Bucketizing datum och tid data innebär att organisera data i grupper som representerar fasta tidsintervall för analytiska ändamål. Ofta är indata tidsseriedata lagrade i en tabell där raderna representerar mätningar tagna med regelbundna tidsintervall. Mätningarna kan till exempel vara temperatur- och luftfuktighetsavläsningar som tas var 5:e minut, och du vill gruppera data med hjälp av timmassor och beräkna aggregat som genomsnitt per timme. Även om tidsseriedata är en vanlig källa för hinkbaserade analyser, är konceptet lika relevant för all data som involverar datum- och tidsattribut och tillhörande mått. Du kanske till exempel vill organisera försäljningsdata i räkenskapsårssegment och beräkna aggregat som det totala försäljningsvärdet per räkenskapsår. I den här artikeln täcker jag två metoder för att samla datum- och tidsdata. Den ena använder en funktion som heter DATE_BUCKET, som i skrivande stund endast är tillgänglig i Azure SQL Edge. En annan använder en anpassad beräkning som emulerar DATE_BUCKET-funktionen, som du kan använda i alla versioner, upplagor och varianter av SQL Server och Azure SQL Database.
I mina exempel kommer jag att använda exempeldatabasen TSQLV5. Du kan hitta skriptet som skapar och fyller i TSQLV5 här och dess ER-diagram här.
DATE_BUCKET
Som nämnts är DATE_BUCKET-funktionen för närvarande endast tillgänglig i Azure SQL Edge. SQL Server Management Studio har redan IntelliSense-stöd, som visas i figur 1:
 Figur 1:Intellisensstöd för DATE_BUCKET i SSMS
Figur 1:Intellisensstöd för DATE_BUCKET i SSMS
Funktionens syntax är följande:
DATE_BUCKET (Ingången ursprung representerar en ankarpunkt på tidens pil. Det kan vara någon av de datatyper som stöds för datum och tid. Om ospecificerat är standard 1900, 1 januari, midnatt. Du kan sedan föreställa dig att tidslinjen är uppdelad i diskreta intervall som börjar med utgångspunkten, där längden på varje intervall baseras på indata hinkbredd och datumdel . Den förra är kvantiteten och den senare är enheten. För att till exempel organisera tidslinjen i 2-månadersenheter skulle du ange 2 som skopbredden indata och månad som datumdelen input.
Ingången tidsstämpel är en godtycklig tidpunkt som måste associeras med dess innehållande hink. Dess datatyp måste matcha datatypen för indata ursprung . Ingången tidsstämpel är datum- och tidsvärdet som är associerat med måtten du registrerar.
Utdata från funktionen är då startpunkten för den innehållande hinken. Datatypen för utdata är den för ingångens tidsstämpel .
Om det inte redan var uppenbart skulle du vanligtvis använda DATE_BUCKET-funktionen som ett grupperingsuppsättningselement i frågans GROUP BY-sats och naturligtvis även returnera den i SELECT-listan, tillsammans med aggregerade mått.
Fortfarande lite förvirrad om funktionen, dess ingångar och dess output? Kanske skulle ett specifikt exempel med en visuell skildring av funktionens logik hjälpa. Jag börjar med ett exempel som använder indatavariabler och senare i artikeln visar det mer typiska sättet att använda det som en del av en fråga mot en indatatabell.
Tänk på följande exempel:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Du kan hitta en visuell skildring av funktionens logik i figur 2.
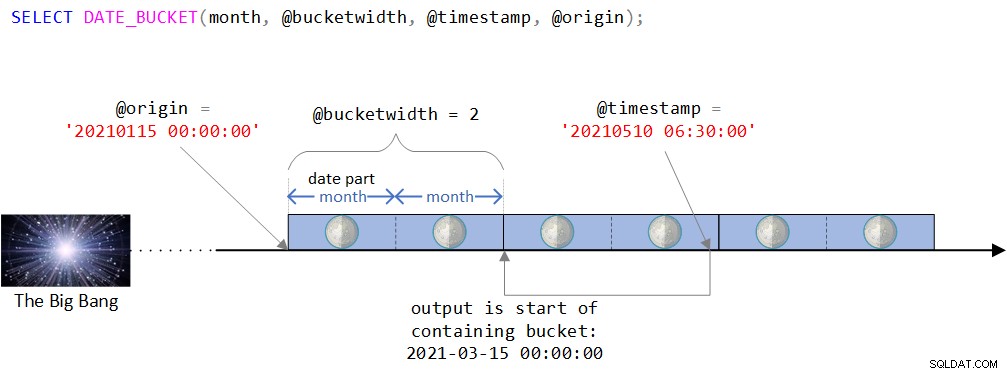 Figur 2:Visuell skildring av DATE_BUCKET-funktionens logik
Figur 2:Visuell skildring av DATE_BUCKET-funktionens logik
Som du kan se i figur 2 är utgångspunkten DATETIME2-värdet 15 januari 2021, midnatt. Om denna ursprungspunkt verkar lite udda, skulle du ha rätt i att intuitivt känna att du normalt skulle använda en mer naturlig, som i början av något år, eller början av en dag. Faktum är att du ofta skulle vara nöjd med standarden, som som du minns är den 1 januari 1900 vid midnatt. Jag ville avsiktligt använda en mindre trivial ursprungspunkt för att kunna diskutera vissa komplexiteter som kanske inte är relevanta när man använder en mer naturlig. Mer om detta inom kort.
Tidslinjen delas sedan in i diskreta 2-månadersintervall som börjar med ursprungspunkten. Inmatningens tidsstämpel är värdet DATETIME2 10 maj 2021, 06:30.
Observera att inmatningstidsstämpeln är en del av hinken som börjar den 15 mars 2021, midnatt. Faktum är att funktionen returnerar detta värde som ett DATUMTIDS2-typat värde:
--------------------------- 2021-03-15 00:00:00.0000000
Emulerar DATE_BUCKET
Om du inte använder Azure SQL Edge, om du vill bucketisera datum- och tidsdata, måste du för närvarande skapa din egen anpassade lösning för att emulera vad DATE_BUCKET-funktionen gör. Att göra det är inte alltför komplicerat, men det är inte heller för enkelt. Att hantera datum- och tidsdata innebär ofta knepig logik och fallgropar som du måste vara försiktig med.
Jag bygger beräkningen i steg och använder samma indata som jag använde med DATE_BUCKET-exemplet som jag visade tidigare:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Se till att du inkluderar den här delen före vart och ett av kodexemplen som jag visar om du verkligen vill köra koden.
I steg 1 använder du DATEDIFF-funktionen för att beräkna skillnaden i datumdel enheter mellan ursprung och tidsstämpel . Jag hänvisar till denna skillnad som diff1 . Detta görs med följande kod:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Med våra exempelinmatningar returnerar detta uttryck 4.
Det knepiga här är att du behöver beräkna hur många hela enheter av datumdel existerar mellan ursprung och tidsstämpel . Med våra exempelingångar är det 3 hela månader mellan de två och inte 4. Anledningen till att DATEDIFF-funktionen rapporterar 4 är att den, när den beräknar skillnaden, bara tittar på den begärda delen av indata och högre delar men inte lägre delar . Så när du frågar efter skillnaden i månader, bryr funktionen sig bara om år och månadsdelar av ingångarna och inte om delarna under månaden (dag, timme, minut, sekund, etc.). Det är faktiskt 4 månader mellan januari 2021 och maj 2021, men ändå bara 3 hela månader mellan de fullständiga ingångarna.
Syftet med steg 2 är då att beräkna hur många hela enheter av datumdel existerar mellan ursprung och tidsstämpel . Jag hänvisar till denna skillnad som diff2 . För att uppnå detta kan du lägga till diff1 enheter av datumdel till ursprung . Om resultatet är större än tidsstämpel , subtraherar du 1 från diff1 för att beräkna diff2 , annars subtrahera 0 och använd därför diff1 som diff2 . Detta kan göras med ett CASE-uttryck, som så:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Detta uttryck returnerar 3, vilket är antalet hela månader mellan de två inmatningarna.
Minns att jag tidigare nämnde att jag i mitt exempel avsiktligt använde en ursprungspunkt som inte är naturlig som en rund början av en period så att jag kan diskutera vissa komplexiteter som då kan vara relevanta. Om du till exempel använder månad som datumdel, och den exakta början av någon månad (1 av någon månad vid midnatt) som ursprung, kan du säkert hoppa över steg 2 och använda diff1 som diff2 . Det beror på att ursprung + diff1 kan aldrig vara> tidsstämpel i ett sådant fall. Mitt mål är dock att tillhandahålla ett logiskt likvärdigt alternativ till DATE_BUCKET-funktionen som skulle fungera korrekt för vilken ursprungspunkt som helst, vanlig eller inte. Så jag ska inkludera logiken för steg 2 i mina exempel, men kom bara ihåg att när du identifierar fall där detta steg inte är relevant kan du säkert ta bort den del där du subtraherar utdata från CASE-uttrycket.
I steg 3 identifierar du hur många enheter av datumdel det finns i hela hinkar som finns mellan ursprung och tidsstämpel . Jag kommer att hänvisa till det här värdet som diff3 . Detta kan göras med följande formel:
diff3 = diff2 / <bucket width> * <bucket width>
Tricket här är att när du använder divisionsoperatorn / i T-SQL med heltalsoperander får du heltalsdivision. Till exempel är 3/2 i T-SQL 1 och inte 1,5. Uttrycket diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Det här uttrycket returnerar 2, vilket är antalet månader i hela 2-månadersperioden som finns mellan de två ingångarna.
I steg 4, som är det sista steget, lägger du till diff3 enheter av datumdel till ursprung för att beräkna början av den innehållande hinken. Här är koden för att uppnå detta:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denna kod genererar följande utdata:
--------------------------- 2021-03-15 00:00:00.0000000
Som ni minns är detta samma utdata som produceras av DATE_BUCKET-funktionen för samma ingångar.
Jag föreslår att du provar detta uttryck med olika ingångar och delar. Jag ska visa några exempel här, men prova gärna dina egna.
Här är ett exempel där ursprung är bara något före tidsstämpel i månaden:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denna kod genererar följande utdata:
--------------------------- 2021-03-10 06:30:01.0000000
Observera att början av den innehållande hinken är i mars.
Här är ett exempel där ursprung är vid samma tidpunkt inom månaden som tidsstämpel :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denna kod genererar följande utdata:
--------------------------- 2021-05-10 06:30:00.0000000
Observera att den här gången börjar den innehållande hinken i maj.
Här är ett exempel med 4-veckors hinkar:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Observera att koden använder veckan del den här gången.
Denna kod genererar följande utdata:
--------------------------- 2021-02-12 00:00:00.0000000
Här är ett exempel med 15-minuters hinkar:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denna kod genererar följande utdata:
--------------------------- 2021-02-03 21:15:00.0000000
Lägg märke till att delen är minuter . I det här exemplet vill du använda 15-minuters hinkar som börjar vid botten av timmen, så en ursprungspunkt som är botten av vilken timme som helst skulle fungera. Faktum är att en ursprungspunkt som har en minutenhet på 00, 15, 30 eller 45 med nollor i nedre delar, med vilket datum och vilken timme som helst, skulle fungera. Så standarden som DATE_BUCKET-funktionen använder för indata ursprung skulle jobba. Naturligtvis, när du använder det anpassade uttrycket, måste du vara tydlig om ursprungspunkten. Så för att sympatisera med DATE_BUCKET-funktionen kan du använda basdatumet vid midnatt som jag gör i exemplet ovan.
Kan du för övrigt se varför detta skulle vara ett bra exempel där det är helt säkert att hoppa över steg 2 i lösningen? Om du verkligen valde att hoppa över steg 2 får du följande kod:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Uppenbarligen blir koden betydligt enklare när steg 2 inte behövs.
Gruppera och aggregera data efter datum- och tidssegment
Det finns fall där du behöver samla datum- och tidsdata som inte kräver sofistikerade funktioner eller otympliga uttryck. Anta till exempel att du vill fråga vyn Sales.OrderValues i TSQLV5-databasen, gruppera data årligen och beräkna totala orderantalet och värden per år. Uppenbarligen räcker det med att använda YEAR(orderdate)-funktionen som grupperingsuppsättningselement, som så:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Denna kod genererar följande utdata:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Men tänk om du ville fördela uppgifterna efter din organisations räkenskapsår? Vissa organisationer använder ett räkenskapsår för redovisnings-, budget- och finansiell rapporteringsändamål, inte i linje med kalenderåret. Säg till exempel att din organisations räkenskapsår fungerar enligt en räkenskapskalender från oktober till september och betecknas av det kalenderår då räkenskapsåret slutar. Så en händelse som ägde rum den 3 oktober 2018 tillhör räkenskapsåret som började den 1 oktober 2018, avslutades den 30 september 2019 och betecknas med år 2019.
Detta är ganska lätt att uppnå med DATE_BUCKET-funktionen, som så:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Och här är koden som använder den anpassade logiska motsvarigheten till DATE_BUCKET-funktionen:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Denna kod genererar följande utdata:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Jag använde variabler här för hinkens bredd och ursprungspunkten för att göra koden mer generaliserad, men du kan ersätta dem med konstanter om du alltid använder samma, och sedan förenkla beräkningen efter behov.
Som en liten variation av ovanstående, anta att ditt räkenskapsår löper från 15 juli ett kalenderår till 14 juli nästa kalenderår och betecknas av det kalenderår som räkenskapsårets början tillhör. Så en händelse som ägde rum den 18 juli 2018 tillhör räkenskapsåret 2018. En händelse som ägde rum den 14 juli 2018 tillhör räkenskapsåret 2017. Med funktionen DATE_BUCKET skulle du uppnå detta så här:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Du kan se ändringarna jämfört med föregående exempel i kommentarerna.
Och här är koden som använder den anpassade logiska motsvarigheten till DATE_BUCKET-funktionen:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Denna kod genererar följande utdata:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Självklart finns det alternativa metoder du kan använda i specifika fall. Ta exemplet före det sista, där räkenskapsåret sträcker sig från oktober till september och betecknas med det kalenderår då räkenskapsåret slutar. I ett sådant fall kan du använda följande, mycket enklare, uttryck:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Och då skulle din fråga se ut så här:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Men om du vill ha en generaliserad lösning som skulle fungera i många fler fall, och som du skulle kunna parametrisera, skulle du naturligtvis vilja använda den mer generella formen. Om du har tillgång till DATE_BUCKET-funktionen är det bra. Om du inte gör det kan du använda den anpassade logiska motsvarigheten.
Slutsats
DATE_BUCKET-funktionen är en ganska behändig funktion som gör att du kan samla datum- och tidsdata. Det är användbart för att hantera tidsseriedata, men också för att samla in data som involverar datum- och tidsattribut. I den här artikeln förklarade jag hur DATE_BUCKET-funktionen fungerar och gav en anpassad logisk motsvarighet om plattformen du använder inte stöder den.