Spark började sitt liv 2009 som ett projekt inom AMPLab vid University of California, Berkeley. Mer specifikt föddes det ur nödvändigheten att bevisa begreppet Mesos, som också skapades i AMPLab. Spark diskuterades först i Mesos vitbok med titeln Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, skriven framför allt av Benjamin Hindman och Matei Zaharia.
Det uppstod som en snabb och bekväm lösning för att utföra komplexa analyser av storskalig data. Spark utvecklades som ett nytt ramverk för bearbetning av big data som åtgärdar många av bristerna i MapReduce-modellen. Den stöder storskalig dataanalys, och data kan komma från olika källor som realtid, batchbearbetning i olika format som bilder, texter, grafer och många fler. Förutom Apache Spark-kärnan tillhandahåller den också några användbara bibliotek för big data-analys.
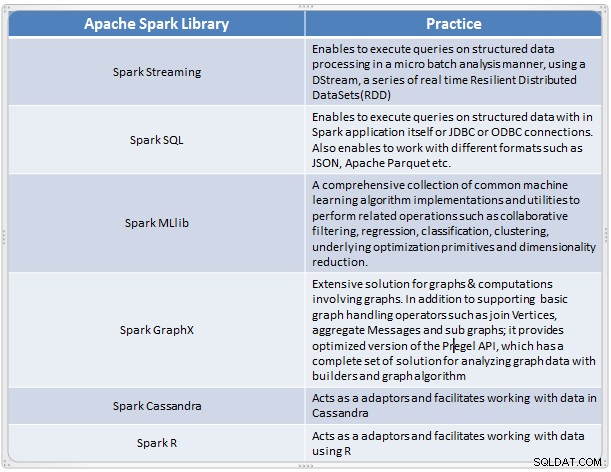
Översikt över Spark-komponenter
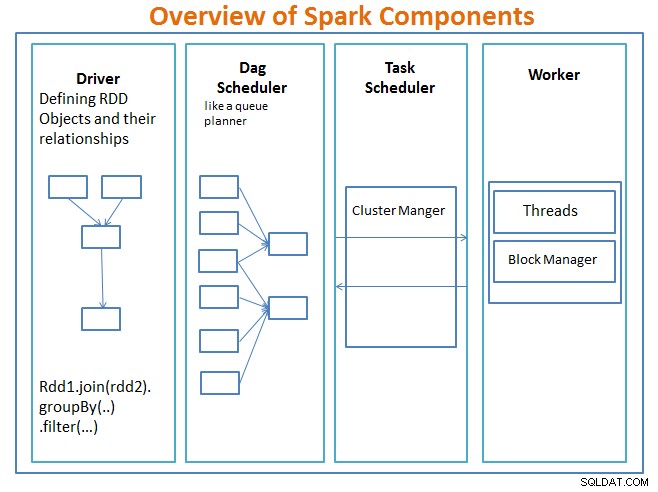
föraren är koden som inkluderar huvudfunktionen och definierar resilient distributed datasets (RDDs) och deras transformationer. RDD:er är de huvudsakliga datastrukturerna som kommer att användas i våra Spark-program.
Parallella operationer på RDD:erna skickas till DAG-schemaläggaren , vilket kommer att optimera koden och komma fram till en effektiv DAG som representerar databearbetningsstegen i applikationen.
Resulterande DAG skickas till klusterhanteraren och klusterchefen har information om arbetarna, tilldelade trådar och platsen för datablock och är ansvarig för att tilldela specifika bearbetningsuppgifter till arbetare. Den hanterar också betalningen tillbaka i fallet om arbetarna misslyckas. Klusterchefen kan vara YARN, Mesos, Sparks klusterchef.
arbetaren tar emot arbetsenheter och data att hantera och arbetaren utför sin specifika uppgift utan kunskap om hela DAG och dess resultat skickas tillbaka till förarapplikationerna.
Spark är, liksom andra big data-verktyg, kraftfullt, kapabelt och väl lämpade för att hantera en rad datautmaningar. Spark, liksom andra big data-teknologier, är inte nödvändigtvis det bästa valet för varje databearbetningsuppgift.
I del 2 – vi kommer att diskutera grunderna för Spark-koncept som Resilient Distributed Dataset, Shared Variables, SparkContext, Transformations, Action , och fördelar med att använda Spark tillsammans med exempel och när du ska använda Spark.
Referens:
Lär dig Spark in a Day av Acodemy &Hadoop Applications Architectures.