Om du är ett Star Trek-fan vet du förmodligen att kapten Kirk och Mr Spock ofta spelar en variant av schack som kallas tredimensionell schack, eller 3D-schack, ett spel som liknar standardschack men med anmärkningsvärda skillnader. I den här artikeln bygger vi en datamodell för en 3D-schackapplikation som låter spelare tävla mot varandra. Stråla upp oss, Scotty!
Konceptet med 3D-schack
Även om schack i sig redan är ett komplext spel, kan en kombination av brädor och flera uppsättningar pjäser öka spelets komplexitet avsevärt.
I 3D-schack staplas brädor i parallella lager, och särskilda rörelseregler gäller för vissa pjäser, beroende på var de är placerade. Till exempel kan bönder på mittbrädet efterlikna beteendet hos en dam. Bitar kan också flyttas från en bräda till en annan, med vissa begränsningar tillämpade, och brädorna själva kan till och med flytta runt och rotera. Inte konstigt att Kirk och Spock tyckte så mycket om 3D-schack – det kräver ganska mycket taktisk finess!
Tredimensionellt schack avviker också från standardschack när det gäller egenskaperna hos dess brädor. I 3D-schack finns det sju distinkta brädor med olika egenskaper. Tre av dessa brädor är 4x4, medan de återstående fyra brädor är 2x2. Du kan flytta runt dessa mindre brädor.
Vår datamodell kommer förhoppningsvis att täcka allt vi behöver för att spela ett parti 3D-schack i en webbapp. Vi kommer att arbeta under antagandet att allt kan röra sig och att brädor kan införa olika rörelsebegränsningar på samma bitar. Detta bör vara tillräckligt för att täcka alla möjliga 3D schackvarianter. Låt oss hoppa direkt in i datamodellen!
Datamodellen
Vår datamodell består av tre sektioner:
- Spelare och spel
- Spelinställningar
- Träffar
Vi kommer nu att diskutera vart och ett av dessa områden mer i detalj.
Avsnitt 1:Spelare och spel
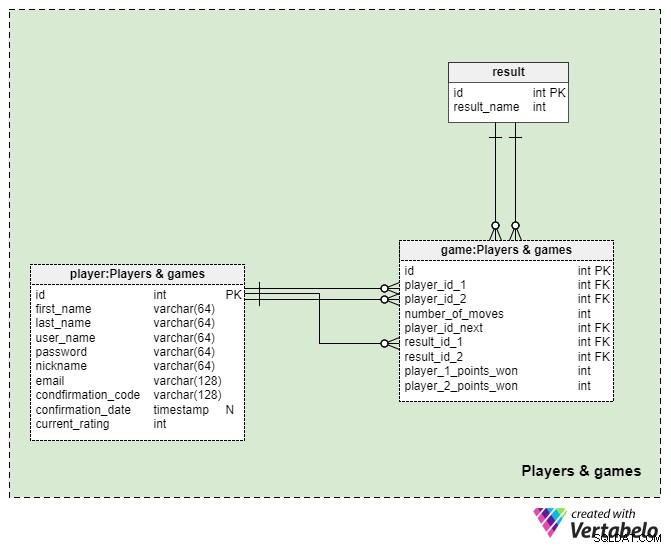
Allt i vår modell är antingen direkt eller indirekt relaterat till spel. Naturligtvis kan ett spel inte fortsätta utan spelare!
Listan över alla spelare lagras i player tabell. I vår modell är spelare alla registrerade användare av vår applikation. För varje spelare kommer vi att lagra följande information:
first_nameochlast_name– spelarens för- och efternamn.user_name– användarnamnet som spelaren valt, vilket måste vara unikt.password– ett hashvärde för spelarens lösenord.nickname– spelarens skärmnamn, som, liksom deras användarnamn, måste vara unikt.email– spelarens e-postadress, som de kommer att tillhandahålla under registreringsprocessen. Koden som krävs för att slutföra registreringsprocessen kommer att skickas till detta e-postmeddelande.confirmation_code– koden som skickades till spelarens e-postadress för att slutföra registreringsprocessen.confirmation_date– tidsstämpeln för när spelaren bekräftade sin e-postadress. Detta attribut kommer att lagra NULL tills spelaren bekräftar sin e-postadress.current_rating– spelarens nuvarande betyg, beräknat baserat på deras prestation mot andra spelare. Spelare kommer att börja med ett visst initialvärde och deras betyg kommer att öka eller minska beroende på motståndarnas rangordning och deras spelresultat.
result table är en ordbok som lagrar värdena för alla möjliga unika spelresultat, nämligen "in_progress", "draw", "win" och "lose".
Den kanske viktigaste tabellen i hela datamodellen är game , som lagrar information om varje parti 3D-schack. I den här modellen antar vi att två mänskliga spelare kommer att tävla mot varandra och att de kan välja att spara sitt nuvarande spelläge och återuppta vid ett senare tillfälle (som om de skulle vilja göra ett drag per dag, i vilket fall spelarna kommer att logga in på appen, se motståndarens senaste drag, tänka på sitt eget drag, utföra sitt drag och sedan logga ut). Vi lagrar följande värden i den här tabellen:
player_id_1ochplayer_id_2– referenser tillplayertabell som anger båda deltagarna i ett spel. Som nämnts antar vi att ett spel strikt kommer att ske mellan två mänskliga spelare.number_of_moves– anger antalet drag som har utförts hittills i det aktuella spelet. När spelet startar sätts detta nummer till 0 och ökar med 1 varje gång en spelare gör ett drag.player_id_next– en referens till spelaren som måste göra nästa drag i det aktuella spelet.result_id_1ochresult_id_2– referenser tillresulttabell som lagrar resultatet av spelet för varje spelare.player_1_points_wonochplayer_2_points_won– ange antalet poäng som spelarna fick, i enlighet med resultatet av spelet.
Vi kommer att diskutera hur spelare kan hålla reda på alla drag i avsnittet Matcher nära slutet av den här artikeln. För nu går vi vidare till spelinställningarna.
Avsnitt 2:Spelinställningar
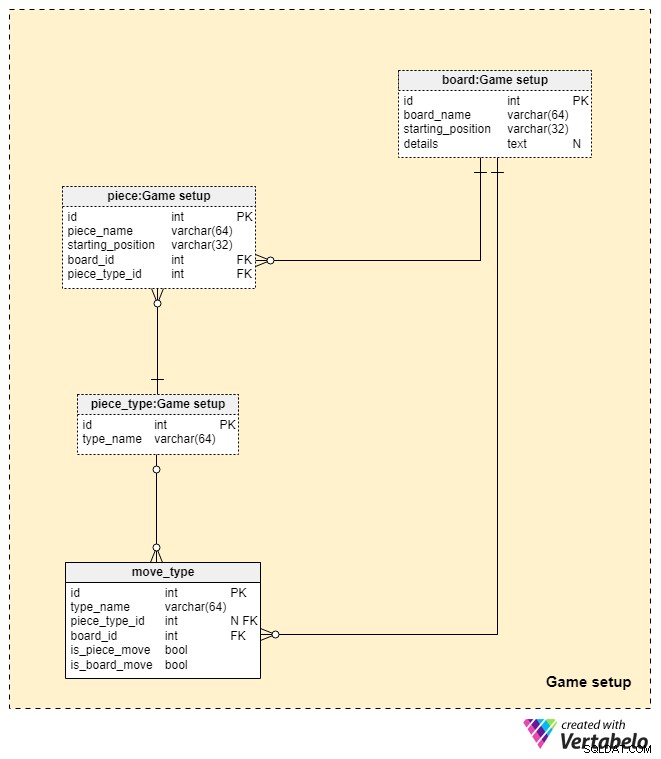
Spelinställningssektionen innehåller en beskrivning av alla brädor och pjäser i 3D-schack, samt en lista över alla lagliga drag spelare kan göra.
Som vi nämnde tidigare involverar 3D-schack ofta mer än ett bräde. Dessa brädor kan hålla sig till standardmåtten 8x8 med fasta positioner, men det behöver inte vara fallet. Listan över alla kort lagras i board tabell. För varje bräda lagrar vi ett unikt board_name , starting_position av tavlan i förhållande till våra valda 3D-koordinater och alla ytterligare details .
Därefter kommer vi att definiera alla möjliga typer av pjäser som kan dyka upp på våra schackbräden. För att göra det använder vi piece_type lexikon. Utöver sin primärnyckel innehåller denna ordbok endast ett unikt värde, typnamn. För ett standardschackspel förväntar vi oss att se värdena "bonde", "rook", "riddare", "biskop", "kung" och "drottning" i denna ordbok.
Listan över alla enskilda pjäser som används i ett parti 3D-schack lagras i piece tabell. För varje del lagrar vi följande information:
piece_name– ett unikt namn som beskriver pjästypen och dess startposition.starting_position– ett värde som anger exakt den bräda och ruta som pjäsen är placerad på från början.board_id– en hänvisning till brädet där pjäsen ursprungligen är placerad.piece_type_id– en referens som anger styckets typ.
Slutligen kommer vi att använda move_type tabell för att lagra listan över alla möjliga drag pjäserna kan göra på våra brädor (liksom alla drag brädorna själva kan göra). Minns från inledningen att vissa brädor tillämpar särskilda rörelseregler på sina pjäser. För varje drag kommer vi att definiera följande:
type_name– ett namn som vi kommer att använda för att beteckna draget som gjordes, vilket inte kommer att vara ett unikt värde (t.ex. kan vi ha "panten flyttat 1 ruta framåt" så många gånger som behövs).piece_type_id– en hänvisning till typen av pjäs som flyttades. Om detta värde råkar vara NULL, gäller rörelsen en hel bräda och inte en viss bit.board_id– anger brädet på vilket detta drag kommer att ske (om en schackpjäs rör sig). Om själva brädan rör sig kommer detta värde naturligtvis att representera brädet som flyttas. Tillsammans med två tidigare attribut utgör detta den unika nyckeln för denna tabell.is_piece_moveochis_board_move– ange om ett drag gäller en schackpjäs eller ett bräde. Endast en av dessa flaggor kan vara inställd på sann för ett visst drag.
Eftersom det finns för många pjäsrörelser och rotationer att ta hänsyn till, kommer vi inte att lagra alla sådana möjligheter i vår databas. Istället kommer vi bara att lagra flyttnamnen och implementera den faktiska logiken i själva applikationen. Till exempel kommer vi att definiera att bönder antingen kan gå framåt en ruta, flytta fram två rutor från sin startposition, göra anspråk på pjäser diagonalt, flytta från ett bräde till ett annat och flytta som en dam på centralbordet. Så vi kommer att ha fem möjliga rörelsetyper definierade för bönder, beroende på brädet de är placerade på och deras nuvarande position.
Avsnitt 3:Matchningar
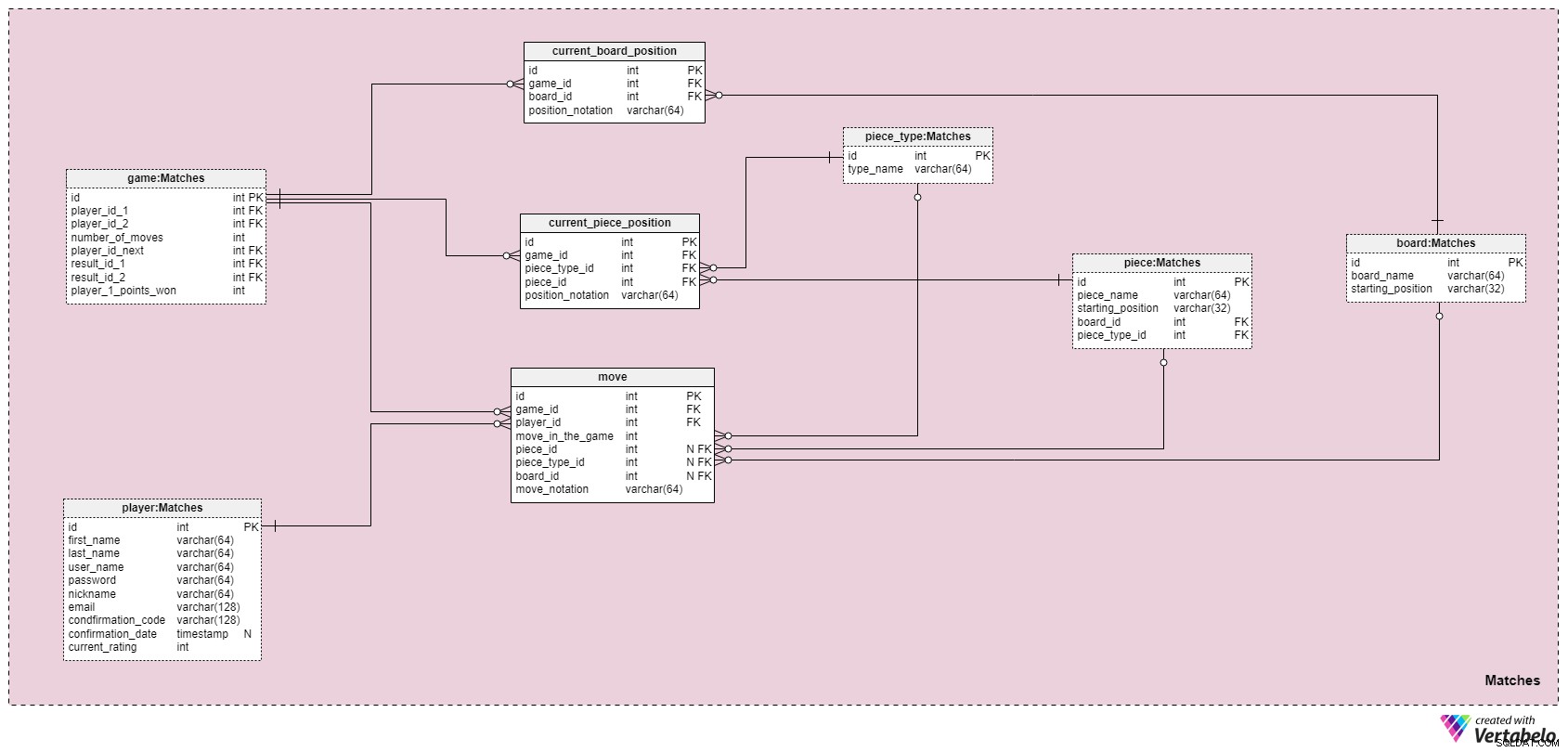
Vi är nästan klara! Den sista delen av vår modell heter Matcher och innehåller tre nya tabeller som vi kommer att använda för att hålla reda på rörelsehistoriken i ett parti 3D-schack. De återstående tabellerna är bara kopior av andra tabeller från vår datamodell, vilket hjälper till att undvika överlappande relationer. Vi kommer också att lagra de aktuella positionerna för alla brädor och deras pjäser i detta område. Låt oss dyka in direkt.
move tabellen är faktiskt den mest komplexa tabellen i det här avsnittet. Den innehåller listan över alla drag som utförs under ett spel. Den här tabellen visar listan över alla drag till spelare, som senare kan användas för att granska eller analysera matchen. För varje drag lagrar vi följande:
game_id– en referens tillgamedär flytten gjordes.player_id– en referens tillplayervem som gjorde flytten.move_in_the_game– ordningens ordningsnummer. Detta nummer, kombinerat med en pjäs startposition och alla andra drag, kan användas för att återskapa hela spelet. Tanken är att låta spelare simulera spelet när det är klart så att de kan analysera matchens resultat.piece_id– en referens tillpiecesom flyttades. Detta gör det enkelt att spåra ett styckes rörelse från början till slut (främst för analysändamål).piece_type_id– en hänvisning till typen av pjäs som flyttades. Även om en pjäs referens alltid kommer att förbli konstant, kan dess typ ändras under hela spelet (som om en bonde flyttas upp). Om vi flyttar tavlan kommer det här attributet att innehålla värdet NULL.board_id– en referens tillboardpå vilken flytten ägde rum.move_notation– en överenskommen notation som vi kommer att använda för att representera drag.
De återstående två tabellerna tillåter oss att lagra en ögonblicksbild av det aktuella spelläget i databasen, vilket är användbart om spelarna vill återuppta spelet vid ett senare tillfälle.
current_board_position används för att lagra positionen för alla brädor i vårt 3D-koordinatsystem. Detta är nödvändigt för 3D-schackspel där minst ett bräde kan ändra sin position. För varje post i den här tabellen kommer vi att lagra en referens till det relaterade spelet och brädet, samt notationen av en brädes position. Två specifika attributpar, game_id + board_id och game_id + position_notation , bildar de unika nycklarna för denna tabell.
Vår sista tabell är current_piece_position , som lagrar referenser till det relaterade spelet, en viss pjäs, pjäsens typ och en positionsbeteckning för pjäsen. Vi kommer återigen att ha två attributpar som fungerar som de unika nycklarna för denna tabell:game_id och piece_id paret och game_id och position_notation par.
Slutsats
Det är ungefär det för denna datamodell – vi är stolta över att kunna meddela att kapten Kirk och Mr. Spock nu kan spela 3D-schack på en dator!
Har du några förslag för att förbättra vår datamodell? Lämna gärna dina kommentarer nedan. Lev länge och blomstra ??