Exekveringsplaner ger en rik källa till information som kan hjälpa oss att identifiera sätt att förbättra prestandan för viktiga frågor. Människor letar ofta efter saker som stora skanningar och uppslagningar som ett sätt att identifiera potentiella optimeringar av dataåtkomstvägar. Dessa problem kan ofta snabbt lösas genom att skapa ett nytt index eller utöka ett befintligt med fler inkluderade kolumner.
Vi kan också använda efterutförandeplaner för att jämföra faktiska med förväntade radantal mellan planoperatörer. Där dessa visar sig vara avsevärda skillnader kan vi försöka ge bättre statistisk information till optimeraren genom att uppdatera befintlig statistik, skapa nya statistikobjekt, använda statistik på beräknade kolumner eller kanske genom att dela upp en komplex fråga i mindre komplex komponent delar.
Utöver det kan vi också titta på dyra operationer i planen, särskilt minneskrävande sådana som sortering och hash. Sortering kan ibland undvikas genom indexeringsändringar. Andra gånger kanske vi måste omfaktorisera frågan med syntax som gynnar en plan som bevarar en viss önskad ordning.
Ibland kommer prestanda fortfarande inte att vara tillräckligt bra även efter att alla dessa prestationsavstämningstekniker har tillämpats. Ett möjligt nästa steg är att tänka lite mer på planen som helhet . Det innebär att ta ett steg tillbaka, försöka förstå den övergripande strategin som valts av frågeoptimeraren, för att se om vi kan identifiera en algoritmisk förbättring.
Den här artikeln utforskar den senare typen av analys, med hjälp av ett enkelt exempel på problem med att hitta unika kolumnvärden i en måttligt stor datamängd. Som ofta är fallet i analoga verkliga problem kommer kolumnen av intresse att ha relativt få unika värden, jämfört med antalet rader i tabellen. Det finns två delar av denna analys:att skapa exempeldata och att skriva själva frågan om distinkta värden.
Skapa exempeldata
För att ge det enklast möjliga exemplet har vår testtabell bara en enda kolumn med ett klustrat index (denna kolumn kommer att innehålla dubbletter av värden så att indexet inte kan förklaras unikt):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
För att välja några siffror ur luften kommer vi att välja att ladda tio miljoner rader totalt, med en jämn fördelning över tusen distinkta värden . En vanlig teknik för att generera data som denna är att korskoppla några systemtabeller och tillämpa ROW_NUMBER fungera. Vi kommer också att använda modulo-operatorn för att begränsa de genererade talen till önskade distinkta värden:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Den beräknade genomförandeplanen för den frågan är som följer (klicka på bilden för att förstora den om det behövs):

Detta tar cirka 30 sekunder för att skapa exempeldata på min bärbara dator. Det är inte en enorm lång tid på något sätt, men det är ändå intressant att överväga vad vi kan göra för att göra denna process mer effektiv...
Plananalys
Vi börjar med att förstå vad varje operation i planen är till för.
Avsnittet av utförandeplanen till höger om segmentoperatören handlar om tillverkningsrader genom att korsfoga systemtabeller:

Segmentoperatorn finns där om fönsterfunktionen hade en PARTITION BY klausul. Så är inte fallet här, men det finns i frågeplanen ändå. Sekvensprojektoperatören genererar radnumren och toppen begränsar planens utdata till tio miljoner rader:

Compute Scalar definierar uttrycket som tillämpar modulofunktionen och lägger till ett till resultatet:

Vi kan se hur etiketterna Sequence Project och Compute Scalar uttryck relaterar med Plan Explorers Expressions-flik:

Detta ger oss en mer komplett känsla för flödet av denna plan:sekvensprojektet numrerar raderna och märker uttrycket Expr1050; Compute Scalar märker resultatet av modulo- och plus-one-beräkningen som Expr1052 . Lägg även märke till den implicita konverteringen i Compute Scalar-uttrycket. Måltabellkolumnen är av typen heltal, medan ROW_NUMBER funktionen producerar en bigint, så en avsmalnande konvertering är nödvändig.
Nästa operatör i planen är en sortering. Enligt frågeoptimerarens kostnadsberäkningar förväntas detta vara den dyraste operationen (88,1 % uppskattad ):

Det kanske inte är omedelbart uppenbart varför denna plan har sortering, eftersom det inte finns något uttryckligt ordningskrav i frågan. Sorteringen läggs till i planen för att säkerställa att raderna kommer till operatorn Clustered Index Insert i klustrad indexordning. Detta främjar sekventiell skrivning, undviker siddelning och är en av förutsättningarna för minimalt loggade INSERT operationer.
Dessa är alla potentiellt bra saker, men själva sorten är ganska dyr. Faktum är att en kontroll av planen för efterexekveringen ("faktisk") avslöjar att sorteringen också fick slut på minne vid körningstidpunkten och var tvungen att överföras till fysisk tempdb disk:

Sorteringsspillet inträffar trots att det uppskattade antalet rader är exakt rätt, och trots att frågan beviljades allt minne som den bad om (som framgår av planegenskaperna för roten INSERT nod):

Sorteringsspill indikeras också av förekomsten av IO_COMPLETION väntar på Plan Explorer PRO väntestatistikfliken:

Slutligen för denna plananalyssektion, lägg märke till DML Request Sort egenskapen för Clustered Index Insert-operatorn är satt till true:

Denna flagga indikerar att optimeraren kräver att underträdet under Infoga tillhandahåller rader i indexnyckelsorterad ordning (därav behovet av den problematiska Sorteringsoperatorn).
Undvika sorteringen
Nu när vi vet varför Sorteringen visas kan vi testa för att se vad som händer om vi tar bort den. Det finns sätt vi skulle kunna skriva om frågan för att "lura" optimeraren att tro att färre rader skulle infogas (så att sortering inte skulle löna sig) men ett snabbt sätt att undvika sorteringen direkt (endast för experimentändamål) är att använda odokumenterad spårningsflagga 8795. Detta ställer in DML Request Sort egenskapen till false, så rader krävs inte längre för att komma fram till Clustered Index Insert i klustrad nyckelordning:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Den nya frågeplanen efter exekvering är som följer (klicka på bilden för att förstora):

Sorteringsoperatorn har försvunnit, men den nya frågan körs i över 50 sekunder (jämfört med 30 sekunder innan). Det finns ett par anledningar till detta. För det första förlorar vi alla möjligheter till minimalt loggade inlägg eftersom dessa kräver sorterad data (DML Request Sort =true). För det andra kommer ett stort antal "dåliga" siddelningar att inträffa under infogningen. Om det verkar kontraintuitivt, kom ihåg att även om ROW_NUMBER funktionsnummer rader sekventiellt, är effekten av modulo-operatorn att presentera en upprepad sekvens av nummer 1...1000 till Clustered Index Insert.
Samma grundläggande problem uppstår om vi använder T-SQL-trick för att sänka det förväntade radantalet för att undvika sorteringen istället för att använda spårningsflaggan som inte stöds.
Undvika Sortering II
Om man tittar på planen som helhet verkar det tydligt att vi skulle vilja generera rader på ett sätt som undviker en explicit sortering, men som ändå skördar fördelarna med minimal loggning och dålig undvikande av siddelning. Enkelt uttryckt:vi vill ha en plan som presenterar rader i klustrad nyckelordning, men utan sortering.
Med denna nya insikt kan vi uttrycka vår fråga på ett annat sätt. Följande fråga genererar varje nummer från 1 till 1000 och korsfogar den uppsättningen med 10 000 rader för att producera den nödvändiga graden av duplicering. Tanken är att skapa en infogningsuppsättning som presenterar 10 000 rader numrerade '1' sedan 10 000 numrerade '2' … och så vidare.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Tyvärr producerar optimeraren fortfarande en plan med en sort:

Det finns inte mycket att säga i optimerarens försvar här, det här är bara en dum plan. Den har valt att generera 10 000 rader och sedan korsfoga dem med siffror från 1 till 1000. Detta tillåter inte att den naturliga ordningen för talen bevaras, så sorteringen kan inte undvikas.
Undvik sorteringen – äntligen!
Strategin som optimeraren missade är att ta siffrorna 1...1000 först , och korsfoga varje nummer med 10 000 rader (gör 10 000 kopior av varje nummer i följd). Den förväntade planen skulle undvika en sortering genom att använda en kapslad slingkorskoppling som bevarar ordningen av raderna på den yttre ingången.
Vi kan uppnå detta resultat genom att tvinga optimeraren att komma åt de härledda tabellerna i den ordning som anges i frågan, med hjälp av FORCE ORDER frågetips:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Äntligen får vi planen vi var ute efter:
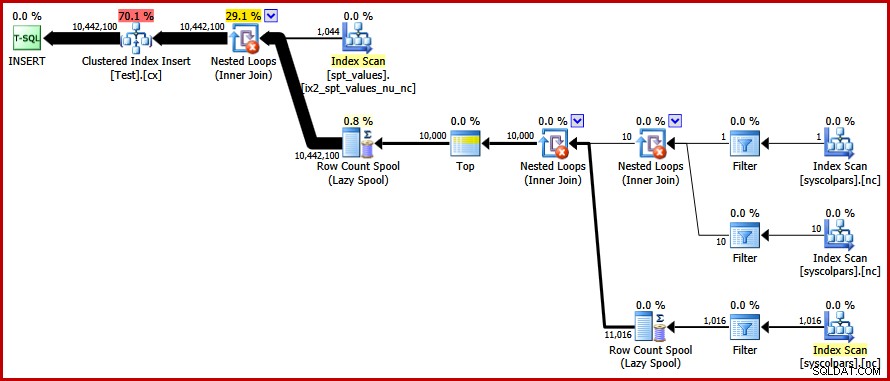
Den här planen undviker en explicit sortering samtidigt som man undviker "dåliga" siddelningar och möjliggör minimalt loggade inlägg till det klustrade indexet (förutsatt att databasen inte använder FULL återställningsmodell). Den laddar alla tio miljoner rader på ungefär 9 sekunder på min bärbara dator (med en enda 7200 rpm SATA-skiva som snurrar). Detta representerar en markant effektivitetsökning under 30-50 sekunder förfluten tid sett innan omskrivningen.
Hitta de distinkta värdena
Nu har vi skapat exempeldata, vi kan rikta vår uppmärksamhet mot att skriva en fråga för att hitta de distinkta värdena i tabellen. Ett naturligt sätt att uttrycka detta krav i T-SQL är följande:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Utförandeplanen är mycket enkel, som du kan förvänta dig:

Detta tar cirka 2900 ms för att köras på min maskin och kräver 43 406 logiskt lyder:

Ta bort MAXDOP (1) frågetips genererar en parallell plan:

Detta slutförs på cirka 1500 ms (men med 8 764 ms förbrukad CPU-tid) och 43 804 logiskt lyder:

Samma planer och resultat blir resultatet om vi använder GROUP BY istället för DISTINCT .
En bättre algoritm
Frågeplanerna som visas ovan läser alla värden från bastabellen och bearbetar dem genom ett Stream Aggregate. Om man tänker på uppgiften som helhet verkar det ineffektivt att skanna alla 10 miljoner rader när vi vet att det finns relativt få distinkta värden.
En bättre strategi kan vara att hitta det enskilt lägsta värdet i tabellen, sedan hitta det näst högsta, och så vidare tills vi får slut på värden. Avgörande är att detta tillvägagångssätt lämpar sig för singelsökning i indexet snarare än att skanna varje rad.
Vi kan implementera denna idé i en enda fråga med en rekursiv CTE, där ankardelen hittar den lägsta distinkt värde, sedan hittar den rekursiva delen nästa distinkta värde och så vidare. Ett första försök att skriva den här frågan är:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Tyvärr kompilerar inte den syntaxen:

Ok, så aggregerade funktioner är inte tillåtna. Istället för att använda MIN , kan vi skriva samma logik med TOP (1) med en ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Fortfarande ingen glädje.
Det visar sig att vi kan komma runt dessa begränsningar genom att skriva om den rekursiva delen för att numrera kandidatraderna i önskad ordning, och sedan filtrera efter raden som är numrerad "ett". Detta kan tyckas lite omständligt, men logiken är exakt densamma:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Den här frågan gör kompilera och producerar följande plan efter utförande:

Lägg märke till Top-operatören i den rekursiva delen av exekveringsplanen (markerad). Vi kan inte skriva en T-SQL TOP i den rekursiva delen av ett rekursivt vanligt tabelluttryck, men det betyder inte att optimeraren inte kan använda ett! Optimeraren introducerar toppen baserat på resonemang om antalet rader som den måste kontrollera för att hitta den numrerade "1".
Prestandan för denna (icke-parallella) plan är mycket bättre än Stream Aggregate-metoden. Det slutförs på cirka 50 ms , med 3007 logiska läsningar mot källtabellen (och 6001 rader lästa från spoolarbetstabellen), jämfört med det tidigare bästa av 1500ms (8764 ms CPU-tid vid DOP 8) och 43 804 logiskt lyder:


Slutsats
Det är inte alltid möjligt att uppnå genombrott i frågeprestanda genom att överväga individuella frågeplanselement på egen hand. Ibland måste vi analysera strategin bakom hela genomförandeplanen och sedan tänka i sidled för att hitta en mer effektiv algoritm och implementering.