JPA (Java Persistence Annotation ) är Javas standardlösning för att överbrygga gapet mellan objektorienterade domänmodeller och relationsdatabassystem. Tanken är att mappa Java-klasser till relationstabeller och egenskaper för dessa klasser till raderna i tabellen. Detta förändrar semantiken för den övergripande upplevelsen av Java-kodning genom att sömlöst samarbeta två olika teknologier inom samma programmeringsparadigm. Den här artikeln ger en översikt och dess stödjande implementering i Java.
En översikt
Relationsdatabaser är kanske den mest stabila av alla beständighetsteknologier som finns tillgängliga i datoranvändning istället för alla komplexiteter som är involverade i den. Det beror på att idag, även i en tid av så kallade "big data", är "NoSQL" relationsdatabaser konsekvent efterfrågade och blomstrande. Relationsdatabaser är stabil teknologi, inte bara genom ord utan genom dess existens genom åren. NoSQL kan vara bra för att hantera stora mängder strukturerad data i företaget, men de många transaktionella arbetsbelastningarna hanteras bättre genom relationsdatabaser. Det finns också några bra analysverktyg förknippade med relationsdatabaser.
För att kommunicera med relationsdatabasen har ANSI standardiserat ett språk som heter SQL (Structured Query Language ). Ett uttalande skrivet på detta språk kan användas både för att definiera och manipulera data. Men problemet med SQL när man hanterar Java är att de har en oöverensstämmande syntaktisk struktur och väldigt olika i kärnan, vilket innebär att SQL är procedurmässigt medan Java är objektorienterat. Så en fungerande lösning eftersträvas så att Java kan tala objektorienterat och den relationella databasen fortfarande skulle kunna förstå varandra. JPA är svaret på det samtalet och tillhandahåller mekanismen för att skapa en fungerande lösning mellan de två.
Relation till objektmappning
Java-program interagerar med relationsdatabaser genom att använda JDBC (Anslutning till Java-databas ) API. En JDBC-drivrutin är nyckeln till anslutningen och gör att ett Java-program kan manipulera databasen genom att använda JDBC API. När anslutningen har upprättats avfyrar Java-programmet SQL-frågor i form av String s för att kommunicera skapa, infoga, uppdatera och ta bort operationer. Detta är tillräckligt för alla praktiska ändamål, men obekvämt ur en Java-programmerares synvinkel. Tänk om strukturen av relationstabeller kan omformas till rena Java-klasser och sedan kan du hantera dem på vanligt objektorienterat sätt? Strukturen för en relationstabell är en logisk representation av data i tabellform. Tabeller är sammansatta av kolumner som beskriver entitetsattribut och rader är samlingen av entiteter. Till exempel kan en ANSTÄLLDA tabell innehålla följande enheter med deras attribut.
| Emp_number | Namn | dept_no | Lön | Plats |
| 112233 | Peter | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Rader är unika genom primärnyckel (emp_number) i en tabell; detta möjliggör en snabb sökning. En tabell kan vara relaterad till en eller flera tabeller med någon nyckel, till exempel en främmande nyckel (dept_no), som relaterar till motsvarande rad i en annan tabell.
Enligt Java Persistence 2.1-specifikationen lägger JPA till stöd för schemagenerering, typkonverteringsmetoder, användning av entitetsgraf i frågor och sökoperationer, osynkroniserat persistenskontext, anrop av lagrad procedur och injektion i entitetslyssnarklasser. Den innehåller också förbättringar av frågespråket Java Persistence, Criteria API och av kartläggningen av inbyggda frågor.
Kort sagt, det gör allt för att ge illusionen att det inte finns någon processuell del i att hantera relationsdatabaser och att allt är objektorienterat.
JPA-implementering
JPA beskriver relationsdatahantering i Java-applikationer. Det är en specifikation och det finns ett antal implementeringar av den. Några populära implementeringar är Hibernate, EclipseLink och Apache OpenJPA. JPA definierar metadata via anteckningar i Java-klasser eller via XML-konfigurationsfiler. Däremot kan vi använda både XML och anteckning för att beskriva metadata. I ett sådant fall åsidosätter XML-konfigurationen anteckningarna. Detta är rimligt eftersom anteckningar skrivs med Java-koden, medan XML-konfigurationsfiler är externa till Java-koden. Därför behöver senare, om några, ändringar göras i metadata; i fallet med anteckningsbaserad konfiguration kräver den direkt åtkomst till Java-kod. Detta kanske alltid inte är möjligt. I ett sådant fall kan vi skriva ny eller ändrad metadatakonfiguration i en XML-fil utan antydan till ändring i originalkoden och ändå få önskad effekt. Detta är fördelen med att använda XML-konfiguration. Anteckningsbaserad konfiguration är dock mer bekväm att använda och är det populära valet bland programmerare.
- Viloläge är den populära och mest avancerade bland alla JPA-implementeringar på grund av Red Hat. Den använder sina egna tweaks och tillagda funktioner som kan användas utöver dess JPA-implementering. Den har en större gemenskap av användare och är väl dokumenterad. Några av de ytterligare egenutvecklade funktionerna är stöd för multi-tenancy, sammanfogning av oassocierade enheter i frågor, tidsstämpelhantering och så vidare.
- EclipseLink är baserad på TopLink och är en referensimplementering av JPA-versioner. Den tillhandahåller standard JPA-funktioner förutom några intressanta egenutvecklade funktioner, såsom stöd från multi-tenancy, hantering av databasändringshändelser och så vidare.
Använda JPA i ett Java SE-program
För att använda JPA i ett Java-program behöver du en JPA-leverantör som Hibernate eller EclipseLink, eller något annat bibliotek. Du behöver också en JDBC-drivrutin som ansluter till den specifika relationsdatabasen. Till exempel, i följande kod, har vi använt följande bibliotek:
- Leverantör: EclipseLink
- JDBC-drivrutin: JDBC-drivrutin för MySQL (Connector/J)
Vi kommer att upprätta en relation mellan två tabeller – anställd och avdelning – som en-till-en och en-till-många, som visas i följande EER-diagram (se figur 1).
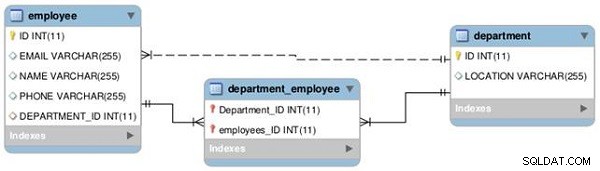
Figur 1: Tabellrelationer
anställd Tabell mappas till en entitetsklass med anteckning enligt följande:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
Och avdelningen tabellen mappas till en entitetsklass enligt följande:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Konfigurationsfilen, persistence.xml , skapas i META-INF katalog. Den här filen innehåller anslutningskonfigurationen, såsom JDBC-drivrutin som används, användarnamn och lösenord för databasåtkomst och annan relevant information som krävs av JPA-leverantören för att upprätta databasanslutningen.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Entiteter består inte själva. Logik måste tillämpas för att manipulera enheter för att hantera deras ihållande livscykel. EntityManager gränssnittet från JPA låter applikationen hantera och söka efter enheter i relationsdatabasen. Vi skapar ett frågeobjekt med hjälp av EntityManager att kommunicera med databasen. För att skaffa EntityManager för en given databas använder vi ett objekt som implementerar en EntityManagerFactory gränssnitt. Det finns en statisk metod, kallad createEntityManagerFactory , i Persistens klass som returnerar EntityManagerFactory för beständighetsenheten som anges som en sträng argument. I följande rudimentära implementering har vi implementerat logiken.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Nu är vi redo att gå och skapa programmets huvudgränssnitt. Här har vi endast implementerat infogningsoperationen för enkelhetens skull och utrymmesbegränsningarna.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Obs! Se tillämplig Java API-dokumentation för detaljerad information om API:er som används i föregående kod. |
Slutsats
Som borde vara uppenbart är kärnterminologin för JPA- och Persistens-kontexten större än den glimt som ges här, men att börja med en snabb överblick är bättre än lång intrikat smutsig kod och deras konceptuella detaljer. Om du har lite erfarenhet av programmering i kärnan JDBC kommer du utan tvekan att uppskatta hur JPA kan göra ditt liv enklare. Vi kommer gradvis att dyka djupare in i JPA allt eftersom vi följer med i kommande artiklar.