Kalkylark – Excel, Google Sheets eller ett ark med något annat namn – är riktigt coola och kraftfulla verktyg. Men det är databaserna också. När ska man hålla sig till ett kalkylblad? När ska du flytta upp till en databas?
Detta är fortsättningen på min tidigare artikel "Kalkylblad vs. Databaser:Är det dags att byta?" där vi har diskuterat de vanligaste nackdelarna med att använda kalkylblad för att organisera massor av data. I den här artikeln kommer vi att ta reda på hur en databas löser dessa problem.
Använda en databas för att organisera data
Mitt motto är "använd lämplig teknik för dina behov". Om du kan driva ditt företag via lakan, bra! Om du behöver en enkel databas är MS Access inte ett dåligt alternativ. Men om dessa produkter inte fungerar för dig behöver du förmodligen en anpassad databas och en webbapplikation. Databasen kommer att lagra dina data; webbappen kommer att vara ett användarvänligt sätt att interagera med databasen och kommunicera med datalagret.
Vår fiktiva tjänsteverksamhet var inte särskilt komplicerad, så vi kunde driva den med en ganska enkel datamodell. Om du tittar på bilden nedan ser du att allt vi behöver lagras i bara fem tabeller:client_type , client , service , replacement och has_service .
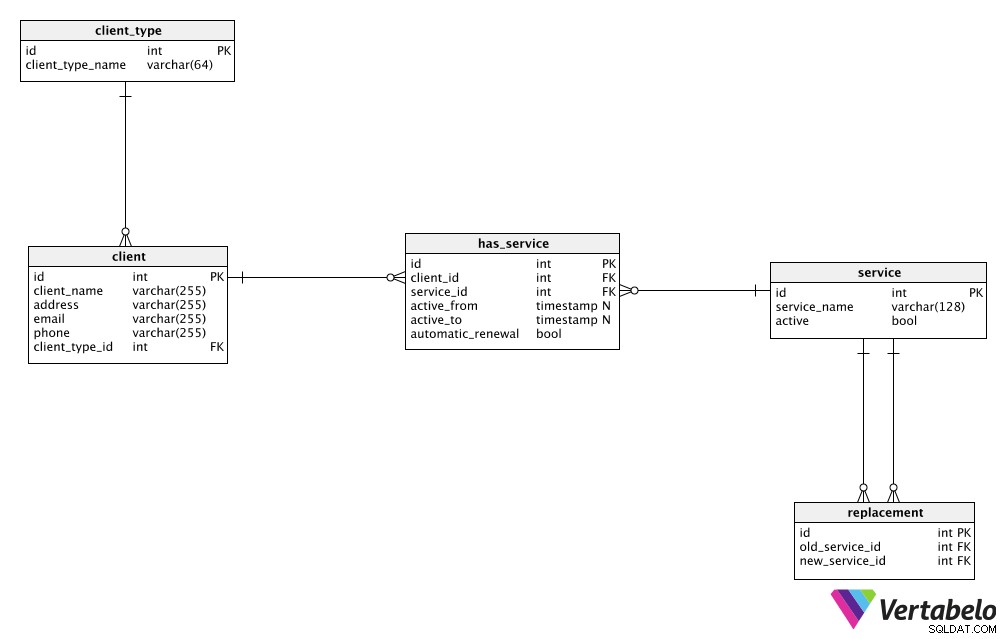
En nyckelregel för databasdesign är att förvara relaterade verkliga data på ett ställe . I det här fallet behåller vi alla våra client data i klienttabellen. På så sätt undviker vi att lagra samma data på flera platser (den dåliga typen av redundans som nämndes tidigare). Om vi ändrar något relaterat till en klient gör vi det bara en gång, i den här tabellen. Detta kommer att avsevärt förbättra datakvaliteten och vara bra för prestandan.
Nästa tabell som innehåller verkliga data är service tabell. Återigen kan vi lagra alla detaljer relaterade till våra tjänster här och vi kan göra ändringar i data ganska effektivt.
client tabellen och service tabellen är verkliga enheter som skulle kunna existera utan den andra. Men att skapa en databas med icke-relaterade enheter är inte så vettigt – det är som att ha kunder utan produkter eller tjänster utan köpare. Så vi kommer att relatera dessa två tabeller med hjälp av has_service tabell. För att lagra information om vilka klienter som har vilken tjänst, använder vi främmande nycklar som fungerar som referenser till den klienten och tjänsten. Dessa främmande nycklar pekar tillbaka till poster i tjänsten och klienttabellerna. Vi kan också behålla all ytterligare information relaterad till varje kund-tjänstrelation i den här tabellen.
client_type tabellen används som en ordbok som lagrar alla möjliga typer av klienter. Det är bäst att ha olika segmentering i separata ordbokstabeller (t.ex. om vi hade kundtyper och typer av anställdas roller, skulle vi lagra dem i olika tabeller). Vi behöver dock bara en tabell eftersom detta är en enkel modell.
Den sista tabellen i vår modell är replacement tabell. Vi kommer att använda den för att relatera två tjänster:en tjänst som vi vill ersätta och ersättningstjänsten. Detta ger oss flexibiliteten att erbjuda kunder ersättningar för befintliga tjänster (ungefär som att byta från en mobilsamtalsplan till en annan).
Databasfördelar
Databaser är mer komplicerade att sätta upp än kalkylblad, men detta ger dem faktiskt några betydande fördelar när det gäller dataintegritet och säkerhet:
Nycklar och begränsningar
Databaser har inbyggda regler och kontroller som, om de används på rätt sätt, förhindrar de flesta problem med datakvalitet och prestanda. Primära nycklar (kolumner som unikt identifierar varje post i en tabell) och främmande nycklar (kolumner som hänvisar till en post i en annan tabell) är avgörande för datasäkerhet, men definierar alternativa eller UNIKA nycklar (som innehåller data som är unika för varje post i en tabell ) är också till stor hjälp.
I relationsdatabaser relaterar nycklar data från olika tabeller. Tabellens primärnyckel är alltid UNIK, medan en främmande nyckel refererar till primärnyckeln från någon annan tabell. Den referensen relaterar data från dessa två tabeller (t.ex. främmande nycklar i has_service tabell relaterar kunddata till de tjänster de har). Det kommer också att varna oss om vi är på väg att ta bort en primärnyckel som refereras till i någon annan tabell. Detta kommer att hindra oss från att ta bort poster som fortfarande behövs (som referenser) i en annan tabell.
Begränsningar definierar vilken typ av data som kan matas in i ett fält. Vi kan specificera att data måste ha ett värde (NOT NULL), definiera ett format för telefonnummer, endast innehålla bokstäver och så vidare. Det betyder att vi kan undvika dataproblem från personer som anger fel typ av data i ett fält.
Säkerhet och behörigheter
En annan mycket viktig databasfunktion är att kontrollera åtkomsten till dina data . Detta ger dig möjligheten att inte bara ställa in vem som kan komma åt din databas utan också att kontrollera vad de kan se eller ändra. Detta är en stor del av datasäkerheten. Du kan till exempel definiera en användarroll som skulle tillåta en anställd att ändra kundinformation men inte serviceinformation. Du kan också sätta regler för vilka anställda som kan ändra eller radera data. Det är en bra praxis att se till att människor bara har tillgång till den data de behöver för att utföra sitt jobb.
Naturligtvis skulle vi kunna försöka återskapa dessa funktioner i ark (åtminstone på något sätt), men det skulle definitivt vara att "uppfinna hjulet på nytt".
Kunde vi inte bara använda ett kalkylblad?
Klart vi kunde. Vi skulle kunna skapa ark som följer samma mönster som används i datamodellen. Det skulle lösa många dataproblem, men...
Att replikera datamodellen i ark är definitivt inte ett idealiskt alternativ. Vi skulle förlora alla fördelar som databassystemet ger oss, alla regler och begränsningar som håller data "friska", alla saker som förhindrar oavsiktliga raderingar och andra fel. Vi skulle förlora på optimering och om datauppsättningen var tillräckligt stor skulle prestandan få en törn.
Även om vi löste det, hur är det med att dela data, t.ex. har flera användare som använder samma ark samtidigt? Vilka dataintegritets- och prestandaproblem skulle detta orsaka? Detta skulle vara motsatsen till att hålla saker och ting enkla.
Så om du tror att ark inte kan hantera dina affärsbehov är du förmodligen redan på väg mot en databas. Om du har fastnat med data lagrad i ark och du vill flytta till en databas bör du:
- Skapa en databasmodell som lagrar dina data optimalt.
- Bygg ett program med databasen i bakgrunden.
- Rensa dina data, omvandla dem (om det behövs) och importera dem till databasen.
- Fortsätt arbeta endast med databasen.
Vilket ska du välja – kalkylblad eller databas?
I dagens artikel har vi lärt oss hur en databas löser problem med att använda ark för att organisera massor av data. Mitt råd är gå alltid med den enklaste lösningen på ditt problem . Om kalkylblad kommer att göra jobbet ordentligt, använd dem. Men om du är ett datadrivet företag bör du börja använda en databas ASAP. Ju längre du väntar med att rensa och migrera dina data, desto mer smärtsam blir processen.