TimescaleDB är en öppen källkodsdatabas som uppfunnits för att göra SQL skalbar för tidsseriedata. Det är ett relativt nytt databassystem. TimescaleDB introducerades på marknaden för två år sedan och nådde version 1.0 i september 2018. Ändå är det konstruerat ovanpå ett moget RDBMS-system.
TimescaleDB är paketerat som en PostgreSQL-tillägg. All kod är licensierad under Apache-2-licensen med öppen källkod, med undantag för viss källkod relaterad till tidsserieföretagsfunktioner som licensieras under Timescale License (TSL).
Som en tidsseriedatabas ger den automatisk partitionering mellan datum och nyckelvärden. TimescaleDB inbyggt SQL-stöd gör det till ett bra alternativ för dem som planerar att lagra tidsseriedata och redan har gedigna SQL-språkkunskaper.
Om du letar efter en tidsseriedatabas som kan använda rik SQL, HA, en solid säkerhetskopieringslösning, replikering och andra företagsfunktioner, kan den här bloggen leda dig på rätt väg.
När ska TimescaleDB användas
Innan vi börjar med TimescaleDB-funktioner, låt oss se var det kan passa. TimescaleDB designades för att erbjuda det bästa av både relationell och NoSQL, med fokus på tidsserier. Men vad är tidsseriedata?
Tidsseriedata är kärnan i Internet of Things, övervakningssystem och många andra lösningar fokuserade på data som ofta förändras. Som namnet "tidsserier" antyder talar vi om data som förändras med tiden. Möjligheterna för en sådan typ av DBMS är oändliga. Du kan använda det i olika industriella IoT-användningsfall inom tillverkning, gruvdrift, olja och gas, detaljhandel, hälsovård, utvecklingsövervakning eller finansiell informationssektor. Det kan också i hög grad passa i pipelines för maskininlärning eller som en källa för affärsverksamhet och intelligens.
Det råder ingen tvekan om att efterfrågan på IoT och liknande lösningar kommer att växa. Med det sagt kan vi också förvänta oss behovet av att analysera och bearbeta data på många olika sätt. Tidsseriedata läggs vanligtvis bara till - det är ganska osannolikt att du kommer att uppdatera gamla data. Du tar vanligtvis inte bort vissa rader, å andra sidan kanske du vill ha någon form av aggregering av data över tiden. Vi vill inte bara lagra hur vår data förändras med tiden, utan också analysera och lära av den.
Problemet med nya typer av databassystem är att de vanligtvis använder sitt eget frågespråk. Det tar tid för användare att lära sig ett nytt språk. Den största skillnaden mellan TimescaleDB och andra populära tidsseriedatabaser är stödet för SQL. TimescaleDB stöder hela utbudet av SQL-funktioner inklusive tidsbaserade aggregat, kopplingar, underfrågor, fönsterfunktioner och sekundära index. Dessutom, om din applikation redan använder PostgreSQL, behövs inga ändringar av klientkoden.
Grundläggande arkitektur
TimescaleDB är implementerat som en förlängning på PostgreSQL, vilket innebär att en tidsskaladatabas körs inom en övergripande PostgreSQL-instans. Tilläggsmodellen gör att databasen kan dra nytta av många av PostgreSQL-attributen som tillförlitlighet, säkerhet och anslutning till ett brett utbud av tredjepartsverktyg. Samtidigt utnyttjar TimescaleDB den höga graden av anpassning som är tillgänglig för tillägg genom att lägga till krokar djupt i PostgreSQL:s frågeplanerare, datamodell och exekveringsmotor.
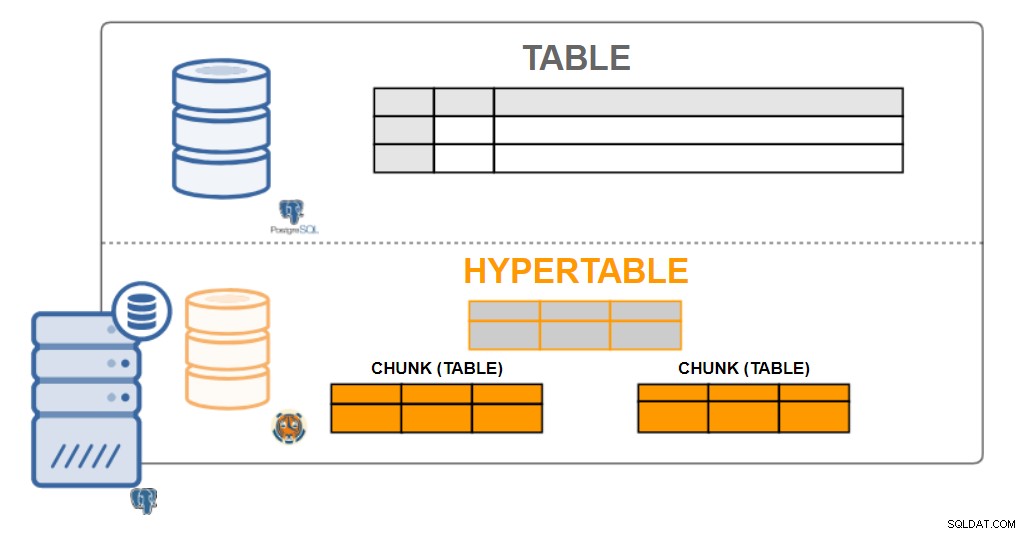 TimescaleDB-arkitektur
TimescaleDB-arkitektur Hypertabeller
Ur ett användarperspektiv ser TimescaleDB-data ut som singulära tabeller, kallade hypertabeller. Hypertabeller är ett koncept eller en implicit bild av många individuella tabeller som innehåller data som kallas chunks. Hypertabellens data kan vara antingen en eller två dimensioner. Det kan aggregeras med ett tidsintervall och med ett (valfritt) "partitionsnyckel"-värde.
Praktiskt taget all användarinteraktion med TimescaleDB är med hypertabeller. Att skapa tabeller, indexera, ändra tabeller, välja data, infoga data ... bör alla utföras på hypertabellen.
TimescaleDB utför denna omfattande partitionering både på singelnodsdistributioner såväl som klustrade distributioner (under utveckling). Även om partitionering traditionellt bara används för att skala ut över flera maskiner, tillåter det oss också att skala upp till höga skrivhastigheter (och förbättrade parallelliserade frågor) även på enstaka maskiner.
Stöd för relationsdata
Som en relationsdatabas har den fullt stöd för SQL. TimescaleDB stöder flexibla datamodeller som kan optimeras för olika användningsfall. Detta gör att Timescale skiljer sig något från de flesta andra tidsseriedatabaser. DBMS är optimerat för snabb inmatning och komplexa frågor, baserat på PostgreSQL och vid behov har vi tillgång till robust tidsseriebearbetning.
Installation
TimescaleDB på samma sätt som PostgreSQL stöder många olika sätt att installera, inklusive installation på Ubuntu, Debian, RHEL/Centos, Windows eller molnplattformar.
Ett av de mest bekväma sätten att spela med TimescaleDB är en dockningsbild.
Kommandot nedan kommer att hämta en Docker-avbild från Docker Hub om den inte redan har installerats och sedan köra den.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbFörsta användning
Eftersom vår instans är igång är det dags att skapa vår första timescaledb-databas. Som du kan se nedan ansluter vi via standard PostgreSQL-konsol så om du har PostgreSQL-klientverktyg (t.ex. psql) installerade lokalt kan du använda dem för att komma åt TimescaleDB docker-instansen.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Dag till dag drift
Ur perspektivet av både användning och hantering ser och känns TimescaleDB bara som PostgreSQL, och kan hanteras och frågas som sådan.
De viktigaste punkterna för den dagliga verksamheten är:
- Samsexisterar med andra TimescaleDBs och PostgreSQL-databaser på en PostgreSQL-server.
- Använder SQL som gränssnittsspråk.
- Använder vanliga PostgreSQL-anslutningar till tredjepartsverktyg för säkerhetskopiering, konsol etc.
TimescaleDB-inställningar
PostgreSQL:s out-of-the-box-inställningar är vanligtvis för konservativa för moderna servrar och TimescaleDB. Du bör se till att dina postgresql.conf-inställningar är inställda, antingen genom att använda timescaledb-tune eller göra det manuellt.
$ timescaledb-tuneSkriptet kommer att be dig bekräfta ändringarna. Dessa ändringar skrivs sedan till din postgresql.conf och kommer att träda i kraft vid omstarten.
Låt oss nu ta en titt på några grundläggande operationer från TimescaleDB-handledningen som kan ge dig en uppfattning om hur du arbetar med det nya databassystemet.
För att skapa en hypertabell börjar du med en vanlig SQL-tabell och konverterar den sedan till en hypertabell via funktionen create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Konvertera den till hypertabell är enkel som:
SELECT create_hypertable('conditions', 'time');Infoga data i hypertabellen görs med vanliga SQL-kommandon:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Att välja data är gammal bra SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Som vi kan se nedan kan vi göra en grupp efter, sortera efter och funktioner. Dessutom innehåller TimescaleDB funktioner för tidsserieanalys som inte finns i vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;