I den här artikeln kommer vi att undersöka operatorn "APPLY" och dess varianter - CROSS APPLY och OUTER APPLY tillsammans med exempel på hur de kan användas.
I synnerhet kommer vi att lära oss:
- skillnaden mellan CROSS APPLY och JOIN-satsen
- hur man sammanfogar utdata från SQL-frågor med tabellutvärderade funktioner
- hur man identifierar prestandaproblem genom att fråga efter dynamiska hanteringsvyer och dynamiska hanteringsfunktioner.
Vad är APPLY-klausulen
Microsoft introducerade APPLY-operatorn i SQL Server 2005. APPLY-operatorn liknar T-SQL JOIN-satsen eftersom den också låter dig sammanfoga två tabeller – till exempel kan du sammanfoga en yttre tabell med en inre tabell. Operatorn APPLY är ett bra alternativ när vi på ena sidan har ett tabellutvärderat uttryck som vi vill utvärdera för varje rad från tabellen vi har på den andra sidan. Så den högra tabellen bearbetas för varje rad i den vänstra tabellen. Den vänstra tabellen utvärderas först och sedan den högra tabellen utvärderas mot varje rad i den vänstra tabellen för att generera den slutliga resultatuppsättningen. Den slutliga resultatuppsättningen inkluderar alla kolumner från båda tabellerna.
Operatören APPLY har två varianter:
- KORSANSÖK
- YTTRE ANVÄND
KORSANSÖK
CROSS APPLY liknar INNER JOIN, men kan också användas för att sammanfoga tabellutvärderade funktioner med SQL-tabeller. CROSS APPLYs slutliga utdata består av poster som matchar utdata från en tabellutvärderad funktion och en SQL-tabell.
YTTRE ANVÄNDNING
OUTTER APPLY liknar LEFT JOIN, men har en förmåga att sammanfoga tabellutvärderade funktioner med SQL-tabeller. OUTER APPLYs slutgiltiga utdata innehåller alla poster från den vänstra tabellen eller den tabellutvärderade funktionen, även om de inte matchar posterna i den högra tabellen eller tabellvärderade funktionen.
Låt mig nu förklara båda varianterna med exempel.
Användningsexempel
Förbereder demoinstallationen
För att förbereda en demo-inställning måste du skapa tabeller med namnet "Anställda" och "Avdelning" i en databas som vi kallar "DemoDatabase". För att göra det, kör följande kod:
ANVÄND DEMODATABAS GÅ SKAPA TABELL [DBO].[ANSTÄLLDA] ( [ANSTÄLLDA NAMN] [VARCHAR](MAX) NULL, [FÖDELSEDATUM] [DATETIME] NULL, [ARBETSTITEL] [VARCHAR](150) NULL, [EMAILID] [ VARCHAR](100) NULL, [TELEFONNUMMER] [VARCHAR](20) NULL, [HIREDATE] [DATETIME] NULL, [DEPARTMENTID] [INT] NULL ) GÅ SKAPA TABELL [DBO].[AVDELNING] ( [DEPARTMENTID] INT IDENTITY (1, 1), [DEPARTMENTNAME] [VARCHAR](MAX) NULL ) GO
Lägg sedan in lite dummydata i båda tabellerna. Följande skript kommer att infoga data i "Anställd s ” tabell:
[expand title =”FULL FRÅGA "]
INFOGA [DBO].[ANSTÄLLDA] ([ANSTÄLLDARNAMN], [FÖDELSEDATUM], [ARBETSDATUM], [EMAILID], [TELEFONNUMMER], [ANHYRT], [AVDELNINGSID]) VÄRDEN (N'KEN J SÁNCHEZ', CAST (N'1969-01-29T00:00:00.000' AS DATETIME), N'CHIEF EXECUTIVE OFFICER', N'example@sqldat.com', N'697-555-0142', CAST(N'2009-01- 14T00:00:00.000' AS DATETIME), 1), (N'TERRI LEE DUFFY', CAST(N'1971-08-01T00:00:00.000' AS DATETIME), N'VICE PRESIDENT OF ENGINEERING', N'exempel @sqldat.com', N'819-555-0175', CAST(N'2008-01-31T00:00:00.000' AS DATETIME), NULL), (N'ROBERTO TAMBURELLO', CAST(N'1974-11) -12T00:00:00.000' AS DATETIME), N'ENGINEERING MANAGER', N'example@sqldat.com', N'212-555-0187', CAST(N'2007-11-11T00:00:00.000' AS DATETIME), NULL), (N'ROB WALTERS', CAST(N'1974-12-23T00:00:00.000' AS DATETIME), N' SENIOR TOOL DESIGNER', N'example@sqldat.com', N'612-555-0100', CAST(N'2007-12-05T00:00:00.000' AS DATETIME), NULL), (N'GAIL A ERICKSON ', CAST(N'1952-09-27T00:00:00.000' AS DATETIME), N'DESIGN ENGINEER', N'example@sqldat.com', N'849-555-0139', CAST(N'2008- 01-06T00:00:00.000' AS DATETIME), NULL), (N'JOSSEF H GOLDBERG', CAST(N'1959-03-11T00:00:00.000' AS DATETIME), N'DESIGN ENGINEER', N'example @sqldat.com', N'122-555-0189', CAST(N'2008-01-24T00:00:00.000' AS DATETIME), NULL), (N'DYLAN A MILLER', CAST(N'1987- 02-24T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT MANAGER', N'example@sqldat.com', N'181-555-0156', CAST(N'2009-02-08T00:00:00.000' AS DATETIME), 3), (N'DIANE L MARGHEIM', CAST(N'1986-06-05T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT ENGINEER', N'example@sqldat.com', N'815-555-0138', CAST(N'2008-12-29T00:00:00.000' AS DATETIME), 3), (N'GIGI N MATTHEW', CAST(N) '1979-01-21T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT ENGINEER', N'example@sqldat.com', N'185-555-0186', CAST(N'2009-01-16T00 :00:00.000' AS DATETIME), 3), (N'MICHAEL RAHEEM', CAST(N'1984-11-30T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT MANAGER', N'example@sqldat .com', N'330-555-2568', CAST(N'2009-05-03T00:00:00.000' AS DATETIME), 3)
[/expand]
För att lägga till data till vår "Avdelning ” tabell, kör följande skript:
INSERT [DBO].[AVDELNING] ([AVDELNINGSID], [AVDELNINGSNAMN]) VÄRDEN (1, N'IT'), (2, N'TECHNICAL'), (3, N'RESEARCH AND DEVELOPMENT')
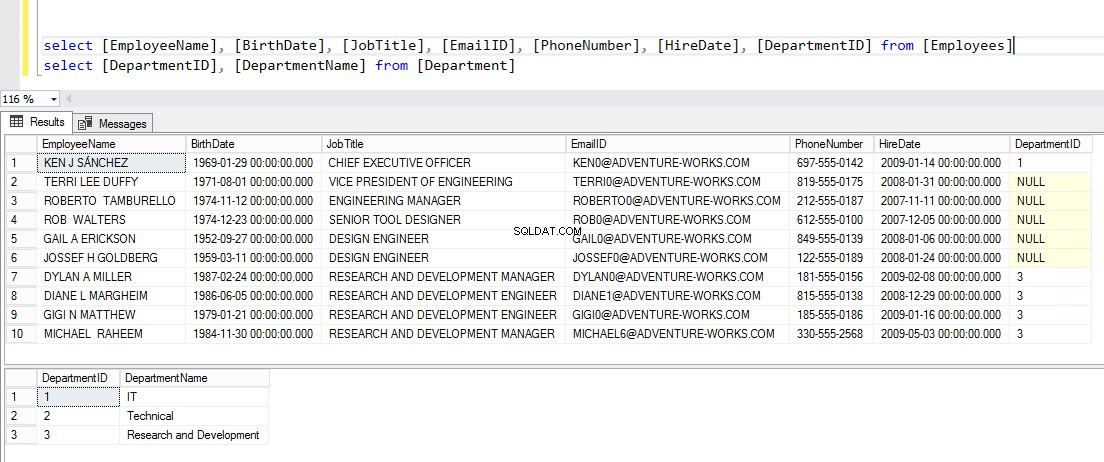
Nu, för att verifiera data, exekvera koden du kan se nedan:
VÄLJ [ANSTÄLLDA NAMN], [FÖDELSEDATUM], [ARBETSNAMN], [EMAILID], [TELEFONNUMMER], [ANHYRT], [AVDELNINGS-ID] FRÅN [ANSTÄLLDA] VÄLJ [AVDELNINGS-ID], [AVDELNINGSNAMN] FRÅN [AVDELNING] GÅHär är det önskade resultatet:
Skapa och testa en tabellutvärderad funktion
Som jag redan har nämnt, "ÖVERANSÖKNING ” och ”YTTRE APPLY ” används för att sammanfoga SQL-tabeller med tabellutvärderade funktioner. För att visa det, låt oss skapa en tabellutvärderad funktion med namnet "getEmployeeData .” Den här funktionen kommer att använda ett värde från DepartmentID kolumn som indataparameter och returnera alla anställda från korrespondentavdelningen.
För att skapa funktionen, kör följande skript:
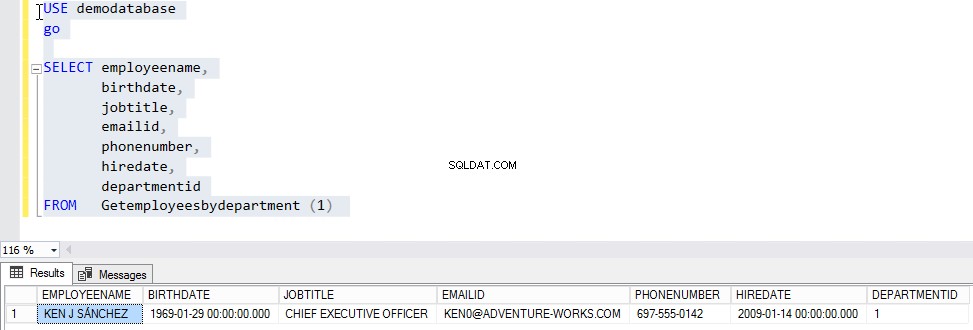
SKAPA FUNKTION Getemployeesbydepartment (@DEPARTMENTID INT) RETURER @EMPLOYEES TABELL ( ANSTÄLLDARNAMN VARCHAR (MAX), FÖDELSEDATUM DATETIME, JOBBTITEL VARCHAR(150), EMAILID VARCHAR(100), TELEFONDATUM 2DATUM 0ID0, VARCHARMENT0ID0 )) SOM BÖRJAN SÄTTA IN I @ANSTÄLLDA VÄLJ A.ANSTÄLLDA NAMN, A.FÖDELSEDATUM, A.ARBETSID, A.EMAILID, A.TELEFONNUMMER, A.HIREDATE, A.DEPARTMENTID FRÅN [ANSTÄLLDA] A WHERE A.DEPARTMENTID =@DEPARTMENTID RETURN ENDNu, för att testa funktionen, skickar vi "1 " som "avdelnings-ID " till "Getemployeesbydepartment " funktion. För att göra detta, kör skriptet nedan:
ANVÄND DEMODATABASEGOSELECT ANSTÄLLDANS NAMN, FÖDELSEDATUM, JOBBTITEL, E-POST-ID, TELEFONNUMMER, ARBETSDATUM, AVDELNINGIDFrån GETEMPLOYEESBYDEPARTMENT (1)Utdata ska vara som följer:
Gå med i en tabell med en tabellutvärderad funktion med CROSS APPLY
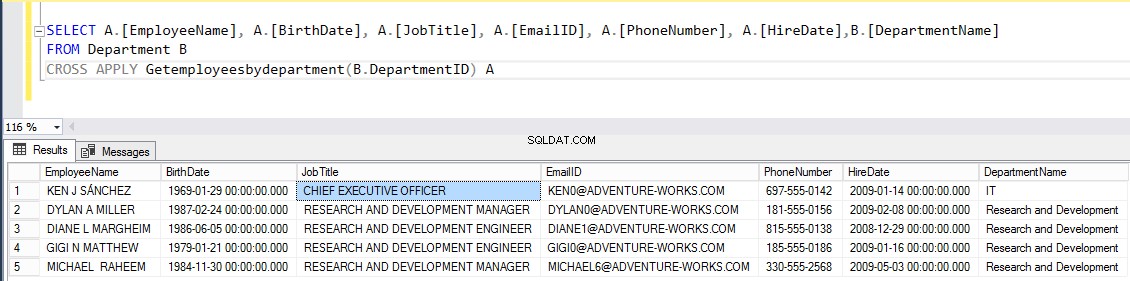
Nu ska vi försöka gå med i tabellen Anställda med "Getemployeesbydepartment ” tabellutvärderad funktion med CROSS APPLY . Som jag nämnde, KORSA TILLÄMPNING operatören liknar Join-klausulen. Den kommer att fylla i alla poster från "Anställd ” tabell för vilken det finns matchande rader i utdata från ”Getemployeesbydepartment ”.
Kör följande skript:
VÄLJ A.[ANSTÄLLNINGSNAMN], A.[FÖDELSEDATUM], A.[ARBETSDATUM], A.[EMAILID], A.[TELEFONNUMMER], A.[ANNAMN], B.[AVDELNINGSNAMN] FRÅN AVDELNING B KORS ANSÖK GETEMPLOYEESBYDEPARTMENT(B.DEPARTMENTID) AUtdata ska vara som följer:
Gå med i en tabell med en tabellutvärderad funktion med OUTTER APPLY
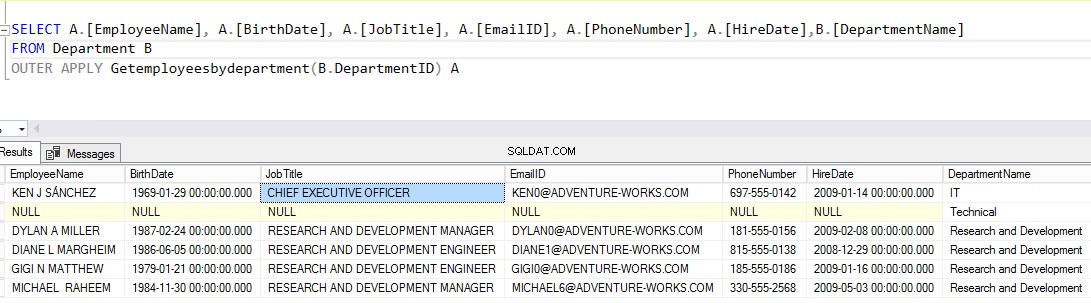
Låt oss nu försöka gå med i tabellen Anställda med "Getemployeesbydepartment ” tabellutvärderad funktion med OUTTER APPLY . Som jag nämnde tidigare, YTTRE GÄLLER operatorn liknar "OUTER JOIN ” klausul. Den fyller i alla poster från "Anställd ”-tabellen och utdata från “Getemployeesbydepartment ”-funktion.
Kör följande skript:
VÄLJ A.[ANSTÄLLNINGSNAMN], A.[FÖDELSEDATUM], A.[ARBETSDATUM], A.[EMAILID], A.[TELEFONNUMMER], A.[ANMÄLAN], B.[AVDELNINGSNAMN] FRÅN AVDELNING B YTTRE ANSÖK GETEMPLOYEESBYDEPARTMENT(B.DEPARTMENTID) AHär är resultatet du bör se som ett resultat:
Identifiera prestandaproblem genom att använda dynamiska hanteringsfunktioner och vyer
Låt mig visa dig ett annat exempel. Här kommer vi att se hur du får en frågeplan och motsvarande frågetext genom att använda dynamiska hanteringsfunktioner och dynamiska hanteringsvyer.
För demonstrationsändamål har jag skapat en tabell med namnet "SmokeTestResults " i "DemoDatabasen". Den innehåller resultat från ett applikationsröktest. Låt oss föreställa oss att en utvecklare av misstag kör en SQL-fråga för att fylla i data från "SmokeTestResults ” utan att lägga till ett filter, vilket avsevärt minskar databasens prestanda.
Som DBA måste vi identifiera den resurstunga frågan. För att göra detta använder vi "sys.dm_exec_requests "-vyn och "sys.dm_exec_sql_text ”-funktion.
"Sys.dm_exec_requests ” är en dynamisk hanteringsvy som ger följande viktiga detaljer som vi kan använda för att identifiera den resurskrävande frågan:
- Sessions-ID
- CPU-tid
- Väntetyp
- Databas-ID
- Läser (fysisk)
- Skriver (fysisk)
- Logiska läsningar
- SQL-handtag
- Planeringshandtag
- Frågestatus
- Kommando
- Transaktions-ID
"sys.dm_exec_sql_text ” är en dynamisk hanteringsfunktion som accepterar ett SQL-handtag som en indataparameter och ger följande detaljer:
- Databas-ID
- Objekt-ID
- Är krypterad
- SQL-frågetext
Låt oss nu köra följande fråga för att generera lite stress på ASAP-databasen. Kör följande fråga:
ANVÄND ASAP GO VÄLJ TSID, USERID, EXECUTIONID, EX_RESULTFILE, EX_TESTDATAFILE, EX_ZIPFILE, EX_STARTTIME, EX_ENDTIME, EX_REMARKS FRÅN [ASAP].[DBO].[SMOKETESTRESULTS]SQL Server tilldelar ett sessions-ID "66" och startar exekveringen av frågan. Se följande bild:
Nu, för att felsöka problemet, kräver vi Databas ID, Logical Reads, SQL Fråga, Kommando, Sessions-ID, Vänta typ och SQL-handtag . Som jag nämnde kan vi få Databas ID, Logical Reads, Command, Session ID, wait Type och SQL-handtag från "sys.dm_exec_requests." För att få SQL-frågan måste vi använda "sys.dm_exec_sql_text. " Det är en dynamisk hanteringsfunktion, så skulle behöva gå med i "sys.dm_exec_requests ” med “sys.dm_exec_sql_text ” genom att använda CROSS APPLY.
I fönstret Ny frågeredigerare kör du följande fråga:
VÄLJ B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS FRÅN SYS.DM_EXEC_REQUESTS A CROSS APPLY SYS.QL_EXEC_SYS.QL_EXEC_H /pre>Det bör producera följande utdata:
Som du kan se i skärmdumpen ovan returnerade frågan all information som krävs för att identifiera prestandaproblemet.
Nu vill vi, förutom frågetexten, få exekveringsplanen som användes för att exekvera frågan i fråga. För att göra detta använder vi "sys.dm_exec_query_plan" funktion.
"sys.dm_exec_query_plan ” är en dynamisk hanteringsfunktion som accepterar en planhantering som en indataparameter och ger följande detaljer:
- Databas-ID
- Objekt-ID
- Är krypterad
- SQL-frågeplan i XML-format
För att fylla i frågeexekveringsplanen måste vi använda CROSS APPLY för att gå med i "sys.dm_exec_requests ” och “sys.dm_exec_query_plan. ”
Öppna fönstret New Query editor och kör följande fråga:
VÄLJ B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS, C.QUERY_PLAN FRÅN SYS.DM_EXEC_REQUESTS A CROSS.L.DM_APP. SQL_HANDLE) B CROSS APPLY SYS.DM_EXEC_QUERY_PLAN (A.PLAN_HANDLE) CUtdata ska vara som följer:
Nu, som du kan se, genereras frågeplanen i XML-format som standard. För att öppna den som en grafisk representation, klicka på XML-utdata i query_plan kolumn som visas i bilden ovan. När du klickar på XML-utgången kommer exekveringsplanen att öppnas i ett nytt fönster som visas i följande bild:
Få en lista över tabeller med mycket fragmenterade index genom att använda dynamiska hanteringsvyer och funktioner
Låt oss se ytterligare ett exempel. Jag vill få en lista över tabeller med index som har 50 % eller mer fragmentering i en given databas. För att hämta dessa tabeller måste vi använda "sys.dm_db_index_physical_stats "-vyn och "sys.tables ”-funktion.
"Sys.tables ” är en dynamisk hanteringsvy som fyller i en lista med tabeller i den specifika databasen.
"sys.dm_db_index_physical_stats ” är en dynamisk hanteringsfunktion som accepterar följande inmatningsparametrar:
- Databas-ID
- Objekt-ID
- Index-ID
- Partitionsnummer
- Läge
Den returnerar detaljerad information om den fysiska statusen för det angivna indexet.
Nu, för att fylla i listan över fragmenterade index, måste vi gå med i "sys.dm_db_index_physical_stats ” och ”sys.tables ” med CROSS APPLY. Kör följande fråga:
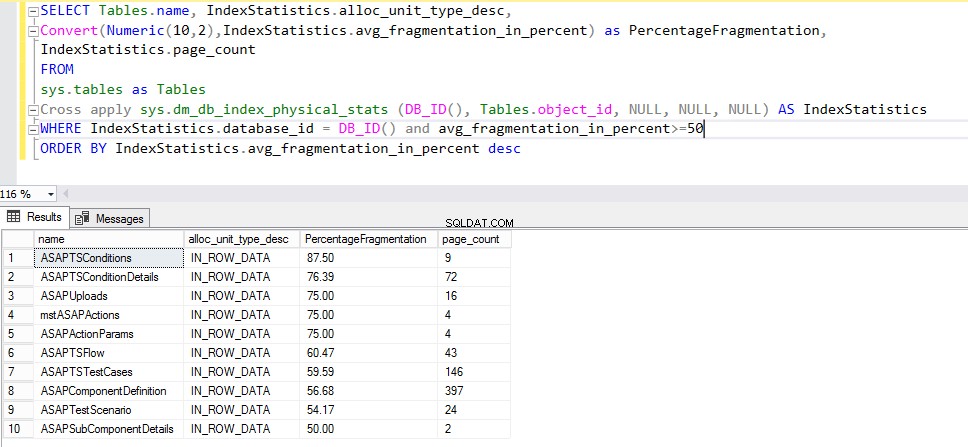
VÄLJ TABLES.NAME, INDEXSTATISTICS.ALLOC_UNIT_TYPE_DESC, CONVERT(NUMERIC(10, 2), INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT) SOM PERCENTAGEFRAGMENTATION, INDEXSTATISTICS.PAGE_COUNT SBROSS_ APPLYS_APPLY_SOBYSTA_ID, TJBROSS_APPLY_SOBYSTABYS.PH. , NULL, NULL, NULL) SOM INDEXSTATISTICS DÄR INDEXSTATISTICS.DATABASE_ID =DB_ID() OCH AVG_FRAGMENTATION_IN_PERCENT>=50 ORDNING EFTER INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT DESCENTFrågan bör ge följande utdata:
Sammanfattning
I den här artikeln behandlade vi APPLY-operatören, dess variationer – CROSS APPLY och OUTER APPLY och hur du fungerar. Vi har också sett hur du kan använda dem för att identifiera SQL-prestandaproblem med hjälp av dynamiska hanteringsvyer och dynamiska hanteringsfunktioner.