När det gäller grafiska exekveringsplaner finns det bara en ikon för en fysisk sortering i SQL Server:

Samma ikon används för de tre logiska sorteringsoperatorerna:Sortera, Topp N Sortera och Distinkt sortering:
Går man en nivå djupare, finns det fyra olika implementeringar av Sortera i exekveringsmotorn (batchsortering för optimerade slingkopplingar räknas inte med, vilket inte är en fullständig sortering och inte syns i planerna i alla fall). Om du använder SQL Server 2014 ökar antalet exekveringsmotorsorteringsimplementeringar till sju:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (endast SQL Server 2014)
- CQScanInMemSortNew
- In-Memory OLTP (Hekaton) inbyggt kompilerad procedur Top N Sort (endast SQL Server 2014)
- In-Memory OLTP (Hekaton) inbyggt kompilerad procedur General Sort (endast SQL Server 2014)
Den här artikeln tittar på dessa sorters implementeringar och när var och en används i SQL Server. Del ett täcker de fyra första punkterna på listan.
1. CQScanSortNew
Detta är den mest allmänna sorteringsklassen, som används när inget av de andra tillgängliga alternativen är tillämpliga. Allmän sortering använder ett arbetsutrymmesminne som reserverats precis innan exekveringen av frågan börjar. Detta bidrag är proportionellt mot kardinalitetsuppskattningar och genomsnittliga radstorleksförväntningar och kan inte ökas efter att sökfrågan börjar.
Den nuvarande implementeringen verkar använda en mängd olika interna sammanslagningssorteringar (kanske binär sammanslagningssortering), övergång till extern sammanslagningssortering (med flera pass om nödvändigt) om det reserverade minnet visar sig vara otillräckligt. Extern sammanfogningssortering använder fysisk tempdb utrymme för sorteringskörningar som inte får plats i minnet (vanligtvis känt som sorteringsspill). Allmän sortering kan också konfigureras för att tillämpa distinkthet under sorteringsoperationen.
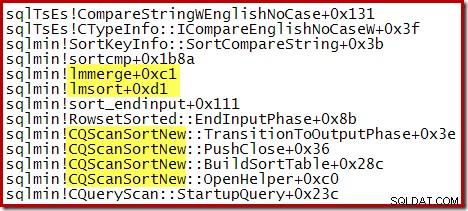
Följande partiella stackspårning visar ett exempel på CQScanSortNew klasssorteringssträngar med hjälp av en intern sammanfogad sortering:
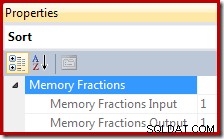
I exekveringsplaner tillhandahåller Sortera information om den del av den övergripande minnesbevilgningen för frågearbetsytan som är tillgänglig för sorteringen vid läsning av poster (inmatningsfasen) och den del som är tillgänglig när sorterad utdata förbrukas av överordnade planoperatörer (utgångsfasen). ).
Minnesbidragsfraktionen är ett tal mellan 0 och 1 (där 1 =100 % av det beviljade minnet) och är synligt i SSMS genom att markera Sortera och titta i fönstret Egenskaper. Exemplet nedan togs från en fråga med endast en enda sorteringsoperator, så den har hela frågearbetsutrymmesminnet tillgängligt under både inmatnings- och utmatningsfasen:
Minnesfraktionerna återspeglar det faktum att Sort under sin inmatningsfas måste dela det övergripande frågeminnesbeviljandet med samtidigt körande minneskrävande operatörer under den i exekveringsplanen. På samma sätt måste Sort under utmatningsfasen dela beviljat minne med samtidigt körande minneskrävande operatörer ovanför det i exekveringsplanen.
Frågeprocessorn är smart nog att veta att vissa operatörer blockerar (stop-and-go), vilket effektivt markerar gränser där minnesanslaget kan återvinnas och återanvändas. I parallella planer delas minnesandelen som är tillgänglig för en allmän sortering jämnt mellan trådar och kan inte balanseras om under körning i händelse av skevhet (en vanlig orsak till spill i parallella sorteringsplaner).
SQL Server 2012 och senare innehåller ytterligare information om minimibeviljande av arbetsutrymmesminne som krävs för att initiera minneskrävande planoperatörer och önskat minnesanslag (den "ideala" mängden minne som uppskattas behövas för att slutföra hela operationen i minnet). I en efterkörning ("faktisk") exekveringsplan finns det också ny information om eventuella förseningar i att erhålla minnesanslaget, den maximala mängden minne som faktiskt används och hur minnesreservationen fördelades över NUMA-noder.
Följande AdventureWorks-exempel använder alla en CQScanSortNew allmän sortering:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Den första frågan (en icke-distinkt sortering) producerar följande exekveringsplan:
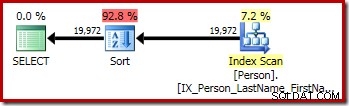
Den andra och tredje (motsvarande) frågan producerar denna plan:
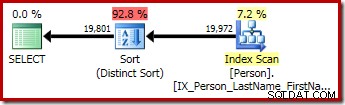
CQScanSortNew kan användas för både logisk allmän sortering och logisk distinkt sortering.
2. CQScanTopSortNew
CQScanTopSortNew är en underklass till CQScanSortNew används för att implementera en Top N Sortering (som namnet antyder). CQScanTopSortNew delegerar mycket av kärnarbetet till CQScanSortNew , men ändrar det detaljerade beteendet på olika sätt, beroende på värdet på N.
För N> 100, CQScanTopSortNew är i princip bara en vanlig CQScanSortNew sortering som automatiskt slutar producera sorterade rader efter N rader. För N <=100, CQScanTopSortNew behåller endast de nuvarande Top N-resultaten under sorteringsoperationen och håller reda på det lägsta nyckelvärdet som för närvarande kvalificerar sig.
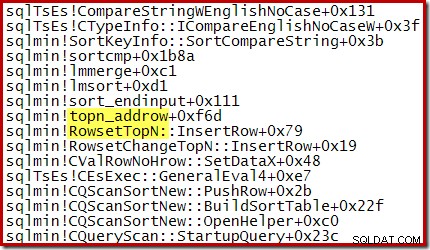
Till exempel, under en optimerad Top N Sortering (där N <=100) har samtalsstacken RowsetTopN medan vi med den allmänna sorteringen i avsnitt 1 såg RowsetSorted :
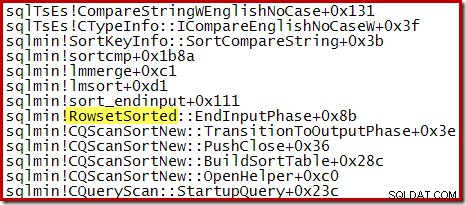
För en Top N-sortering där N> 100 är anropsstacken i samma exekveringsstadium densamma som den allmänna sorteringen som setts tidigare:
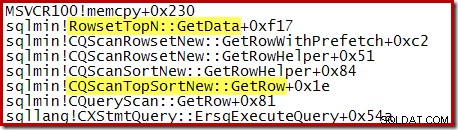
Lägg märke till att CQScanTopSortNew klassnamn visas inte i någon av dessa stackspår. Detta beror helt enkelt på hur underklassning fungerar. Vid andra tillfällen under körningen av dessa frågor, CQScanTopSortNew metoder (t.ex. Open, GetRow och CreateTopNTable) visas explicit på anropsstacken. Som ett exempel togs följande vid en senare tidpunkt i exekveringen av en fråga och visar CQScanTopSortNew klassnamn:
Topp N-sortering och frågeoptimeraren
Frågeoptimeraren vet ingenting om Top N Sort, som endast är en exekveringsmotoroperatör. När optimeraren producerar ett utdataträd med en fysisk Top-operator omedelbart ovanför en (icke distinkt) fysisk sortering, kan en omskrivning efter optimering kollapsa de två fysiska operationerna till en enda Top N Sort-operator. Även i fallet med N> 100, representerar detta en besparing över att passera rader iterativt mellan en sorteringsutgång och en toppingång.
Följande fråga använder ett par odokumenterade spårningsflaggor för att visa optimeringsutdata och omskrivningen efter optimering i aktion:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352);> Optimerarens utdataträd visar separata fysiska topp- och sorteringsoperatorer:
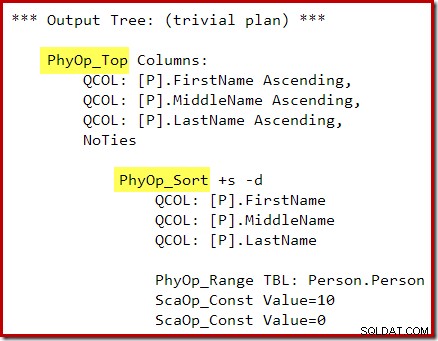
Efter omskrivningen efter optimeringen har Top och Sort komprimerats till en enda Top N Sortering:
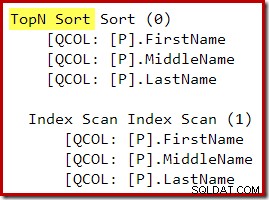
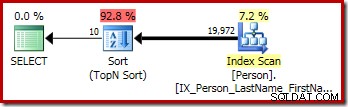
Den grafiska exekveringsplanen för T-SQL-frågan ovan visar den enda Top N Sort-operatorn:
Att bryta omskrivningen av Top N Sort
Omskrivningen av Top N Sorter efter optimering kan bara kollapsa en intilliggande Top och icke-särskild sortering till en Top N Sortering. Om du lägger till DISTINCT (eller motsvarande GROUP BY-sats) till frågan ovan förhindras omskrivningen av Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Den slutliga exekveringsplanen för den här frågan har separata top- och sorteringsoperatorer (Distinct Sort):
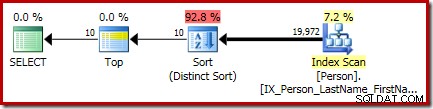
Sorteringen där är den allmänna CQScanSortNew klass som körs i distinkt läge som ses i avsnitt 1 tidigare.
Ett andra sätt att förhindra omskrivning till en Top N Sortering är att introducera en eller flera ytterligare operatorer mellan Top och Sort. Till exempel:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Frågeoptimerarens utdata råkar nu ha en operation mellan Top och Sort, så en Top N Sortering genereras inte under omskrivningsfasen efter optimering:
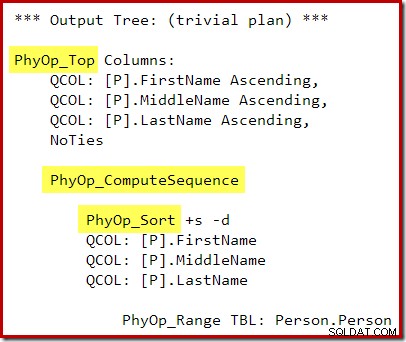
Utförandeplanen är:

Beräkningssekvensen (implementerad som två segment och ett sekvensprojekt) mellan toppen och sorteringen förhindrar kollapsen av topp- och sorteringsoperatorn till en enda top-n-sortering. Rätt resultat kommer naturligtvis fortfarande att erhållas från denna plan, men utförandet kan vara lite mindre effektivt än det kunde ha varit med den kombinerade Top N Sort-operatören.
3. CQScanIndexSortNew
CQScanIndexSortNew används endast för sortering i DDL-indexbyggnadsplaner. Den återanvänder några av de allmänna sorteringsfaciliteterna vi redan har sett, men lägger till specifika optimeringar för indexinfogningar. Det är också den enda sorteringsklassen som dynamiskt kan begära mer minne efter att exekveringen har börjat.
Kardinalitetsuppskattning är ofta korrekt för en indexbyggnadsplan eftersom det totala antalet rader i tabellen vanligtvis är en känd kvantitet. Därmed inte sagt att minnesbidrag för sortering av indexbyggnadsplaner alltid kommer att vara korrekta; det gör det bara lite mindre lätt att demo. Så följande exempel använder en odokumenterad, men någorlunda välkänd, tillägg till kommandot UPDATE STATISTICS för att lura optimeraren att tro att tabellen vi bygger ett index på bara har en rad:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Efterkörningsplanen (”faktisk”) för indexbygget visar ingen varning för en utspilld sortering (när den körs på SQL Server 2012 eller senare) trots 1-radsuppskattningen och de 19 972 raderna som faktiskt sorterades:
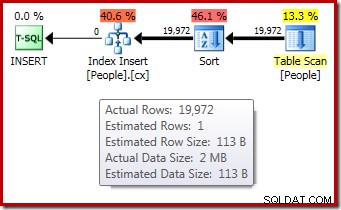
Bekräftelsen på att den initiala minnesbeviljanden utökades dynamiskt kommer från att titta på rotiteratorns egenskaper. Frågan tilldelades initialt 1024KB minne, men förbrukade slutligen 1576KB:
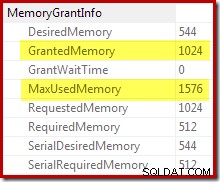
Den dynamiska ökningen av beviljat minne kan också spåras med hjälp av felsökningskanalen Extended Event sort_memory_grant_adjustment. Denna händelse genereras varje gång minnesallokeringen ökas dynamiskt. Om den här händelsen övervakas kan vi fånga en stackspårning när den publiceras, antingen via Extended Events (med lite besvärlig konfiguration och en spårningsflagga) eller från en ansluten debugger, enligt nedan:
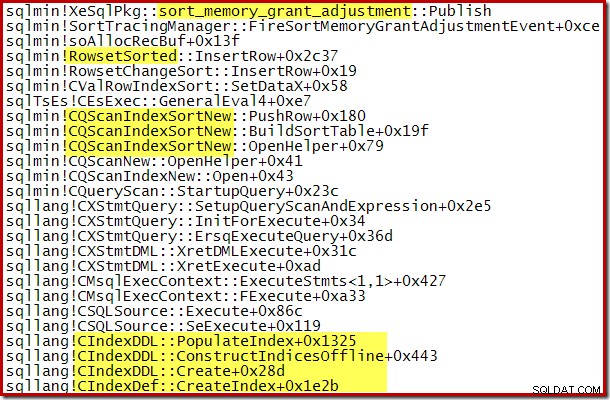
Dynamisk minnesutbyggnad kan också hjälpa till med parallella indexuppbyggnadsplaner där fördelningen av rader över trådar är ojämn. Mängden minne som kan konsumeras på detta sätt är dock inte obegränsad. SQL Server kontrollerar varje gång en expansion behövs för att se om begäran är rimlig med tanke på de resurser som finns tillgängliga vid den tidpunkten.
Viss insikt i denna process kan erhållas genom att aktivera odokumenterad spårningsflagga 1504, tillsammans med 3604 (för meddelandeutmatning till konsolen) eller 3605 (utdata till SQL Server-felloggen). Om indexbyggeplanen är parallell är endast 3605 effektiv eftersom parallella arbetare inte kan skicka spårningsmeddelanden över tråden till konsolen.
Följande sektion av spårningsutdata registrerades när ett måttligt stort index byggdes på en SQL Server 2014-instans med begränsat minne:
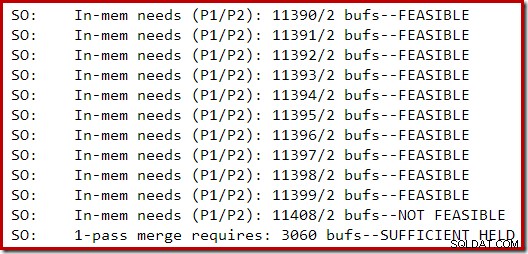
Minnesexpansion för sorteringen fortsatte tills begäran ansågs omöjlig, då det fastställdes att tillräckligt med minne redan fanns kvar för att ett engångssorteringsspill skulle slutföras.
4. CQScanPartitionSortNew
Det här klassnamnet kan antyda att den här typen av sortering används för partitionerade tabelldata, eller när man bygger index på partitionerade tabeller, men inget av dessa är faktiskt fallet. Sortering av partitionerad data använder CQScanSortNew eller CQScanTopSortNew som vanligt; sortering av rader för infogning i ett partitionerat index använder vanligtvis CQScanIndexSortNew som framgår av avsnitt 3.
CQScanPartitionSortNew sorteringsklassen finns bara i SQL Server 2014. Den används endast vid sortering av rader efter partitions-id, innan den infogas i ett partitionerat klustrat kolumnlagerindex . Observera att den endast används för partitionerad klustrad kolumnbutik; vanliga (icke-partitionerade) klustrade kolumnlagerinsättningsplaner tjänar inte på en sortering.
Infogar i ett partitionerat klustrat kolumnlagerindex kommer inte alltid att ha en sortering. Det är ett kostnadsbaserat beslut som beror på det uppskattade antalet rader som ska infogas. Om optimeraren uppskattar att det är värt att sortera inläggen efter partition för att optimera I/O, kommer kolumnarkivets infogningsoperator att ha DMLRequestSort egenskapen satt till true och en CQScanPartitionSortNew sortering kan förekomma i utförandeplanen.
Demon i det här avsnittet använder en permanent tabell med sekventiella nummer. Om du inte har en av dessa kan följande skript användas för att skapa ett:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Själva demon innebär att man skapar en partitionerad klustrad kolumnlagringsindexerad tabell och infogar tillräckligt många rader (från Numbers-tabellen ovan) för att övertyga optimeraren om att använda en partitionssortering före infogning:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Exekveringsplanen för infogningen visar sorteringen som används för att säkerställa att rader anländer till den klustrade kolumnlagerinfogningsiteratorn i partitions-id-ordning:

En anropsstack fångade medan CQScanPartitionSortNew sortering pågick visas nedan:
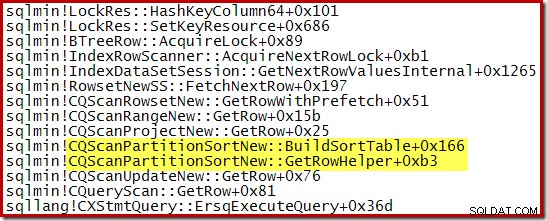
Det finns något annat intressant med den här sortens klass. Sorteringar förbrukar normalt hela sin input i deras Open method call. Efter sortering återför de kontrollen till sin moderoperatör. Senare börjar sorteringen producera sorterade utdatarader en i taget på vanligt sätt via GetRow-anrop. CQScanPartitionSortNew är annorlunda, som du kan se i anropsstacken ovan:Den förbrukar inte sin input under sin Open-metod – den väntar tills GetRow anropas av sin förälder för första gången.
Inte varje sortering på partitions-id som visas i en exekveringsplan som infogar rader i ett partitionerat klustrat kolumnlagerindex kommer att vara ett CQScanPartitionSortNew sortera. Om sorteringen visas omedelbart till höger om columnstore index insert operator, är chansen stor att det är en CQScanPartitionSortNew sortera.
Slutligen, CQScanPartitionSortNew är en av endast två sorteringsklasser som anger egenskapen Soft Sort exponerad när sorteringsoperatörens exekveringsplansegenskaper genereras med odokumenterad spårningsflagga 8666 aktiverad:
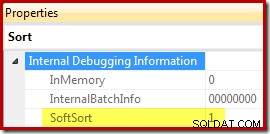
Innebörden av "mjuk sort" i detta sammanhang är oklar. Den spåras som en egenskap i frågeoptimerarens ramverk och verkar troligen vara relaterad till optimerade partitionerade datainlägg, men att bestämma exakt vad det betyder kräver ytterligare forskning. Under tiden kan den här egenskapen användas för att sluta sig till att en sortering är implementerad med CQScanPartitionSortNew utan att koppla en debugger. Innebörden av InMemory-egenskapsflaggan som visas ovan kommer att behandlas i del 2. Det gör den inte ange om en vanlig sortering utfördes i minnet eller inte.
Sammanfattning av del ett
- CQScanSortNew är den allmänna sorteringsklassen som används när inget annat alternativ är tillämpligt. Det verkar använda en mängd olika interna sammanslagningssorteringar i minnet, övergång till extern sammanslagningssortering med tempdb om beviljad minnesarbetsyta visar sig vara otillräcklig. Den här klassen kan användas för allmän sortering och distinkt sortering.
- CQScanTopSortNew redskap Top N Sort. Där N <=100, utförs en intern sammanfogningssortering i minnet och går aldrig till tempdb . Endast de nuvarande n översta objekten behålls i minnet under sorteringen. För N> 100 CQScanTopSortNew motsvarar en CQScanSortNew sortering som automatiskt stoppar efter att N rader har matats ut. En N> 100 sortering kan spilla till tempdb om det behövs.
- Den Top N Sorter som ses i exekveringsplaner är en omskrivning efter sökning efter optimering. Om frågeoptimeraren producerar ett utdataträd med en intilliggande topp och icke-distinkt sortering, kan denna omskrivning kollapsa de två fysiska operatorerna till en enda top n sorteringsoperator.
- CQScanIndexSortNew används endast i indexbyggande DDL-planer. Det är den enda standardsorteringsklassen som dynamiskt kan förvärva mer minne under exekvering. Indexbyggnadssorteringar kan fortfarande spilla ut till disken under vissa omständigheter, inklusive när SQL Server beslutar att en begärd minnesökning inte är kompatibel med den aktuella arbetsbelastningen.
- CQScanPartitionSortNew finns endast i SQL Server 2014 och används endast för att optimera inlägg till ett partitionerat klustrat kolumnlagerindex. Den ger en "mjuk sort".
Den andra delen av den här artikeln kommer att titta på CQScanInMemSortNew , och de två inbyggda OLTP-kompilerade lagrade procedurerna i minnet.