När du arbetar med ett projekt som består av många mikrotjänster, kommer det troligen också att innehålla flera databaser.
Till exempel kan du ha en MySQL-databas och en PostgreSQL-databas, båda körs på separata servrar.
Vanligtvis, för att sammanfoga data från de två databaserna, måste du introducera en ny mikrotjänst som skulle sammanfoga datan. Men detta skulle öka komplexiteten i systemet.
I den här handledningen kommer vi att använda Materialize för att gå med i MySQL och Postgres i en levande materialiserad vy. Vi kommer sedan att kunna fråga det direkt och få resultat tillbaka från båda databaserna i realtid med standard SQL.
Materialize är en källtillgänglig streamingdatabas skriven i Rust som behåller resultaten av en SQL-fråga (en materialiserad vy) i minnet när data ändras.
Handledningen innehåller ett demoprojekt som du kan börja använda docker-compose .
Demoprojektet som vi kommer att använda kommer att övervaka beställningarna på vår skenwebbplats. Det kommer att generera händelser som senare kan användas för att skicka meddelanden när en kundvagn har övergivits under en lång tid.
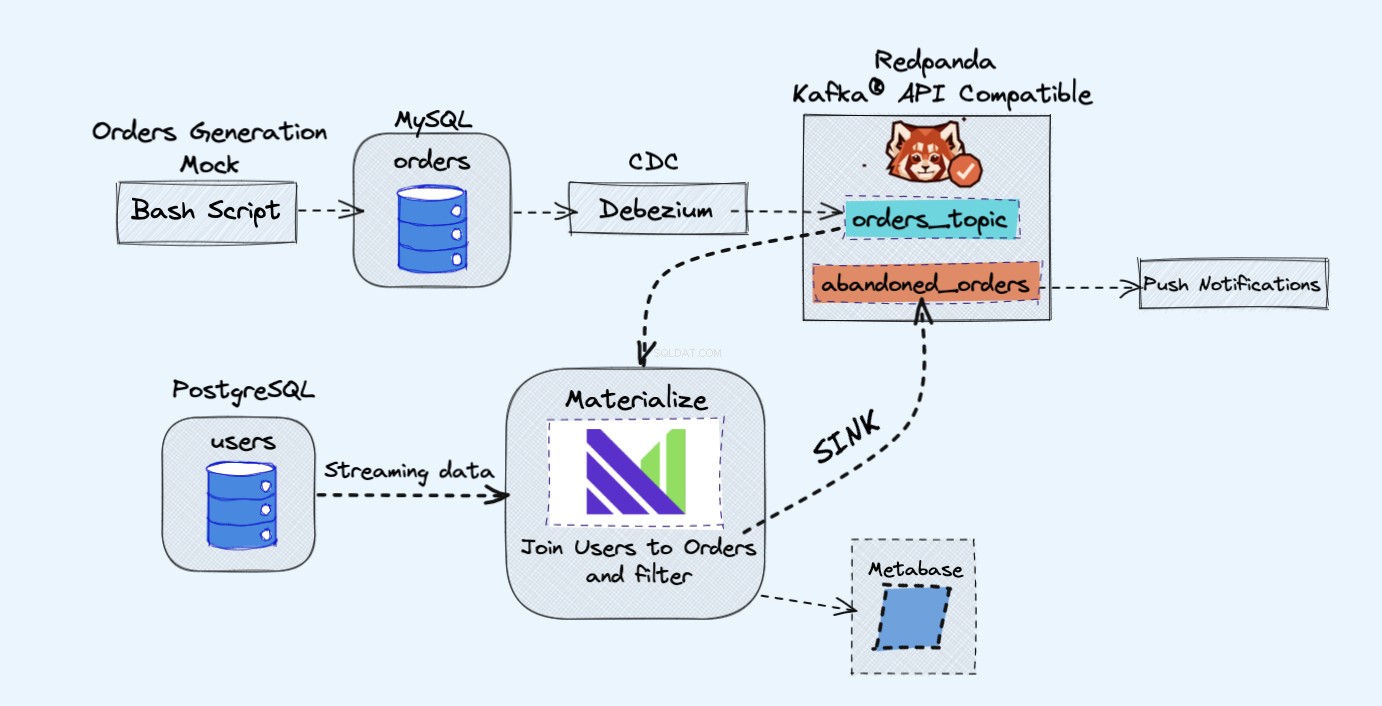
Arkitekturen för demoprojektet är som följer:
Förutsättningar
Alla tjänster som vi kommer att använda i demon kommer att köras i Docker-containrar, på så sätt behöver du inte installera några ytterligare tjänster på din bärbara dator eller server istället för Docker och Docker Compose.
Om du inte redan har Docker och Docker Compose installerade kan du följa de officiella instruktionerna om hur du gör det här:
- Installera Docker
- Installera Docker Compose
Översikt
Som visas i diagrammet ovan kommer vi att ha följande komponenter:
- En skentjänst för att kontinuerligt generera beställningar.
- Beställningarna kommer att lagras i en MySQL-databas .
- När databasen skriver inträffar Debezium strömmar ändringarna från MySQL till en Redpanda ämne.
- Vi kommer också att ha en Postgres databas där vi kan få våra användare.
- Vi lägger sedan in det här Redpanda-ämnet i Materialize direkt tillsammans med användarna från Postgres-databasen.
- I Materialize slår vi samman våra beställningar och användare, filtrerar och skapar en materialiserad vy som visar informationen om den övergivna kundvagnen.
- Vi skapar sedan en diskbänk för att skicka övergivna kundvagnsdata till ett nytt Redpanda-ämne.
- I slutet kommer vi att använda Metabas för att visualisera data.
- Du kan senare använda informationen från det nya ämnet för att skicka ut meddelanden till dina användare och påminna dem om att de har en övergiven kundvagn.
Som en sidoanteckning här, skulle du vara helt okej med Kafka istället för Redpanda. Jag gillar bara den enkelhet som Redpanda ger till bordet, eftersom du kan köra en enda Redpanda-instans istället för alla Kafka-komponenterna.
Hur man kör demon
Börja först med att klona förvaret:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Efter det kan du komma åt katalogen:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Låt oss börja med att först köra Redpanda-behållaren:
docker-compose up -d redpanda
Bygg bilderna:
docker-compose build
Slutligen, starta alla tjänster:
docker-compose up -d
För att starta Materialize CLI kan du köra följande kommando:
docker-compose run mzcli
Detta är bara en genväg till en Docker-behållare med postgres-client förinstallerad. Om du redan har psql du kan köra psql -U materialize -h localhost -p 6875 materialize istället.
Hur man skapar en materialiserad Kafka-källa
Nu när du är i Materialize CLI, låt oss definiera orders tabeller i mysql.shop databas som Redpanda-källor:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Om du skulle kontrollera de tillgängliga kolumnerna från orders källa genom att köra följande programsats:
SHOW COLUMNS FROM orders;
Du skulle kunna se att när Materialize hämtar meddelandeschemadata från Redpanda-registret, känner den till kolumntyperna som ska användas för varje attribut:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Hur man skapar materialiserade vyer
Därefter kommer vi att skapa vår första materialiserade vy för att få all data från orders Redpanda källa:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Du kan nu använda SELECT * FROM abandoned_orders; för att se resultaten:
SELECT * FROM abandoned_orders;
Mer information om hur du skapar materialiserade vyer finns i avsnittet Materialiserade vyer i Materialize-dokumentationen.
Hur man skapar en Postgres-källa
Det finns två sätt att skapa en Postgres-källa i Materialize:
- Använder Debezium precis som vi gjorde med MySQL-källan.
- Använda Postgres Materialize Source, som låter dig ansluta Materialize direkt till Postgres så att du inte behöver använda Debezium.
För den här demon kommer vi att använda Postgres Materialize-källan bara som en demonstration av hur man använder den, men använd gärna Debezium istället.
För att skapa en Postgres Materialize Source kör följande sats:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
En snabb sammanfattning av ovanstående uttalande:
MATERIALIZED:Materialiserar PostgreSQL-källans data. All data lagras i minnet och gör källor direkt valbara.mz_source:Namnet på PostgreSQL-källan.CONNECTION:PostgreSQL-anslutningsparametrarna.PUBLICATION:PostgreSQL-publikationen, som innehåller tabellerna som ska streamas till Materialize.
När vi väl har skapat PostgreSQL-källan, för att kunna fråga efter PostgreSQL-tabellerna, skulle vi behöva skapa vyer som representerar uppströmspublikationens ursprungliga tabeller.
I vårt fall har vi bara en tabell som heter users så uttalandet som vi skulle behöva köra är:
CREATE VIEWS FROM SOURCE mz_source (users);
För att se de tillgängliga vyerna, exekvera följande sats:
SHOW FULL VIEWS;
När det är gjort kan du fråga de nya vyerna direkt:
SELECT * FROM users;
Låt oss sedan gå vidare och skapa några fler vyer.
Hur man skapar en Kafka-vask
Sinks låter dig skicka data från Materialize till en extern källa.
För denna demo kommer vi att använda Redpanda.
Redpanda är Kafka API-kompatibel och Materialize kan bearbeta data från den precis som den skulle bearbeta data från en Kafka-källa.
Låt oss skapa en materialiserad vy som kommer att hålla alla obetalda beställningar med hög volym:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Som du kan se, här ansluter vi oss faktiskt till users vy som matar in data direkt från vår Postgres-källa och abandond_orders visa som samlar in data från Redpanda-ämnet tillsammans.
Låt oss skapa ett handfat där vi skickar data från ovanstående materialiserade vy:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Om du nu skulle ansluta till Redpanda-behållaren och använda rpk topic consume kommandot kommer du att kunna läsa poster från ämnet.
Men för närvarande kommer vi inte att kunna förhandsgranska resultaten med rpk eftersom den är AVRO-formaterad. Redpanda skulle sannolikt implementera detta i framtiden, men för tillfället kan vi faktiskt streama ämnet tillbaka till Materialize för att bekräfta formatet.
Få först namnet på ämnet som har genererats automatiskt:
SELECT topic FROM mz_kafka_sinks;
Utdata:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
För mer information om hur ämnesnamnen genereras, kolla in dokumentationen här.
Skapa sedan en ny materialiserad källa från detta Redpanda-ämne:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Se till att ändra ämnesnamnet i enlighet med detta!
Fråga slutligen denna nya materialiserade vy:
SELECT * FROM high_volume_orders_test LIMIT 2;
Nu när du har data i ämnet kan du låta andra tjänster ansluta till det och konsumera det och sedan utlösa e-postmeddelanden eller varningar till exempel.
Hur man ansluter Metabase
För att komma åt Metabase-instansen besök https://localhost:3030 om du kör demon lokalt eller https://your_server_ip:3030 om du kör demon på en server. Följ sedan stegen för att slutföra Metabase-installationen.
Se till att välja Materialisera som källa för data.
När du är klar kommer du att kunna visualisera dina data precis som du skulle göra med en vanlig PostgreSQL-databas.
Hur man stoppar demon
För att stoppa alla tjänster, kör följande kommando:
docker-compose down
Slutsats
Som du kan se är detta ett väldigt enkelt exempel på hur man använder Materialize. Du kan använda Materialize för att mata in data från en mängd olika källor och sedan streama den till en mängd olika destinationer.
Användbara resurser:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT