Strängdatatypen är en av de viktigaste datatyperna i alla programmeringsspråk. Du kan knappast skriva ett användbart program utan det. Ändå känner många utvecklare inte till vissa aspekter av denna typ. Låt oss därför överväga dessa aspekter.
Representation av strängar i minnet
I .Net är strängar lokaliserade enligt BSTR-regeln (Basic string eller binary string). Denna metod för strängdatarepresentation används i COM (ordet "basic" kommer från Visual Basic-programmeringsspråket som det ursprungligen användes i). Som vi vet används PWSZ (Pointer to Wide-character String, Zero-terminated) i C/C++ för representation av strängar. Med en sådan plats i minnet finns en nollterminerad i slutet av en sträng. Denna terminator gör det möjligt att bestämma slutet av strängen. Stränglängden i PWSZ begränsas endast av en volym ledigt utrymme.
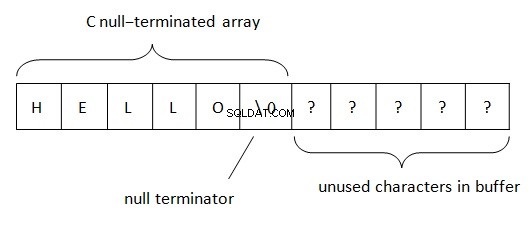
I BSTR är situationen något annorlunda.
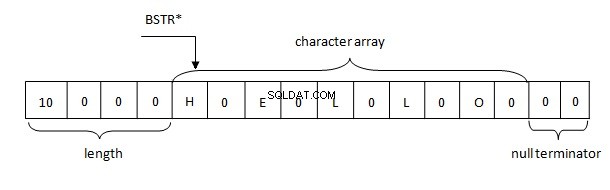
Grundläggande aspekter av BSTR-strängrepresentationen i minnet är följande:
- Stränglängden är begränsad av ett visst antal. I PWSZ begränsas stränglängden av tillgången på ledigt minne.
- BSTR-strängen pekar alltid på det första tecknet i bufferten. PWSZ kan peka på vilket tecken som helst i bufferten.
- I BSTR, liknande PWSZ, finns nolltecknet alltid i slutet. I BSTR är nolltecknet ett giltigt tecken och kan hittas var som helst i strängen.
- Eftersom nollterminatorn är placerad i slutet är BSTR kompatibel med PWSZ, men inte tvärtom.
Därför representeras strängar i .NET i minnet enligt BSTR-regeln. Bufferten innehåller en stränglängd på 4 byte följt av två bytestecken av en sträng i UTF-16-formatet, som i sin tur följs av två nollbyte (\u0000).
Att använda den här implementeringen har många fördelar:stränglängden får inte räknas om eftersom den är lagrad i rubriken, en sträng kan innehålla nolltecken var som helst. Och det viktigaste är att adressen till en sträng (nålad) enkelt kan skickas över ursprunglig kod där WCHAR* förväntas.
Hur mycket minne tar ett strängobjekt?
Jag stötte på artiklar som säger att strängobjektets storlek är lika med size=20 + (längd/2)*4, men den här formeln är inte helt korrekt.
Till att börja med är en sträng en länktyp, så de första fyra byten innehåller SyncBlockIndex och de nästa fyra byten innehåller typpekaren.
Strängstorlek =4 + 4 + …
Som jag nämnde ovan lagras stränglängden i bufferten. Det är ett int-typfält, därför måste vi lägga till ytterligare 4 byte.
Strängstorlek =4 + 4 + 4 + …
För att snabbt överföra en sträng till ursprunglig kod (utan att kopiera), finns nullterminatorn i slutet av varje sträng som tar 2 byte. Därför
Strängstorlek =4 + 4 + 4 + 2 + …
Det enda som återstår är att komma ihåg att varje tecken i en sträng finns i UTF-16-kodningen och även tar 2 byte. Därför:
Strängstorlek =4 + 4 + 4 + 2 + 2 * längd =14 + 2 * längd
En sak till och vi är klara. Minnet som allokeras av minneshanteraren i CLR är multipel av 4 byte (4, 8, 12, 16, 20, 24, …). Så om stränglängden tar 34 byte totalt, kommer 36 byte att tilldelas. Vi måste avrunda vårt värde till närmaste större tal som är multipel av fyra. För detta behöver vi:
Strängstorlek =4 * ((14 + 2 * längd + 3) / 4) (heltalsdivision)
Frågan om versioner :fram till .NET v4 fanns det ytterligare en m_arrayLength fält av typen int i klassen String som tog 4 byte. Detta fält är en reell längd på bufferten som allokerats för en sträng, inklusive nollterminatorn, dvs det är längd + 1. I .NET 4.0 togs detta fält bort från klassen. Som ett resultat upptar ett objekt av strängtyp 4 byte mindre.
Storleken på en tom sträng utan m_arrayLength fält (dvs. i .Net 4.0 och högre) är lika med =4 + 4 + 4 + 2 =14 byte, och med detta fält (dvs. lägre än .Net 4.0) är dess storlek lika med =4 + 4 + 4 + 4 + 2 =18 byte. Om vi rundar av 4 byte blir storleken 16 och 20 byte, motsvarande.
Strängaspekter
Så vi övervägde representationen av strängar och storleken de tar i minnet. Låt oss nu prata om deras egenheter.
Grundläggande aspekter av strängar i .NET är följande:
- Strängar är referenstyper.
- Strängar är oföränderliga. När en sträng väl har skapats kan den inte ändras (på rättvisa sätt). Varje anrop av metoden för den här klassen returnerar en ny sträng, medan den föregående strängen blir ett byte för sopsamlaren.
- Strängar omdefinierar Object.Equals-metoden. Som ett resultat jämför metoden teckenvärden i strängar, inte länkvärden.
Låt oss överväga varje punkt i detalj.
Strängar är referenstyper
Strängar är riktiga referenstyper. Det vill säga att de alltid ligger i hög. Många av oss förväxlar dem med värdetyper, eftersom du beter dig på samma sätt. De är till exempel oföränderliga och deras jämförelse utförs efter värde, inte av referenser, men vi måste komma ihåg att det är en referenstyp.
Strängar är oföränderliga
- Strängar är oföränderliga för ett ändamål. Strängens oföränderlighet har ett antal fördelar:
- Strängtyp är trådsäker, eftersom inte en enda tråd kan ändra innehållet i en sträng.
- Användning av oföränderliga strängar leder till minskad minnesbelastning, eftersom det inte finns något behov av att lagra 2 instanser av samma sträng. Som ett resultat går mindre minne åt och jämförelsen utförs snabbare, eftersom endast referenser jämförs. I .NET kallas denna mekanism för stränginterning (strängpool). Vi kommer att prata om det lite senare.
- När vi skickar en oföränderlig parameter till en metod kan vi sluta oroa oss för att den kommer att ändras (om den inte skickades som ref eller ut, förstås).
Datastrukturer kan delas in i två typer:tillfälliga och ihållande. Efemära datastrukturer lagrar endast sina senaste versioner. Beständiga datastrukturer sparar alla sina tidigare versioner under modifiering. De senare är i själva verket oföränderliga, eftersom deras verksamhet inte ändrar strukturen på plats. Istället returnerar de en ny struktur som är baserad på den tidigare.
Med tanke på att strängar är oföränderliga kan de vara beständiga, men det är de inte. Strängar är tillfälliga i .Net.
För jämförelse, låt oss ta Java-strängar. De är oföränderliga, som i .NET, men dessutom är de beständiga. Implementeringen av klassen String i Java ser ut som följer:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Förutom 8 byte i objektets rubrik, inklusive en referens till typen och en referens till ett synkroniseringsobjekt, innehåller strängar följande fält:
- En referens till en char-array;
- Ett index för det första tecknet i strängen i char-arrayen (offset från början)
- Antalet tecken i strängen;
- Hashkoden beräknas efter första anropet av HashCode() metod.
Strängar i Java tar mer minne än i .NET, eftersom de innehåller ytterligare fält som gör att de kan vara beständiga. På grund av persistens, exekveringen av String.substring() metod i Java tar O(1) , eftersom det inte kräver strängkopiering som i .NET, där exekvering av denna metod tar O(n) .
Implementering av metoden String.substring() i Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Men om en källsträng är tillräckligt stor och den utklippta delsträngen är på flera tecken lång, kommer hela arrayen av tecken i den initiala strängen att vänta i minnet tills det finns en referens till delsträngen. Eller, om du serialiserar den mottagna delsträngen med standardmetoder och skickar den över nätverket, kommer hela den ursprungliga arrayen att serialiseras och antalet byte som skickas över nätverket kommer att vara stort. Därför istället för koden
s =ss.substring(3)
följande kod kan användas:
s =new String(ss.substring(3)),
Den här koden kommer inte att lagra referensen till arrayen av tecken i källsträngen. Istället kopierar den bara den faktiskt använda delen av arrayen. Förresten, om vi anropar denna konstruktor på en sträng vars längd är lika med längden på arrayen av tecken, kommer kopiering inte att ske. Istället kommer referensen till den ursprungliga arrayen att användas.
Som det visade sig har implementeringen av strängtypen ändrats i den senaste versionen av Java. Nu finns det inga offset- och längdfält i klassen. Den nya hash32 (med annan hashalgoritm) har introducerats istället. Det betyder att strängar inte längre är ihållande. Nu, String.substring metod kommer att skapa en ny sträng varje gång.
Sträng omdefinierar Onbject.Equals
Strängklassen omdefinierar Object.Equals-metoden. Som ett resultat sker jämförelse, men inte genom referens, utan genom värde. Jag antar att utvecklare är tacksamma mot skapare av String-klassen för att de omdefinierar ==-operatorn, eftersom kod som använder ==för strängjämförelse ser mer djupgående ut än metodanropet.
if (s1 == s2)
Jämfört med
if (s1.Equals(s2))
Förresten, i Java jämför ==-operatorn med referens. Om du behöver jämföra strängar efter tecken måste vi använda metoden string.equals().
Stränginternering
Låt oss slutligen överväga stränginternering. Låt oss ta en titt på ett enkelt exempel – en kod som vänder på en sträng.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Uppenbarligen kan den här koden inte kompileras. Kompilatorn kommer att skicka fel för dessa strängar, eftersom vi försöker modifiera innehållet i strängen. Vilken metod som helst i klassen String returnerar en ny instans av strängen istället för dess innehållsändring.
Strängen kan ändras, men vi kommer att behöva använda den osäkra koden. Låt oss överväga följande exempel:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Efter exekvering av denna kod, elbatummi era sgnirtS kommer att skrivas in i strängen, som förväntat. Föränderlighet av strängar leder till ett fint fall relaterat till stränginterning.
Stränginternering är en mekanism där liknande bokstaver representeras i minnet som ett enda objekt.
Kort sagt, poängen med stränginternering är följande:det finns en enda hashad intern tabell i en process (inte inom en applikationsdomän), där strängar är dess nycklar och värden är referenser till dem. Under JIT-kompilering placeras bokstavliga strängar i en tabell sekventiellt (varje sträng i en tabell kan bara hittas en gång). Under körning tilldelas referenser till bokstavliga strängar från den här tabellen. Under körningen kan vi placera en sträng i den interna tabellen med String.Intern metod. Vi kan också kontrollera tillgängligheten för en sträng i den interna tabellen med hjälp av String.IsInterned metod.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Observera att endast strängliteraler är internerade som standard. Eftersom den hashade interna tabellen används för interneringsimplementering, utförs sökningen mot denna tabell under JIT-kompilering. Denna process tar lite tid. Så om alla strängar är internerade kommer det att reducera optimeringen till noll. Under kompilering till IL-kod sammanfogar kompilatorn alla bokstavliga strängar, eftersom det inte finns något behov av att lagra dem i delar. Därför returnerar den andra likheten true .
Låt oss nu återgå till vårt fall. Tänk på följande kod:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Det verkar som att allt är ganska uppenbart och koden bör returnera Strängar är oföränderliga . Det gör det dock inte! Koden returnerarelbatummi era sgnirtS . Det händer precis på grund av internering. När vi modifierar strängar, modifierar vi dess innehåll, och eftersom det är bokstavligt, interneras det och representeras av en enda instans av strängen.
Vi kan överge stränginternering om vi använder CompilationRelaxationsAttribute attribut till församlingen. Det här attributet kontrollerar noggrannheten hos koden som skapas av JIT-kompilatorn för CLR-miljön. Konstruktören av det här attributet accepterar CompilationRelaxations uppräkning, som för närvarande endast inkluderar CompilationRelaxations.NoStringInterning . Som ett resultat av detta markeras sammansättningen som den som inte kräver internering.
Förresten, detta attribut bearbetas inte i .NET Framework v1.0. Det är därför det var omöjligt att inaktivera internering. Från och med version 2, mscorlib assembly är märkt med detta attribut. Så det visar sig att strängar i .NET kan modifieras med den osäkra koden.
Vad händer om vi glömmer osäkra?
När det händer kan vi ändra stränginnehåll utan den osäkra koden. Istället kan vi använda reflektionsmekanismen. Detta trick var framgångsrikt i .NET fram till version 2.0. Efteråt berövade utvecklare av String-klassen oss denna möjlighet. I .NET 2.0 har klassen String två interna metoder:SetChar för gränskontroll och InternalSetCharNoBoundsCheck som inte gör gränskontroll. Dessa metoder ställer in det angivna tecknet med ett visst index. Implementeringen av metoderna ser ut på följande sätt:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Därför kan vi modifiera strängens innehåll utan osäker kod med hjälp av följande kod:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Som förväntat returnerar koden elbatummi era sgnirtS .
Frågan om versioner :i olika versioner av .NET Framework kan string.Empty integreras eller inte. Låt oss överväga följande kod:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); I .NET Framework 1.0, .NET Framework 1.1 och .NET Framework 3.5 med 1 (SP1) Service Pack, str1 och str2 är inte lika. För närvarande är string.Empty är inte internerad.
Aspekter av prestanda
Det finns en negativ bieffekt av internering. Saken är att referensen till ett String-internerat objekt lagrat av CLR kan sparas även efter avslutat programarbete och även efter slutet av programdomänarbete. Därför är det bättre att inte använda stora bokstavliga strängar. Om det fortfarande krävs måste internering inaktiveras genom att använda CompilationRelaxations attribut till montering.