MySQL-databasens arbetsbelastning bestäms av antalet frågor som den bearbetar. Det finns flera situationer där MySQL-långsamhet kan uppstå. Den första möjligheten är om det finns några frågor som inte använder korrekt indexering. När en fråga inte kan använda ett index måste MySQL-servern använda mer resurser och tid för att bearbeta den frågan. Genom att övervaka frågor har du möjligheten att lokalisera SQL-kod som är grundorsaken till en avmattning och åtgärda den innan den övergripande prestandan försämras.
I det här blogginlägget kommer vi att lyfta fram Query Outlier-funktionen som är tillgänglig i ClusterControl och se hur den kan hjälpa oss att förbättra databasens prestanda. I allmänhet utför ClusterControl MySQL-frågesampling på två sätt:
- Hämta frågorna från prestationsschemat (rekommenderas ).
- Parseera innehållet i MySQL Slow Query.
Om prestandaschemat är inaktiverat kommer ClusterControl sedan att använda loggen för långsam fråge som standard. För att lära dig mer om hur ClusterControl utför detta, kolla in det här blogginlägget, Hur man använder ClusterControl Query Monitor för MySQL, MariaDB och Percona Server.
Vad är Query Outliers?
En outlier är en fråga som tar längre tid än den normala frågetiden av den typen. Ta inte detta bokstavligen som "dåligt skrivna" frågor. Det bör behandlas som potentiella suboptimala vanliga frågor som kan förbättras. Efter ett antal samplingar och när ClusterControl har haft tillräckligt med statistik, kan den avgöra om latensen är högre än normalt (2 sigmas + genomsnittlig_fråga_tid) då är det en extremvärde och kommer att läggas till i Query Outlier.
Denna funktion är beroende av funktionen Top Queries. Om Frågeövervakning är aktiverat och Top Queries fångas och fylls i, kommer Query Outliers att sammanfatta dessa och tillhandahålla ett filter baserat på tidsstämpel. För att se listan över frågor som kräver uppmärksamhet, gå till ClusterControl -> Query Monitor -> Query Outliers och bör se några frågor listade (om några):
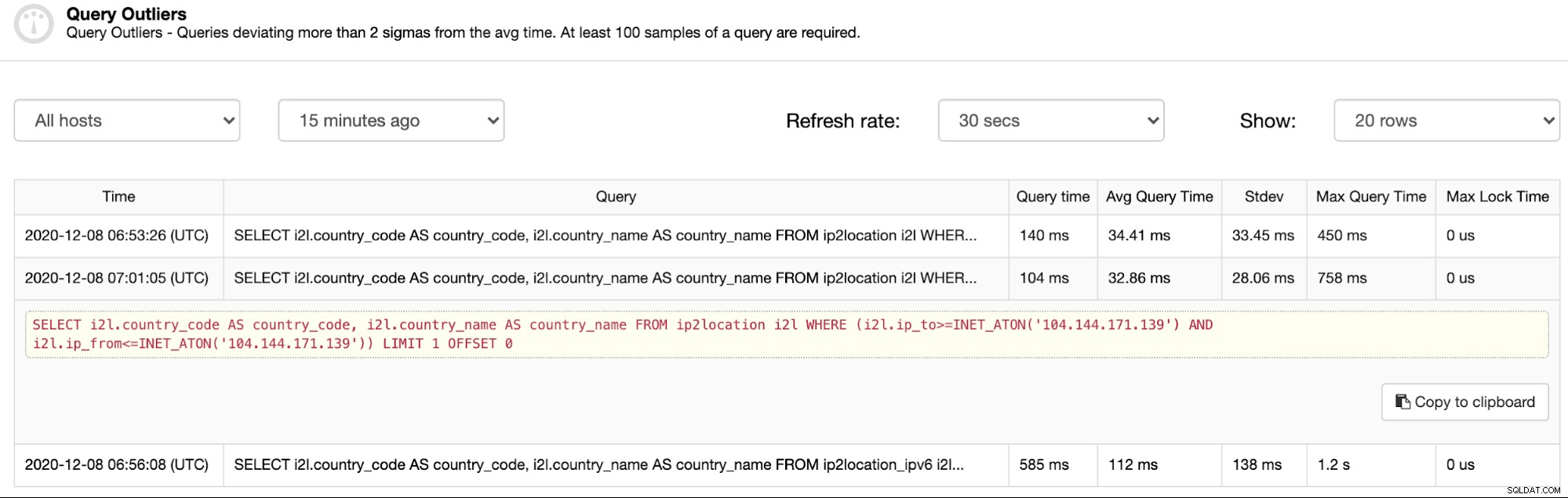
Som du kan se från skärmdumpen ovan är extremvärdena i grunden frågor som tog minst 2 gånger längre tid än den genomsnittliga frågetiden. Först den första posten, den genomsnittliga tiden är 34,41 ms medan avvikelsens frågetid är 140 ms (mer än 2 gånger högre än den genomsnittliga tiden). På samma sätt är kolumnerna Frågetid och Genomsnittlig frågetid för nästa poster två viktiga saker för att motivera uteståendena för en viss avvikande fråga.
Det är relativt lätt att hitta ett mönster av en speciell frågeavvikelse genom att titta på en större tidsperiod, som för en vecka sedan, vilket framhävs i följande skärmdump:
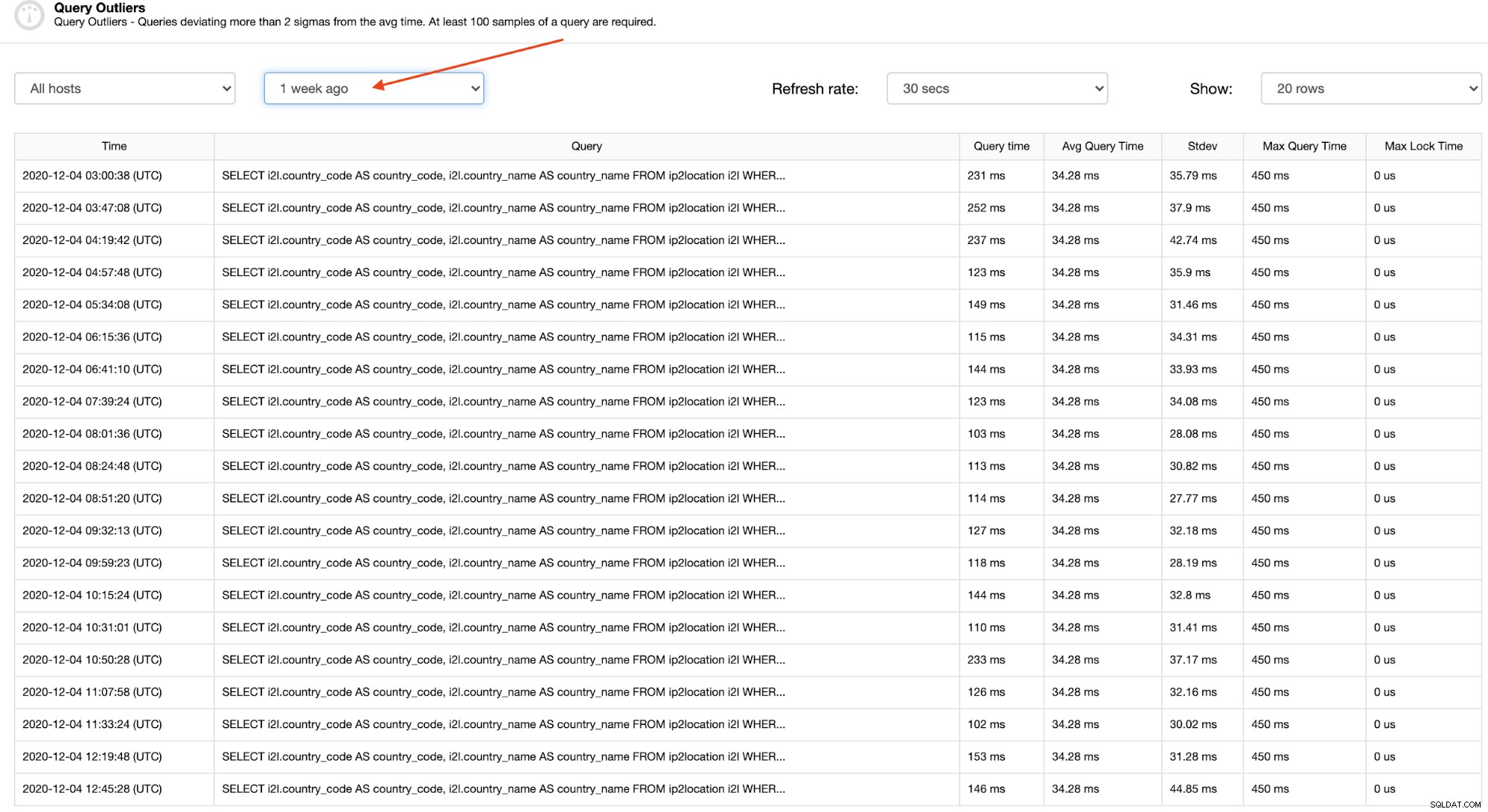
Genom att klicka på varje rad kan du se hela frågan som verkligen är till hjälp för att lokalisera och förstå problemet, som visas i nästa avsnitt.
Åtgärda frågeoutliers
För att åtgärda extremvärdena måste vi förstå frågans natur, tabellernas lagringsmotor, databasversionen, klustringstyp och hur effektfull frågan är. I vissa fall försämrar den extrema frågan inte riktigt den övergripande databasprestandan. Som i det här exemplet har vi sett att frågan har stuckit ut under hela veckan och att det var den enda frågetypen som registrerades så det är förmodligen en bra idé att fixa eller förbättra den här frågan om möjligt.
Precis som i vårt fall är den extrema frågan:
SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to >= INET_ATON('104.144.171.139')
AND i2l.ip_from <= INET_ATON('104.144.171.139'))
LIMIT 1
OFFSET 0;Och frågeresultatet är:
+--------------+---------------+
| country_code | country_name |
+--------------+---------------+
| US | United States |
+--------------+---------------+Använder EXPLAIN
Frågan är en skrivskyddad intervallvalsfråga för att fastställa användarens geografiska platsinformation (landskod och landsnamn) för en IP-adress i tabellen ip2location. Att använda EXPLAIN-satsen kan hjälpa oss att förstå frågeexekveringsplanen:
mysql> EXPLAIN SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to>=INET_ATON('104.144.171.139')
AND i2l.ip_from<=INET_ATON('104.144.171.139'))
LIMIT 1 OFFSET 0;
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | i2l | NULL | range | idx_ip_from,idx_ip_to,idx_ip_from_to | idx_ip_from | 5 | NULL | 66043 | 50.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+Frågan exekveras med en intervallsökning i tabellen med index idx_ip_from med 50 % potentiella rader (filtrerade).
Rätt lagringsmotor
Tittar på tabellstrukturen för ip2location:
mysql> SHOW CREATE TABLE ip2location\G
*************************** 1. row ***************************
Table: ip2location
Create Table: CREATE TABLE `ip2location` (
`ip_from` int(10) unsigned DEFAULT NULL,
`ip_to` int(10) unsigned DEFAULT NULL,
`country_code` char(2) COLLATE utf8_bin DEFAULT NULL,
`country_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
KEY `idx_ip_from` (`ip_from`),
KEY `idx_ip_to` (`ip_to`),
KEY `idx_ip_from_to` (`ip_from`,`ip_to`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binDen här tabellen är baserad på IP2location-databasen och den uppdateras/skrivs sällan, vanligtvis bara den första dagen i kalendermånaden (rekommenderas av leverantören). Så ett alternativ är att konvertera tabellen till MyISAM (MySQL) eller Aria (MariaDB) lagringsmotor med fast radformat för att få bättre skrivskyddad prestanda. Observera att detta endast är tillämpligt om du kör på MySQL eller MariaDB fristående eller replikering. På Galera Cluster and Group Replication, håll dig till InnoDB-lagringsmotorn (såvida du inte vet vad du gör).
Hur som helst, för att konvertera tabellen från InnoDB till MyISAM med fast radformat, kör helt enkelt följande kommando:
ALTER TABLE ip2location ENGINE=MyISAM ROW_FORMAT=FIXED;I vår mätning, med 1000 slumpmässiga IP-adressuppslagningstest, förbättrades frågeprestandan med cirka 20 % med MyISAM och fast radformat:
- Genomsnittlig tid (InnoDB):21,467823 ms
- Genomsnittlig tid (MyISAM Fixed):17,175942 ms
- Förbättring:19,992157565301 %
Du kan förvänta dig att detta resultat kommer omedelbart efter att tabellen har ändrats. Ingen modifiering på den högre nivån (applikation/lastbalanserare) är nödvändig.
Justera frågan
Ett annat sätt är att inspektera frågeplanen och använda ett mer effektivt tillvägagångssätt för en bättre utförandeplan för frågor. Samma fråga kan också skrivas med hjälp av subquery enligt nedan:
SELECT `country_code`, `country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');Den inställda frågan har följande exekveringsplan:
mysql> EXPLAIN SELECT `country_code`,`country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | ip2location | NULL | range | idx_ip_to | idx_ip_to | 5 | NULL | 66380 | 100.00 | Using index condition |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+Med hjälp av subquery kan vi optimera frågan genom att använda en härledd tabell som fokuserar på ett index. Frågan ska endast returnera en post där ip_to-värdet är större än eller lika med IP-adressvärdet. Detta gör att de potentiella raderna (filtrerade) kan nå 100 %, vilket är det mest effektiva. Kontrollera sedan att ip_from är mindre än eller lika med IP-adressvärdet. Om det är så borde vi hitta skivan. Annars finns inte IP-adressen i ip2location-tabellen.
I vår mätning förbättrades frågeprestandan med cirka 99 % med hjälp av en underfråga:
- Genomsnittlig tid (InnoDB + intervallsökning):22,87112 ms
- Genomsnittlig tid (InnoDB + underfråga):0,14744 ms
- Förbättring:99,355344207017 %
Med ovanstående optimering kan vi se en frågekörningstid på under millisekunder för denna typ av fråga, vilket är en enorm förbättring med tanke på att den tidigare genomsnittliga tiden är 22 ms. Vi måste dock göra några ändringar i den högre nivån (applikation/lastbalanserare) för att dra nytta av den här inställda frågan.
Lättning eller omskrivning av frågor
Patcha dina applikationer för att använda den inställda frågan eller skriv om avvikande frågan innan den når databasservern. Vi kan uppnå detta genom att använda en MySQL belastningsbalanserare som ProxySQL (frågeregler) eller MariaDB MaxScale (uttalande omskrivningsfilter), eller använda MySQL Query Rewriter-plugin. I följande exempel använder vi ProxySQL framför vårt databaskluster och vi kan helt enkelt skapa en regel för att skriva om den långsammare frågan till den snabbare, till exempel:
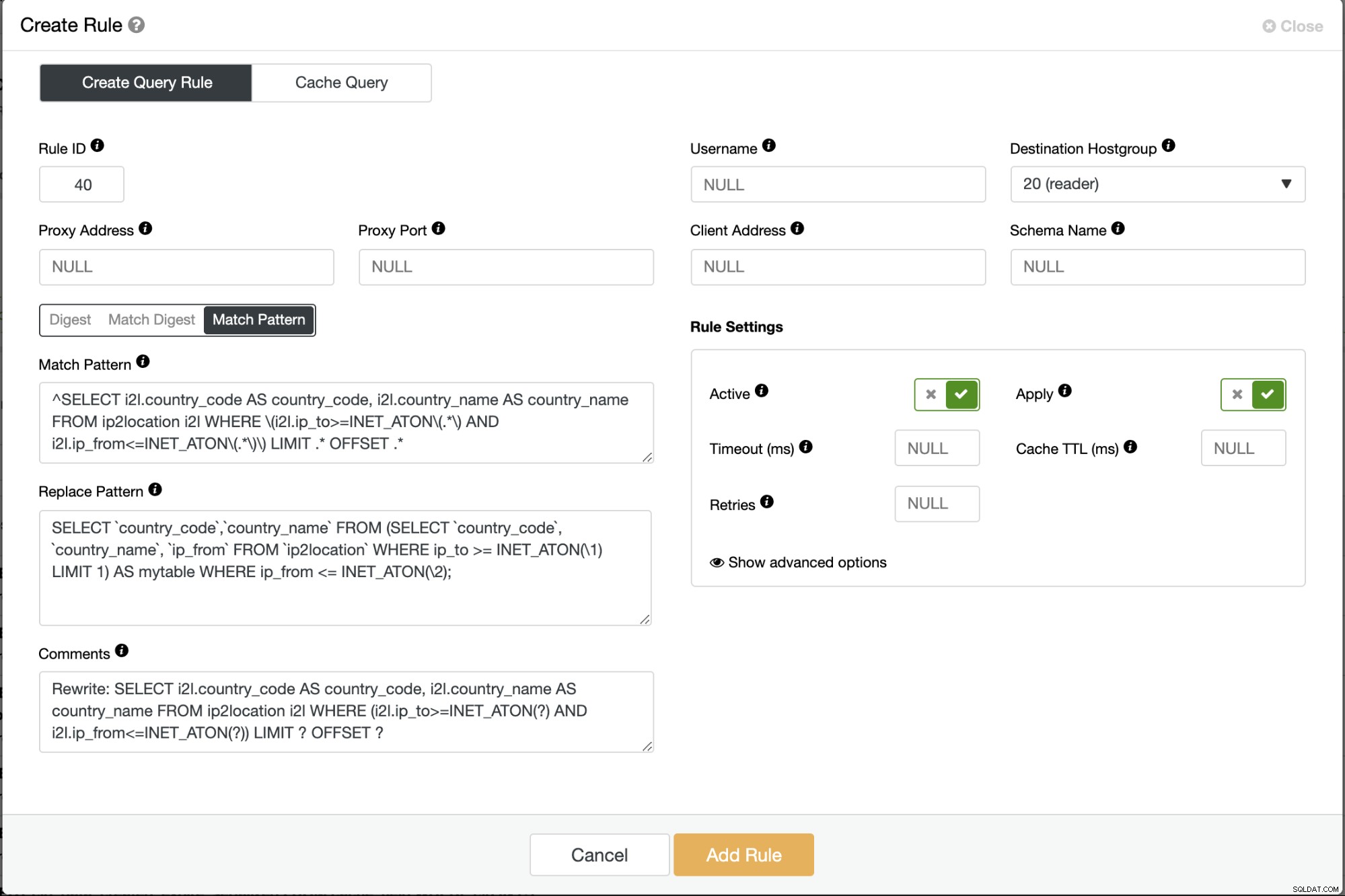
Spara frågeregeln och övervaka sidan Query Outliers i ClusterControl. Denna korrigering kommer uppenbarligen att ta bort avvikande frågor från listan efter att frågeregeln har aktiverats.
Slutsats
Frågeoutliers är ett proaktivt frågeövervakningsverktyg som kan hjälpa oss att förstå och åtgärda prestandaproblemet innan det blir långt utom kontroll. När din applikation växer och blir mer krävande kan det här verktyget hjälpa dig att upprätthålla en anständig databasprestanda under vägen.