För några dagar sedan släpptes en ny version av ClusterControl, 1.7.2, där vi kan se flera nya funktioner, en av de viktigaste är stödet för TimescaleDB.
TimescaleDB är en tidsseriedatabas med öppen källkod optimerad för snabb inmatning och komplexa frågor som stöder fullständig SQL. Den är baserad på PostgreSQL och den erbjuder det bästa av NoSQL och relationsvärldar för tidsseriedata. TimescaleDB stöder strömmande replikering som den primära replikeringsmetoden, som kan användas i en högtillgänglighetsinställning. PostgreSQL kommer dock inte med automatisk failover och detta är ett problem i en produktionsmiljö med hög tillgänglighet. Manuell failover innebär vanligtvis att en människa söks och måste hitta en dator, logga in i systemen, förstå vad som pågår, innan den påbörjar failover-procedurer. Detta leder till en lång stilleståndsperiod. Lyckligtvis finns det ett sätt att automatisera failovers med ClusterControl, som nu stöder TimescaleDB.
I den här bloggen kommer vi att se hur man distribuerar en replikerad TimescaleDB-installation med automatisk failover på bara några få klick genom att använda ClusterControl. Vi kommer också att se hur man lägger till en enda databasslutpunkt för applikationer via HAProxy. Som en förutsättning bör du installera 1.7.2-versionen av ClusterControl på en dedikerad värd eller virtuell dator.
Distribuera TimescaleDB
För att utföra en ny installation av TimescaleDB från ClusterControl, välj helt enkelt alternativet "Deploy" och följ instruktionerna som visas. Observera att om du redan har en TimescaleDB-instans igång, måste du välja "Importera befintlig server/databas" istället.
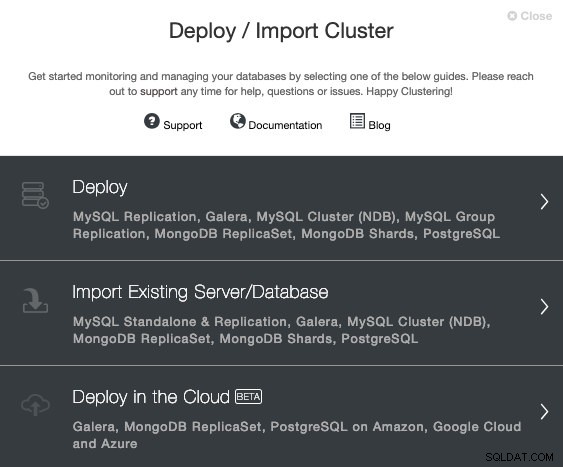
När vi väljer TimescaleDB måste vi ange Användare, Nyckel eller Lösenord och port för att ansluta med SSH till våra TimescaleDB-värdar. Vi behöver också ett namn för vårt nya kluster och om vi vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt oss.
Kontrollera användarkraven för ClusterControl för denna uppgift här.
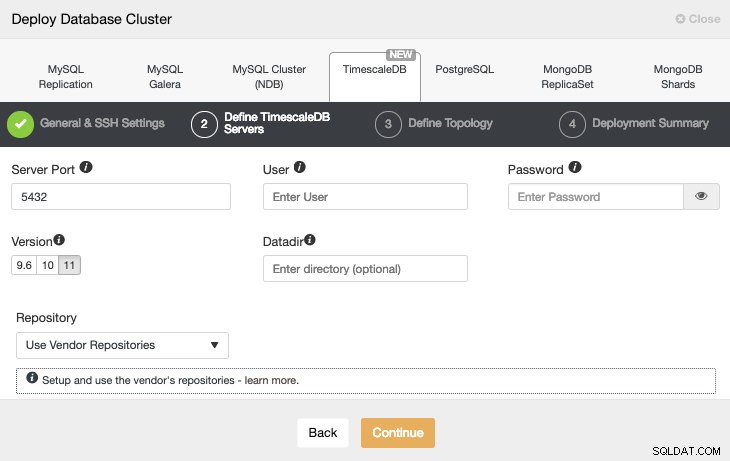
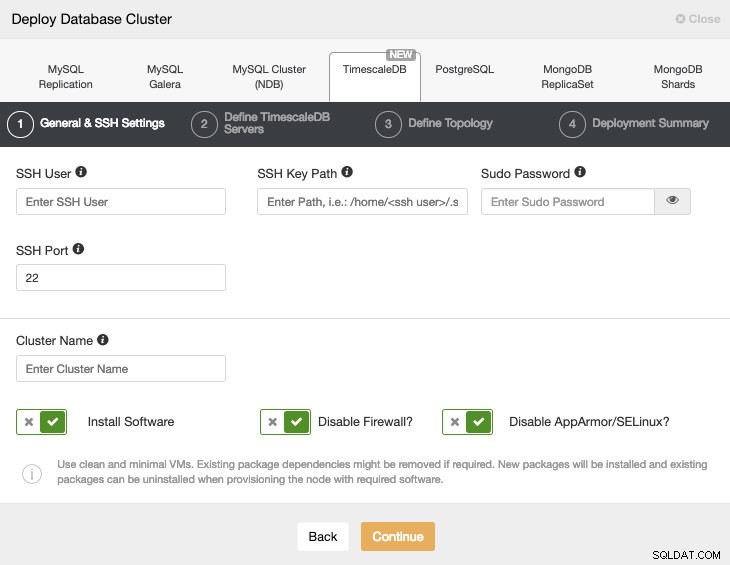
Efter att ha ställt in SSH-åtkomstinformationen måste vi definiera databasanvändare, version och datadir (valfritt). Vi kan också specificera vilket arkiv som ska användas.
I nästa steg måste vi lägga till våra servrar i klustret vi ska skapa.
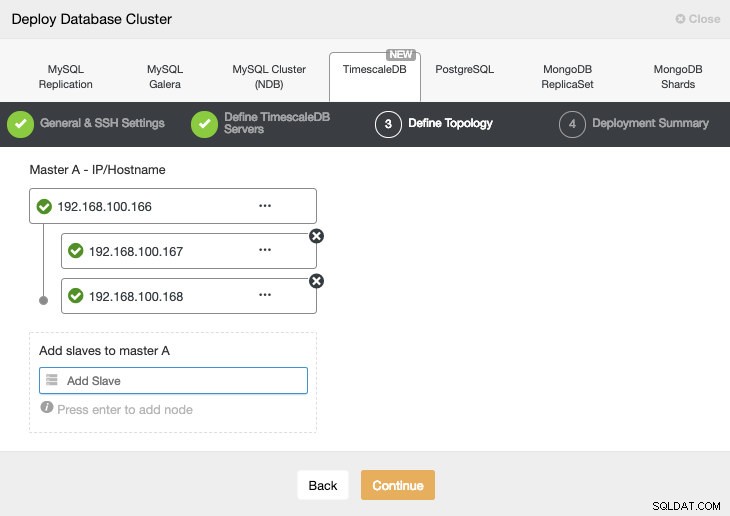
När vi lägger till våra servrar kan vi ange IP eller värdnamn.
I det sista steget kan vi välja om vår replikering ska vara Synchronous eller Asynchronous.
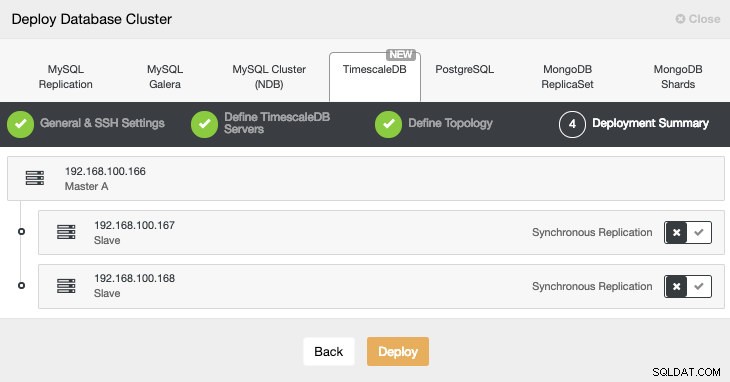
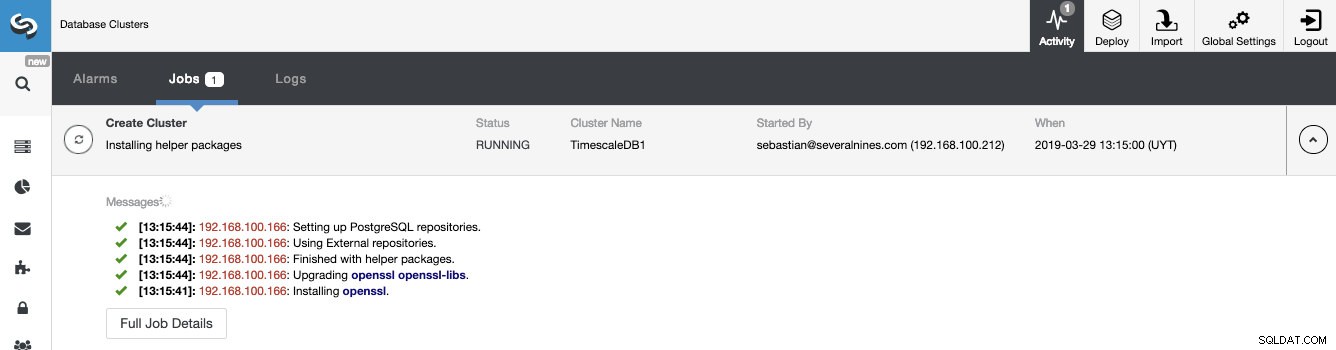
Vi kan övervaka statusen för skapandet av vårt nya kluster från ClusterControl-aktivitetsmonitorn.
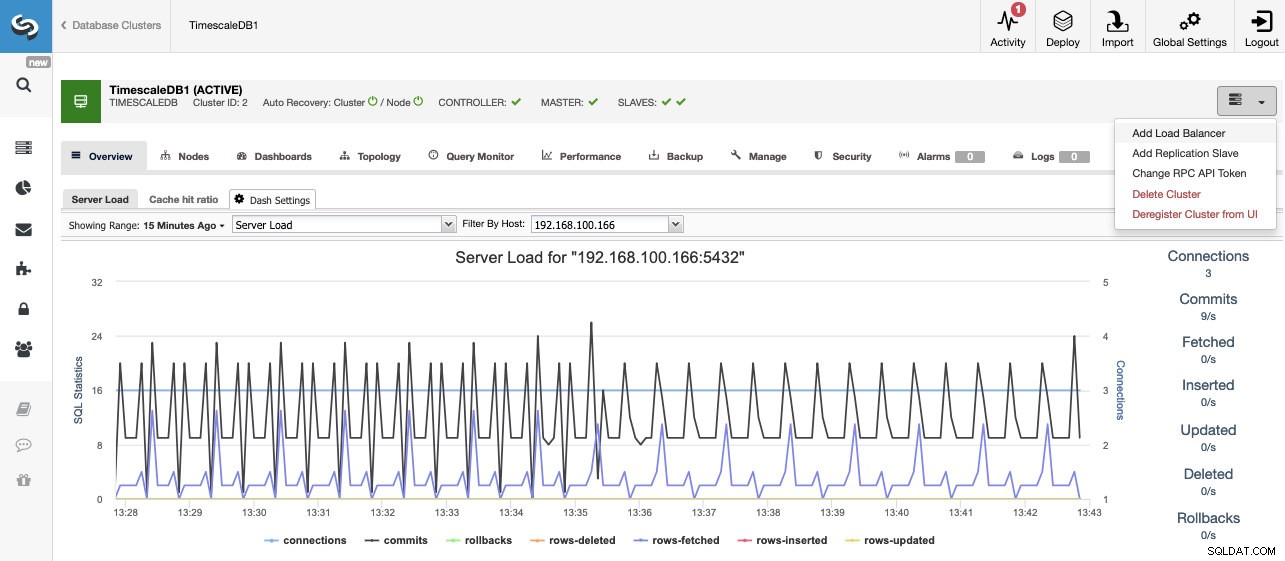
När uppgiften är klar kan vi se vårt nya TimescaleDB-kluster på huvudskärmen för ClusterControl.

När vi har skapat vårt kluster kan vi utföra flera uppgifter på det, som att lägga till en lastbalanserare (HAProxy) eller en ny replik.
Skala TimescaleDB
Om vi går till klusteråtgärder och väljer "Lägg till replikeringsslav", kan vi antingen skapa en ny replik från början eller lägga till en befintlig TimescaleDB-databas som en replik.
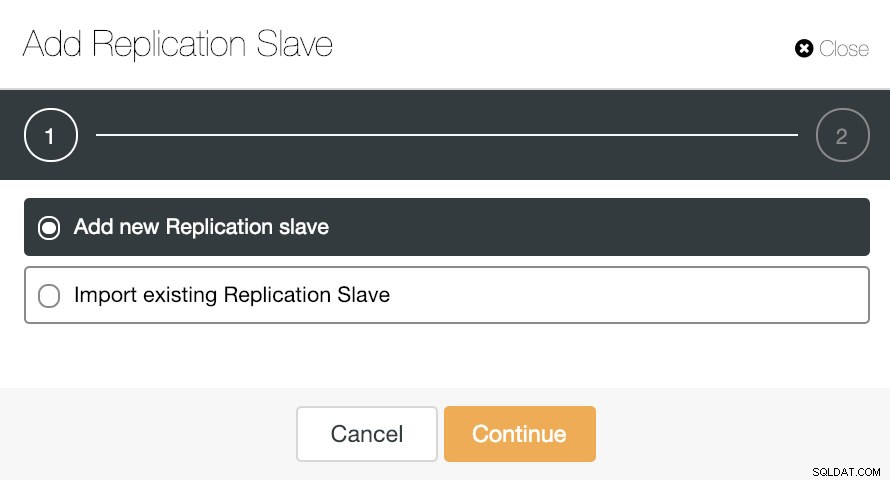
Låt oss se hur det kan vara en väldigt enkel uppgift att lägga till en ny replikeringsslav.
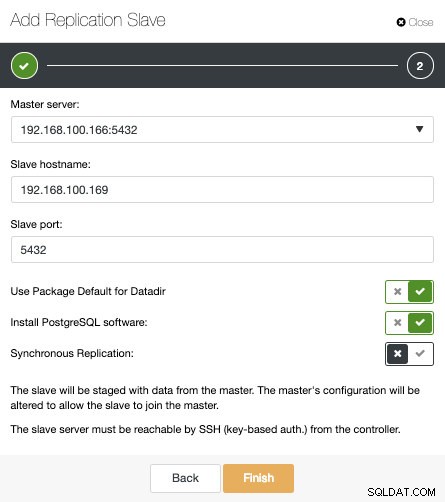
Som du kan se på bilden behöver vi bara välja vår Masterserver, ange IP-adressen för vår nya slavserver och databasporten. Sedan kan vi välja om vi vill att ClusterControl ska installera programvaran åt oss och om replikeringsslaven ska vara Synchronous eller Asynchronous.
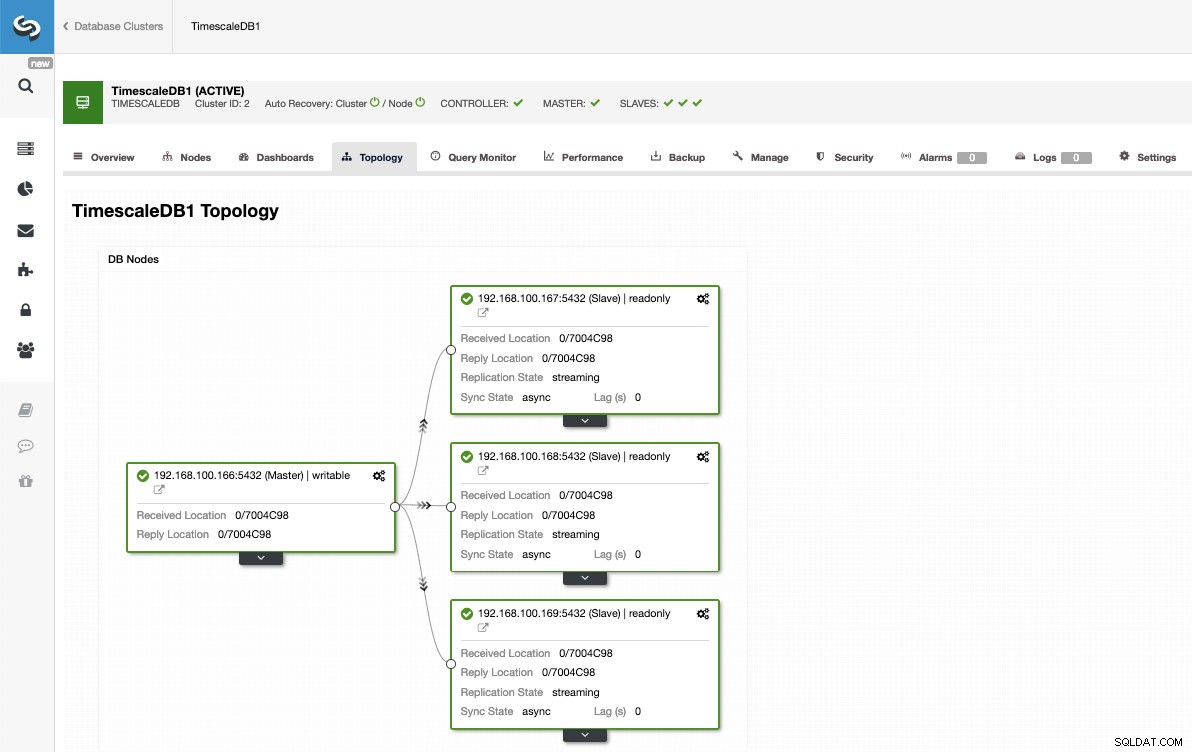
På så sätt kan vi lägga till så många repliker som vi vill och sprida lästrafik mellan dem med hjälp av en lastbalanserare, som vi också kan implementera med ClusterControl.
Från ClusterControl kan du också utföra olika hanteringsuppgifter som Reboot Host, Rebuild Replication Slave eller Promote Slave, med ett klick.
Slutsats
Som vi har sett ovan kan du nu distribuera TimescaleDB genom att använda ClusterControl. När ClusterControl väl har implementerats, erbjuder ClusterControl en hel rad funktioner, från övervakning, varning, automatisk failover, säkerhetskopiering, punkt-i-tid återställning, backupverifiering, till skalning av läsrepliker. Detta kan hjälpa dig att hantera TimescaleDB på ett vänligt och intuitivt sätt.