Du arbetar med en utvecklare som rapporterar långsam prestanda för följande lagrade proceduranrop:
EXEC [dbo].[charge_by_date] '2/28/2013';
Du frågar vilket problem utvecklaren ser, men den enda ytterligare information du hör är att den "går långsamt". Så du hoppar på SQL Server-instansen och tar en titt på den faktiska genomförandeplan. Du gör detta för att du inte bara är intresserad av hur genomförandeplanen ser ut utan också vad det uppskattade kontra faktiska antalet rader är för planen:
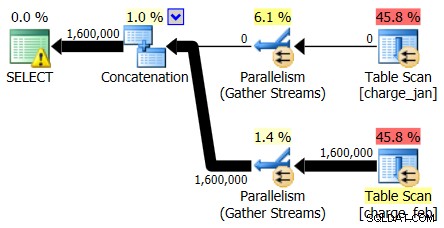
Om du först tittar bara på planoperatörerna kan du se några anmärkningsvärda detaljer:
- Det finns en varning i rotoperatorn
- Det finns en tabellsökning för båda tabellerna som refereras till på bladnivå (charge_jan och charge_feb) och du undrar varför dessa båda fortfarande är högar och inte har klustrade index
- Du ser att det bara finns rader som flyter genom tabellen charge_feb och inte tabellen charge_jan
- Du ser parallella zoner i planen
När det gäller varningen i rot-iteratorn, håller du muspekaren över den och ser att det saknas indexvarningar med en rekommendation för följande index:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Du frågar den ursprungliga databasutvecklaren varför det inte finns ett klustrat index, och svaret är "Jag vet inte."
Om du fortsätter undersökningen innan du gör några ändringar, tittar du på fliken Plan Tree i SQL Sentry Plan Explorer och du ser verkligen att det finns betydande snedvridningar mellan de beräknade kontra faktiska raderna för en av tabellerna:

Det verkar finnas två problem:
- En underskattning för rader i charge_jan-tabellsökningen
- En överskattning för rader i charge_feb-tabellsökningen
Så kardinalitetsuppskattningarna är skevt, och du undrar om detta är relaterat till parametersnuffning. Du bestämmer dig för att kontrollera det parameterkompilerade värdet och jämföra det med parameterns körtidsvärde, som du kan se på fliken Parametrar:

Det finns faktiskt skillnader mellan körtidsvärdet och det kompilerade värdet. Du kopierar över databasen till en prod-liknande testmiljö och testar sedan körningen av den lagrade proceduren med körtidsvärdet 2013-02-28 först och sedan 2013-1-31 efteråt.
Planerna 2013-02-28 och 2013-1-31 har identiska former men olika faktiska dataflöden. Planen 2013-02-28 och uppskattningar av kardinalitet var följande:
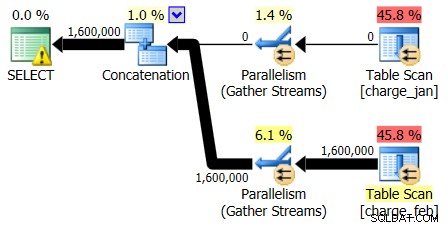

Och medan planen 28/2/2013 inte visar några problem med uppskattning av kardinalitet, gör planen 1/31/2013:
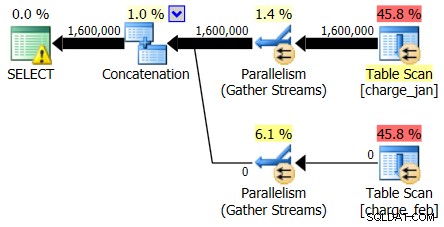

Så den andra planen visar samma över- och underskattningar, precis omvänt från den ursprungliga planen du tittade på.
Du bestämmer dig för att lägga till de föreslagna indexen till den prod-liknande testmiljön för både charge_jan och charge_feb-tabellerna och se om det hjälper överhuvudtaget. När du kör de lagrade procedurerna i januari/februari-ordning, ser du följande nya planformer och tillhörande kardinalitetsuppskattningar:
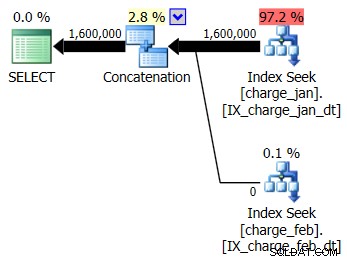

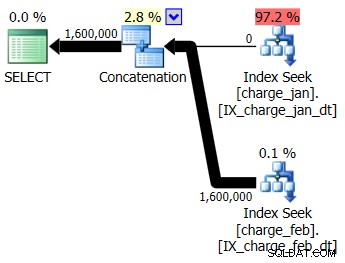

Den nya planen använder en indexsökningsoperation från varje tabell, men du ser fortfarande noll rader som flödar från den ena tabellen och inte den andra, och du ser fortfarande skevheter i kardinalitetsuppskattningen baserad på parametersniffning när körtidsvärdet är i en annan månad än kompileringen tidsvärde.
Ditt team har en policy att inte lägga till index utan bevis på tillräcklig nytta och tillhörande regressionstestning. Du bestämmer dig för tillfället att ta bort de icke-klustrade indexen du just skapat. Även om du inte omedelbart åtgärdar de saknade klustrade index, du bestämmer dig för att ta hand om det senare.
Vid det här laget inser du att du måste titta närmare på definitionen av lagrad procedur, som är följande:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Därefter tittar du på charge_view-objektdefinitionen:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Vyn refererar till avgiftsdata som är uppdelade i olika tabeller efter datum. Och sedan undrar du om den andra skevningen av exekveringsplanen för frågor kan förhindras genom att ändra definitionen av den lagrade proceduren.
Om optimeraren vet vad värdet är vid körning, kanske problemet med kardinalitetsuppskattning försvinner och förbättrar den övergripande prestandan?
Du går vidare och omdefinierar det lagrade proceduranropet enligt följande, och lägger till ett RECOMPILE-tips (med vetskap om att du också har hört att detta kan öka CPU-användningen, men eftersom detta är en testmiljö känner du dig trygg med att prova):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Du kör sedan om den lagrade proceduren med värdet 1/31/2013 och sedan 2/28/2013 värdet.
Planformen förblir densamma, men nu är problemet med kardinalitetsberäkningar borttaget.
Uppskattningen av kardinalitetsdata från 31/1/2013 visar:

Och data för 2013-02-28 uppskattning av kardinalitet visar:

Det gör dig glad för ett ögonblick, men sedan inser du att varaktigheten av den övergripande sökningen verkar vara relativt densamma som den var tidigare. Du börjar tvivla på att utvecklaren kommer att vara nöjd med dina resultat. Du har löst kardinalitetsuppskattningen, men utan den förväntade prestationsökningen är du osäker på om du har hjälpt till på något meningsfullt sätt.
Det är vid denna tidpunkt som du inser att exekveringsplanen för frågor bara är en delmängd av informationen du kan behöva, så du utökar din utforskning ytterligare genom att titta på fliken Tabell I/O. Du ser följande utdata för körningen 31/1/2013:

Och för körningen 2013-02-28 ser du liknande data:

Det är då du undrar om dataåtkomsten fungerar för båda tabeller är nödvändiga i varje plan. Om optimeraren vet att du bara behöver rader för januari, varför överhuvudtaget få tillgång till februari och vice versa? Du kommer också ihåg att frågeoptimeraren inte har några garantier för att det inte finns faktiska rader från de andra månaderna i "fel" tabell såvida inte sådana garantier uttryckligen gjordes via begränsningar på själva tabellen.
Du kontrollerar tabelldefinitionerna via sp_help för varje tabell och du ser inga begränsningar definierade för någon tabell.
Så som ett test lägger du till följande två begränsningar:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Du kör om de lagrade procedurerna och ser följande planformer och kardinalitetsuppskattningar.
31/1/2013 avrättning:
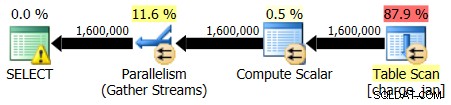

2013-02-28 utförande:


När du tittar på tabell I/O igen, ser du följande utdata för körningen 1/31/2013:

Och för körningen 2013-02-28 ser du liknande data, men för tabellen charge_feb:

Kom ihåg att du fortfarande har RECOMPILE i den lagrade procedurdefinitionen, försöker du ta bort den och se om du ser samma effekt. När du har gjort detta ser du återgången med två tabeller, men utan några faktiska logiska läsningar för tabellen som inte har några rader i sig (jämfört med den ursprungliga planen utan begränsningarna). Till exempel visade körningen 1/31/2013 följande tabell I/O-utgång:

Du bestämmer dig för att gå vidare med lasttestning av de nya CHECK-begränsningarna och RECOMPILE-lösningen, vilket tar bort tabellåtkomsten helt från planen (och de tillhörande planoperatörerna). Du förbereder dig också för en debatt om den klustrade indexnyckeln och ett lämpligt stödjande icke-klustrat index som kommer att rymma en bredare uppsättning arbetsbelastningar som för närvarande har åtkomst till de associerade tabellerna.