser är:
- Den nya Split-operatorn gör varje uppdatering av bastabellrad till en separat raderings- och infogningsoperation. Varje uppdateringsrad är uppdelad i två separata rader, vilket fördubblar antalet rader efter denna punkt i planen. Split är en del av split-sort-kollapsmönstret som behövs för att skydda mot felaktiga transienta unika nyckelöverträdelser.
- Strömaggregatet är modifierat för att ta hänsyn till inkommande rader som kan specificera antingen en radering eller en infogning (på grund av Split, och bestäms av en åtgärdskodkolumn i raden). En infogningsrad bidrar med det ursprungliga värdet i summaaggregat; tecknet är omvänt för rader med raderåtgärder. På samma sätt räknar radräkningsaggregatet här infoga rader som +1 och rader rader som –1.
- Compute Scalar-logiken är också modifierad för att återspegla att nettoeffekten av ändringarna per grupp kan kräva en eventuell infogning, uppdatering eller borttagning av den materialiserade vyn. Det är faktiskt inte möjligt för den här specifika uppdateringsfrågan att resultera i att en rad infogas eller tas bort mot denna vy, men logiken som krävs för att härleda det är bortom optimerarens nuvarande resonemangsförmåga. En något annorlunda uppdateringsfråga eller vydefinition kan verkligen resultera i en blandning av infoga, ta bort och uppdatera vyåtgärder.
- Komprimeringsoperatorn framhävs enbart för sin roll i mönstret för split-sort-kollaps som nämns ovan. Observera att det bara komprimerar raderingar och infogar på samma tangent; oöverträffade raderingar och infogningar efter Collapsen är fullt möjliga (och ganska vanligt).
Som tidigare är nyckeloperatörsegenskaperna att titta på för att förstå underhållsarbetet för den indexerade vyn Filter, Stream Aggregate, Outer Join och Compute Scalar.
Exempel 4 – Flerradsuppdatering med kopplingar
För att slutföra översikten över underhållsplaner för indexerade vyer behöver vi en ny exempelvy som sammanfogar flera tabeller och inkluderar en projektion i urvalslistan:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); För att säkerställa korrektheten är ett av kraven för indexerad vy att ett summaaggregat inte kan fungera på ett uttryck som kan utvärderas till null. Vydefinitionen ovan använder ISNULL för att uppfylla det kravet. Ett exempel på uppdateringsfråga som producerar en ganska omfattande komponent för indexunderhållsplan visas nedan, tillsammans med exekveringsplanen som den producerar:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
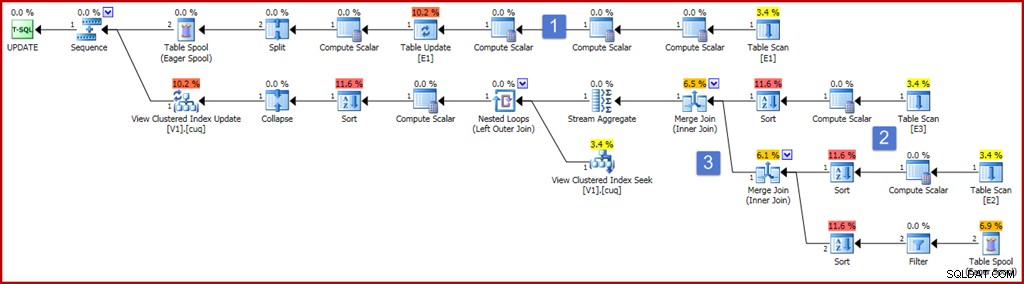
Planen ser ganska stor och komplicerad ut nu, men de flesta elementen är precis som vi redan har sett. De viktigaste skillnaderna är:
- Den översta grenen av planen innehåller ett antal extra Compute Scalar-operatörer. Dessa skulle kunna vara mer kompakt arrangerade, men i huvudsak finns de för att fånga värdena före uppdatering av de icke-grupperande kolumnerna. Beräkningsskalären till vänster om tabelluppdateringen fångar värdet efter uppdateringen av kolumn "a", med ISNULL-projektionen tillämpad.
- De nya Compute Scalars i detta område av planen beräknar värdet som produceras av ISNULL-uttrycket på varje källtabell. I allmänhet kommer projektioner på de sammanfogade tabellerna i vyn att representeras av Compute Scalars här. Sorteringarna i detta område av planen är närvarande enbart för att optimeraren valde en sammanfogningsstrategi av kostnadsskäl (kom ihåg att sammanslagning kräver sammanfogningsnyckelsorterad input).
- De två kopplingsoperatorerna är nya och implementerar helt enkelt kopplingarna i vydefinitionen. Dessa kopplingar visas alltid före Stream Aggregate som beräknar den inkrementella effekten av ändringarna på vyn. Observera att en ändring av en bastabell kan resultera i att en rad som brukade uppfylla kopplingskriterierna inte längre går med, och vice versa. Alla dessa potentiella komplexiteter hanteras korrekt (med tanke på de indexerade vybegränsningarna) genom att Stream Aggregate producerar en sammanfattning av ändringarna per vynyckel efter att anslutningarna har utförts.
Sluta tankar
Den sista planen representerar i stort sett hela mallen för att upprätthålla en indexerad vy, även om tillägget av icke-klustrade index till vyn skulle lägga till ytterligare operatörer som spoolades av utdata från vyuppdateringsoperatören också. Bortsett från en extra Split (och en Sortera och komprimera-kombination om vyns icke-klustrade index är unikt), finns det inget speciellt med denna möjlighet. Att lägga till en utdataklausul till bastabellfrågan kan också producera några intressanta extra operatorer, men återigen, dessa är inte speciella för underhåll av indexerade vyer i sig.
För att sammanfatta den fullständiga övergripande strategin:
- Bastabelländringar tillämpas som vanligt; värden före uppdatering kan fångas.
- En delad operator kan användas för att omvandla uppdateringar till radera/infoga par.
- En ivrig spole sparar information om ändring av bastabellen till tillfällig lagring.
- Alla tabeller i vyn nås, förutom den uppdaterade bastabellen (som läses från spoolen).
- Projektioner i vyn representeras av Compute Scalars.
- Filter i vyn tillämpas. Filter kan tryckas in i skanningar eller sökningar som rester.
- Joins som anges i vyn utförs.
- Ett aggregat beräknar inkrementella nettoförändringar grupperade efter klustrad vynyckel.
- Den inkrementella ändringsuppsättningen är yttre sammanfogad med vyn.
- En Compute Scalar beräknar en åtgärdskod (infoga/uppdatera/ta bort mot vyn) för varje ändring och beräknar de faktiska värdena som ska infogas eller uppdateras. Beräkningslogiken baseras på utdata från aggregatet och resultatet av den yttre kopplingen till vyn.
- Ändringar sorteras i vynyckel- och åtgärdskodordning och komprimeras till uppdateringar efter behov.
- Slutligen tillämpas de inkrementella ändringarna på själva vyn.
Som vi har sett tillämpas den normala uppsättningen verktyg som är tillgängliga för frågeoptimeraren fortfarande på de automatiskt genererade delarna av planen, vilket innebär att ett eller flera av stegen ovan kan förenklas, transformeras eller tas bort helt. Planens grundform och funktion förblir dock intakt.
Om du har följt med kodexemplen kan du använda följande skript för att rensa upp:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;