Att hantera en PostgreSQL-installation innebär inspektion och kontroll över ett brett spektrum av aspekter i mjukvaran/infrastrukturstacken som PostgreSQL körs på. Detta måste täcka:
- Applikationsjustering angående databasanvändning/transaktioner/anslutningar
- Databaskod (frågor, funktioner)
- Databassystem (prestanda, HA, säkerhetskopior)
- Hårdvara/infrastruktur (diskar, CPU/minne)
PostgreSQL core tillhandahåller databasskiktet på vilket vi litar på att vår data lagras, bearbetas och serveras. Det ger också all teknik för att ha ett riktigt modernt, effektivt, pålitligt och säkert system. Men ofta är denna teknik inte tillgänglig som en färdig att använda, förfinad affärs-/företagsklassprodukt i kärndistributionen av PostgreSQL. Istället finns det många produkter/lösningar antingen från PostgreSQL-communityt eller kommersiella erbjudanden som fyller dessa behov. Dessa lösningar kommer antingen som användarvänliga förbättringar av kärnteknologierna, eller förlängningar av kärnteknologierna eller till och med som integration mellan PostgreSQL-komponenter och andra komponenter i systemet. I vår tidigare blogg med titeln Tio tips för att gå in i produktion med PostgreSQL, tittade vi på några av de verktyg som kan hjälpa till att hantera en PostgreSQL-installation i produktion. I den här bloggen kommer vi att utforska mer i detalj de aspekter som måste täckas när man hanterar en PostgreSQL-installation i produktion, och de mest använda verktygen för detta ändamål. Vi kommer att täcka följande ämnen:
- Implementering
- Hantering
- Skalning
- Övervakning
Implementering
Förr i tiden brukade folk ladda ner och kompilera PostgreSQL för hand och sedan konfigurera runtime-parametrarna och användarens åtkomstkontroll. Det finns fortfarande några fall där detta kan behövas, men när systemen mognade och började växa uppstod behovet av mer standardiserade sätt att distribuera och hantera Postgresql. De flesta operativsystem tillhandahåller paket för att installera, distribuera och hantera PostgreSQL-kluster. Debian har standardiserat sin egen systemlayout som stöder många Postgresql-versioner och många kluster per version samtidigt. postgresql-common debianpaketet tillhandahåller de nödvändiga verktygen. För att till exempel skapa ett nytt kluster (kallat i18n_cluster) för PostgreSQL version 10 i Debian, kan vi göra det genom att ge följande kommandon:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsUppdatera sedan systemd:
$ sudo systemctl daemon-reloadoch slutligen starta och använda det nya klustret:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(observera att Debian hanterar olika kluster genom att använda olika portar 5432, 5433 och så vidare)
I takt med att behovet växer av mer automatiserade och massiva implementeringar, använder fler och fler installationer automationsverktyg som Ansible, Chef och Puppet. Förutom automatisering och reproducerbarhet av distributioner, är automationsverktyg fantastiska eftersom de är ett trevligt sätt att dokumentera distributionen och konfigurationen av ett kluster. Å andra sidan har automatisering utvecklats till att bli ett stort område på egen hand, vilket kräver skickliga personer för att skriva, hantera och köra automatiserade skript. Mer information om PostgreSQL provisionering finns i den här bloggen:Bli en PostgreSQL DBA:Provisioning and Deployment.
Hantering
Att hantera ett livesystem innefattar uppgifter som:schemalägga säkerhetskopieringar och övervaka deras status, katastrofåterställning, konfigurationshantering, hantering av hög tillgänglighet och automatisk failover-hantering. Säkerhetskopiering av ett Postgresql-kluster kan göras på olika sätt. Lågnivåverktyg:
- traditionell pg_dump (logisk säkerhetskopia)
- Säkerhetskopiering på filsystemnivå (fysisk säkerhetskopiering)
- pg_basebackup (fysisk backup)
Eller högre nivå:
- Barman
- PgBackRest
Vart och ett av dessa sätt täcker olika användningsfall och återställningsscenarier och varierar i komplexitet. PostgreSQL-säkerhetskopiering är nära relaterat till begreppen PITR, WAL-arkivering och replikering. Genom åren har proceduren att ta, testa och slutligen (håller tummarna!) använda säkerhetskopior med PostgreSQL utvecklats till att vara en komplex uppgift. Man kan hitta en bra översikt över backuplösningarna för PostgreSQL i den här bloggen:Top Backup Tools for PostgreSQL.
När det gäller hög tillgänglighet och automatisk failover är det absoluta minimum som en installation måste ha för att implementera detta:
- En fungerande primär
- En hot standby som accepterar WAL streamas från den primära
- I händelse av misslyckad primär, en metod för att tala om för den primära att den inte längre är den primära (kallas ibland STONITH)
- En hjärtslagsmekanism för att kontrollera anslutningen mellan de två servrarna och tillståndet för den primära
- En metod för att utföra failover (t.ex. via pg_ctl promotion eller triggerfil)
- En automatiserad procedur för att återskapa det gamla primära som ett nytt beredskapsläge:När ett avbrott eller fel på det primära upptäcks måste ett beredskapsläge främjas som det nya primära. Den gamla primära är inte längre giltig eller användbar. Så systemet måste ha ett sätt att hantera detta tillstånd mellan failover och återskapandet av den gamla primära servern som ny standby. Detta tillstånd kallas degenererat tillstånd, och PostgreSQL tillhandahåller ett verktyg som heter pg_rewind för att påskynda processen att återföra den gamla primära till synkroniseringsbar tillstånd från den nya primära.
- En metod för att göra on-demand/planerade övergångar
Ett flitigt använt verktyg som hanterar allt ovan är Repmgr. Vi kommer att beskriva den minimala installationen som möjliggör en framgångsrik övergång. Vi börjar med en fungerande PostgreSQL 10.4 primär som körs på FreeBSD 11.1, manuellt byggd och installerad, och repmgr 4.0 också manuellt byggd och installerad för denna version (10.4). Vi kommer att använda två värdar som heter fbsd (192.168.1.80) och fbsdclone (192.168.1.81) med identiska versioner av PostgreSQL och repmgr. På den primära (initialt fbsd , 192.168.1.80) ser vi till att följande PostgreSQL-parametrar är inställda:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Sedan skapar vi repmgr-användaren (som superanvändare) och databasen:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgroch ställ in värdbaserad åtkomstkontroll i pg_hba.conf genom att sätta följande rader överst:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustVi ser till att vi ställer in lösenordslös inloggning för användare repmgr i alla noder i klustret, i vårt fall fbsd och fbsdclone genom att ställa in authorized_keys i .ssh och sedan dela .ssh. Sedan skapar vi repmrg.conf på den primära som:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Sedan registrerar vi den primära:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredOch kontrollera statusen för klustret:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Vi arbetar nu på standby genom att ställa in repmgr.conf enligt följande:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Vi ser också till att datakatalogen som anges precis i raden ovan finns, är tom och har rätt behörigheter:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataVi måste nu klona till vårt nya standbyläge:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Och starta vänteläget:
example@sqldat.com:~ % pg_ctl -D data startVid det här laget bör replikeringen fungera som förväntat, verifiera detta genom att fråga pg_stat_replication (fbsd) och pg_stat_wal_receiver (fbsdclone). Nästa steg är att registrera standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerNu kan vi få status för klustret på antingen standby eller primär och verifiera att standby är registrerad:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Låt oss nu anta att vi vill utföra en schemalagd manuell övergång för att t.ex. att göra lite administrationsarbete på nod fbsd. På standbynoden kör vi följande kommando:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyOmställningen har genomförts framgångsrikt! Låt oss se vad klustershowen ger:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2De två servrarna har bytt roll! Repmgr tillhandahåller repmgrd-demon som tillhandahåller övervakning, automatisk failover, såväl som aviseringar/varningar. Genom att kombinera repmgrd med pgbouncer, är det möjligt att implementera automatisk uppdatering av anslutningsinformationen för databasen, vilket ger ett stängsel för den misslyckade primära (förhindrar den misslyckade noden från all användning av applikationen) samt ger minimal stilleståndstid för applikationen. I mer komplexa system är en annan idé att kombinera Keepalved med HAProxy ovanpå pgbouncer och repmgr, för att uppnå:
- lastbalansering (skalning)
- hög tillgänglighet
Observera att ClusterControl också hanterar failover av PostgreSQL-replikeringsinställningar och integrerar HAProxy och VirtualIP för att automatiskt omdirigera klientanslutningar till den arbetande mastern. Mer information finns i detta whitepaper om PostgreSQL Automation.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperSkalning
Från och med PostgreSQL 10 (och 11) finns det fortfarande inget sätt att ha multi-master replikering, åtminstone inte från kärnan i PostgreSQL. Detta innebär att endast den valda (skrivskyddade) aktiviteten kan skalas upp. Skalning i PostgreSQL uppnås genom att lägga till fler heta standbylägen, vilket ger fler resurser för skrivskyddad aktivitet. Med repmgr är det enkelt att lägga till nytt standbyläge som vi såg tidigare via standby clone och väntelägesregistrering kommandon. Standbylägen som läggs till (eller tas bort) måste göras kända för konfigurationen av lastbalanseraren. HAProxy, som nämnts ovan i hanteringsämnet, är en populär lastbalanserare för PostgreSQL. Vanligtvis är det kopplat till Keepalived som tillhandahåller virtuell IP via VRRP. En trevlig översikt över hur du använder HAProxy och Keepalived tillsammans med PostgreSQL finns i den här artikeln:PostgreSQL Load Balancing Using HAProxy &Keepalived.
Övervakning
En översikt över vad som ska övervakas i PostgreSQL finns i den här artikeln:Viktiga saker att övervaka i PostgreSQL - Analysera din arbetsbelastning. Det finns många verktyg som kan tillhandahålla system- och postgresql-övervakning via plugins. Vissa verktyg täcker området för att presentera grafiska diagram över historiska värden (munin), andra verktyg täcker området för att övervaka livedata och tillhandahålla livevarningar (nagios), medan vissa verktyg täcker båda områdena (zabbix). En lista över sådana verktyg för PostgreSQL finns här:https://wiki.postgresql.org/wiki/Monitoring. Ett populärt verktyg för offlineövervakning (loggfilsbaserad) är pgBadger. pgBadger är ett Perl-skript som fungerar genom att analysera PostgreSQL-loggen (som vanligtvis täcker en dags aktivitet), extrahera information, beräkna statistik och slutligen producera en snygg HTML-sida som presenterar resultaten. pgBadger är inte begränsande för inställningen log_line_prefix, den kan anpassas till ditt redan befintliga format. Till exempel om du har ställt in i din postgresql.conf något som:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'sedan kan kommandot pgbadger för att analysera loggfilen och producera resultaten se ut så här:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger tillhandahåller rapporter för:
- Översiktsstatistik (främst SQL-trafik)
- Anslutningar (per sekund, per databas/användare/värd)
- Sessioner (antal, sessionstider, per databas/användare/värd/applikation)
- Kontrollpunkter (buffertar, wal-filer, aktivitet)
- Användning av temporära filer
- Vakuum/analysera aktivitet (per tabell, tuplar/sidor borttagna)
- Lås
- Frågor (efter typ/databas/användare/värd/applikation, varaktighet per användare)
- Överst (Frågor:långsammast, tidskrävande, vanligare, normaliserat långsammast)
- Händelser (fel, varningar, dödsfall, etc.)
Skärmen som visar sessionerna ser ut så här:
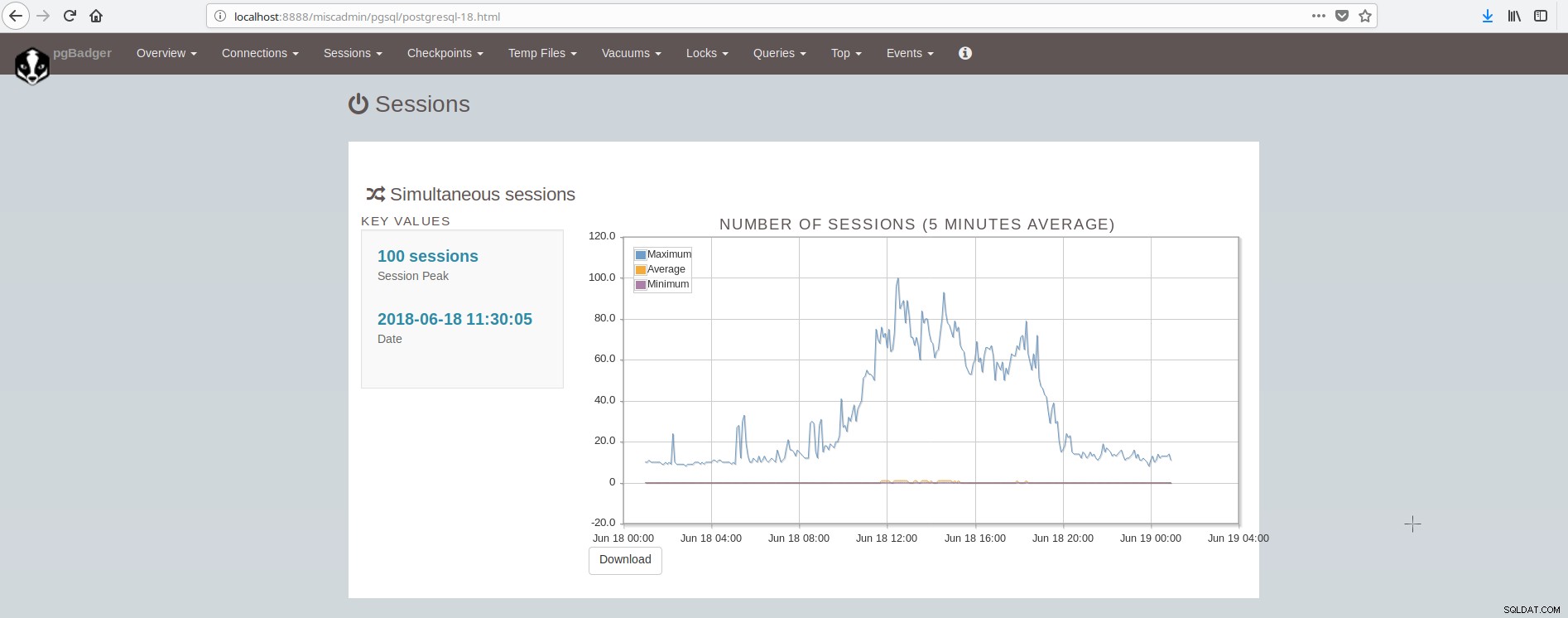
Som vi kan dra slutsatsen måste den genomsnittliga PostgreSQL-installationen integrera och ta hand om många verktyg för att ha en modern pålitlig och snabb infrastruktur och detta är ganska komplicerat att uppnå, såvida det inte finns stora team involverade i postgresql och systemadministration. En bra svit som gör allt ovan och mer är ClusterControl.