Vi har alla blivit bortskämda med sökmotorers förmåga att "lösa" saker som stavfel, stavningsskillnader i namn eller någon annan situation där söktermen kan matcha på sidor vars författare kanske föredrar att använda en annan stavning av ett ord. Att lägga till sådana funktioner i våra egna databasdrivna applikationer kan på liknande sätt berika och förbättra våra applikationer, och även om kommersiella relationsdatabashanteringssystem (RDBMS) erbjuder sina egna fullt utvecklade skräddarsydda lösningar på detta problem, kan licenskostnaderna för dessa verktyg vara låga. räckvidd för mindre utvecklare eller små mjukvaruutvecklingsföretag.
Man skulle kunna hävda att detta skulle kunna göras med hjälp av en stavningskontroll istället. En stavningskontroll är dock vanligtvis till ingen nytta när man matchar en korrekt men alternativ stavning av ett namn eller annat ord. Matchning med ljud fyller denna funktionella lucka. Det är ämnet för dagens programmeringshandledning:hur man frågar efter ljud med Python med hjälp av metafoner.
Vad är Soundex?
Soundex utvecklades i början av 1900-talet som ett sätt för US Census att matcha namn baserat på hur de låter. Den användes sedan av olika telefonbolag för att matcha kundnamn. Den fortsätter att användas för fonetisk datamatchning till denna dag trots att den är begränsad till amerikansk engelska stavningar och uttal. Det är också begränsat till engelska bokstäver. De flesta RDBMS, som SQL Server och Oracle, tillsammans med MySQL och dess varianter, implementerar en Soundex-funktion och, trots dess begränsningar, fortsätter den att användas för att matcha många icke-engelska ord.
Vad är en dubbelmetafon?
Metafonen Algoritmen utvecklades 1990 och den övervinner några av begränsningarna hos Soundex. År 2000, en förbättrad uppföljare, Double Metaphone , var utvecklad. Dubbelmetafon returnerar ett primärt och sekundärt värde som motsvarar två sätt som ett enstaka ord kan uttalas på. Till denna dag är denna algoritm en av de bättre fonetiska algoritmerna med öppen källkod. Metaphone 3 släpptes 2009 som en förbättring av Double Metaphone, men det här är en kommersiell produkt.
Tyvärr implementerar många av de framträdande RDBMS som nämns ovan inte Double Metaphone, och de flesta framträdande skriptspråk tillhandahåller inte en stödd implementering av Double Metaphone. Python tillhandahåller dock en modul som implementerar Double Metaphone.
Exemplen som presenteras i denna Python-programmeringshandledning använder MariaDB version 10.5.12 och Python 3.9.2, båda körs på Kali/Debian Linux.
Hur man lägger till dubbel metafon i Python
Som alla Python-moduler kan pip-verktyget användas för att installera Double Metaphone. Syntaxen beror på din Python-installation. En typisk dubbelmetafoninstallation ser ut som följande exempel:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Observera att den extra versaler är avsiktlig. Följande kod är ett exempel på hur man använder Double Metaphone i Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Ovanstående Python-skript ger följande utdata när det körs i din integrerade utvecklingsmiljö (IDE) eller kodredigerare:
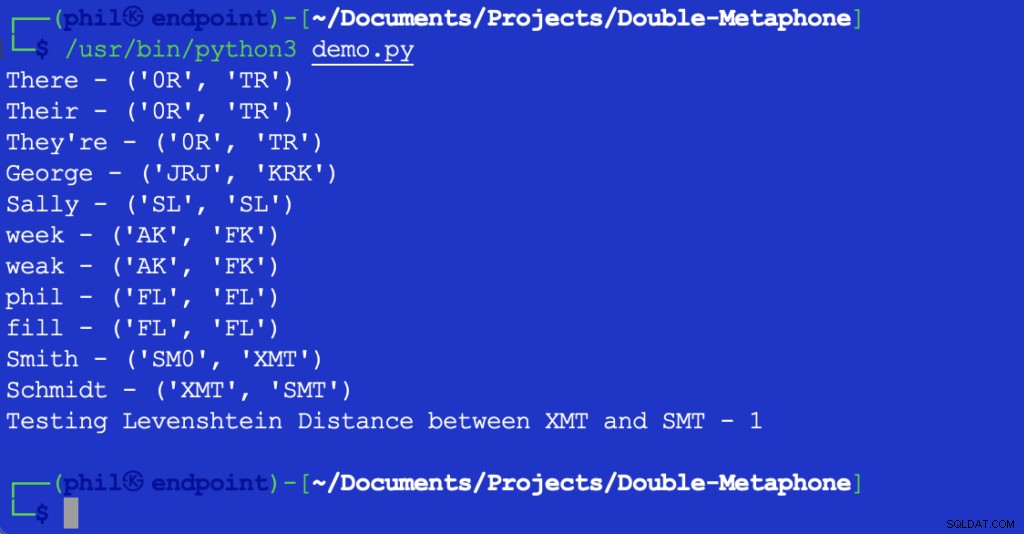
Figur 1 – Utdata av demoskript
Som man kan se här har varje ord både ett primärt och sekundärt fonetiskt värde. Ord som matchar både primära eller sekundära värden sägs vara fonetiska matchningar. Ord som delar minst ett fonetiskt värde, eller som delar de första par tecknen i något fonetiskt värde, sägs vara fonetiskt nära varandra.
De flesta bokstäver som visas motsvarar deras engelska uttal. X kan motsvara KS , SH , eller C . 0 motsvarar den e ljud i den eller där . Vokaler matchas bara i början av ett ord. På grund av det oräkneliga antalet skillnader i regionala accenter är det inte möjligt att säga att ord kan vara en objektivt exakt matchning, även om de har samma fonetiska värden.
Jämföra fonetiska värden med Python
Det finns många onlineresurser som kan beskriva den fullständiga funktionen av dubbelmetafonalgoritmen; detta är dock inte nödvändigt för att använda det eftersom vi är mer intresserade av att jämföra de beräknade värdena, mer än vi är intresserade av att beräkna värdena. Som nämnts tidigare, om det finns minst ett värde gemensamt mellan två ord, kan man säga att dessa värden är fonetiska matchningar , och fonetiska värden som är liknande är fonetiskt nära .
Att jämföra absoluta värden är lätt, men hur kan strängar bestämmas vara lika? Även om det inte finns några tekniska begränsningar som hindrar dig från att jämföra strängar med flera ord, är dessa jämförelser vanligtvis opålitliga. Håll dig till att jämföra enstaka ord.
Vad är Levenshtein-avstånd?
Levenshtein-avståndet mellan två strängar är antalet enstaka tecken som måste ändras i en sträng för att den ska matcha den andra strängen. Ett par strängar som har ett lägre Levenshtein-avstånd är mer lika varandra än ett par strängar som har ett högre Levenshtein-avstånd. Levenshtein Distance liknar Hamming Distance , men det senare är begränsat till strängar av samma längd, eftersom de fonetiska värdena för dubbelmetafonen kan variera i längd, är det mer meningsfullt att jämföra dessa med Levenshtein-avståndet.
Python Levenshtein Distance Library
Python kan utökas för att stödja Levenshtein-avståndsberäkningar via en Python-modul:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Observera att, som med installationen av DoubleMetaphone ovan syntaxen för anropet till pip kan variera. Python-Levenshtein-modulen ger mycket mer funktionalitet än bara beräkningar av Levenshtein-avstånd.
Koden nedan visar ett test för Levenshtein Avståndsberäkning i Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Att köra det här skriptet ger följande utdata:
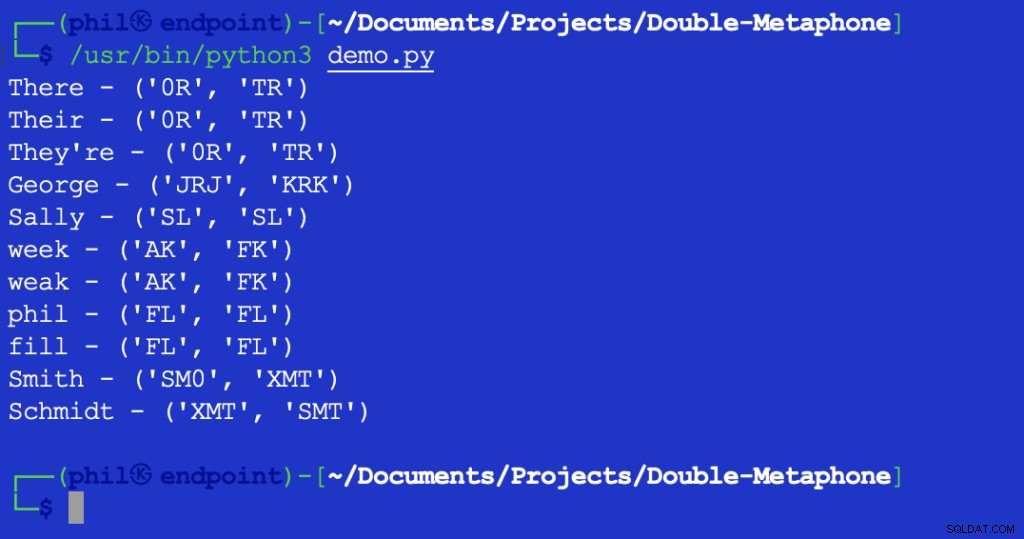
Figur 2 – Utdata från Levenshtein Distance test
Det returnerade värdet 1 indikerar att det finns ett tecken mellan XMT och SMT det är annorlunda. I det här fallet är det det första tecknet i båda strängarna.
Jämföra dubbla metafoner i Python
Det som följer är inte alla fonetiska jämförelser. Det är helt enkelt ett av många sätt att utföra en sådan jämförelse. För att effektivt jämföra den fonetiska närheten av två givna strängar måste varje fonetiskt värde för dubbelmetafon för en sträng jämföras med motsvarande fonetiska värde för dubbelmetafon för en annan sträng. Eftersom båda fonetiska värdena för en given sträng ges lika stor vikt, kommer medelvärdet av dessa jämförelsevärden att ge en ganska bra approximation av fonetisk närhet:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Var:
- DM1(1) :Första dubbelmetafonvärdet för sträng 1,
- DM1(2) :Andra dubbelmetafonvärde för sträng 1
- DM2(1) :Första dubbelmetafonvärdet för String 2
- DM2(2) :Andra dubbelmetafonvärde för sträng 2
- PN :Fonetisk närhet, med lägre värden närmare än högre värden. Ett nollvärde indikerar fonetisk likhet. Det högsta värdet för detta är antalet bokstäver i den kortaste strängen.
Den här formeln bryts ner i fall som Schmidt (XMT, SMT) och Smith (SM0, XMT) där det första fonetiska värdet på den första strängen matchar det andra fonetiska värdet för den andra strängen. I sådana situationer kan både Schmidt och Smith kan anses vara fonetiskt lika på grund av det delade värdet. Koden för närhetsfunktionen bör tillämpa formeln ovan endast när alla fyra fonetiska värden är olika. Formeln har också svagheter när man jämför strängar av olika längd.
Observera att det inte finns något särskilt effektivt sätt att jämföra strängar av olika längd, även om beräkning av Levenshtein-avståndet mellan två strängar faktorer i skillnader i stränglängd. En möjlig lösning skulle vara att jämföra båda strängarna upp till längden på den kortare av de två strängarna.
Nedan finns ett exempel på ett kodavsnitt som implementerar koden ovan, tillsammans med några testexempel:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Exempel Python-koden ger följande utdata:
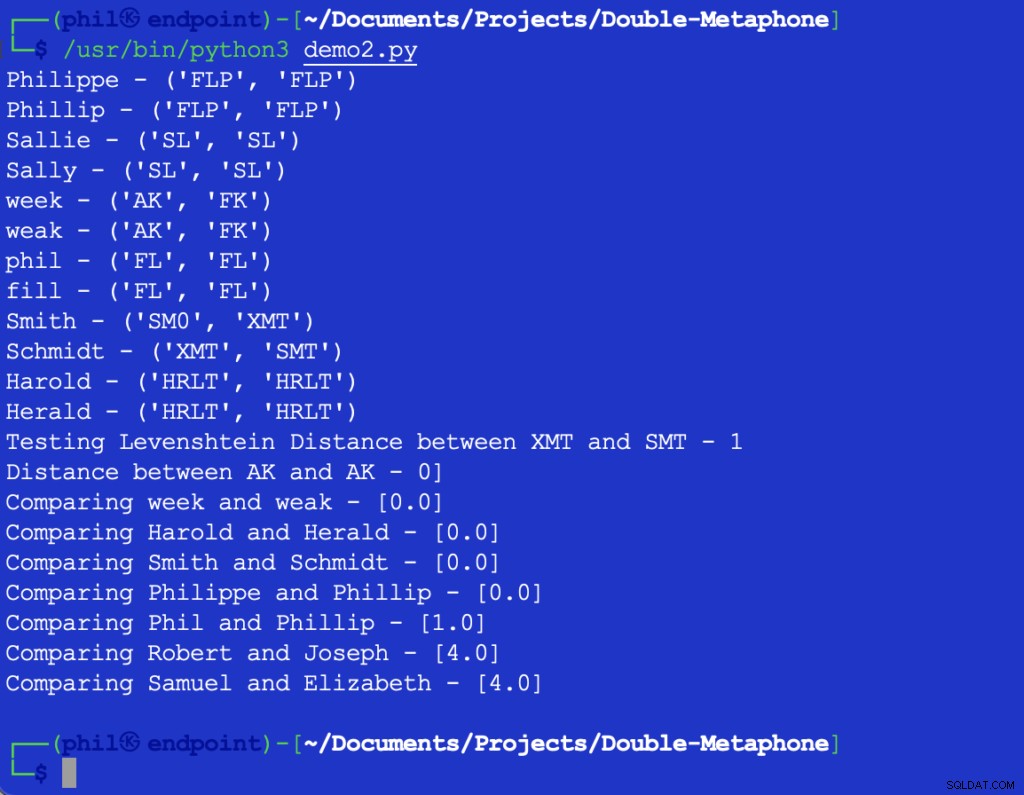
Figur 3 – Utdata från närhetsalgoritmen
Sampeluppsättningen bekräftar den allmänna trenden att ju större skillnaderna är i ord, desto högre utdata från Närhet funktion.
Databasintegration i Python
Koden ovan bryter mot det funktionella gapet mellan ett givet RDBMS och en dubbelmetafonimplementering. Utöver detta, genom att implementera Närhet funktion i Python blir det lätt att ersätta om en annan jämförelsealgoritm skulle föredras.
Tänk på följande MySQL/MariaDB-tabell:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
I de flesta databasdrivna applikationer komponerar mellanvaran SQL-satser för att hantera data, inklusive infogning av den. Följande kod kommer att infoga några exempelnamn i den här tabellen, men i praktiken kan vilken kod som helst från en webb- eller skrivbordsapplikation som samlar in sådan data göra samma sak.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Att köra den här koden skrivs inte ut något, men det fyller i testtabellen i databasen för nästa lista att använda. Att fråga tabellen direkt i MySQL-klienten kan verifiera att koden ovan fungerade:
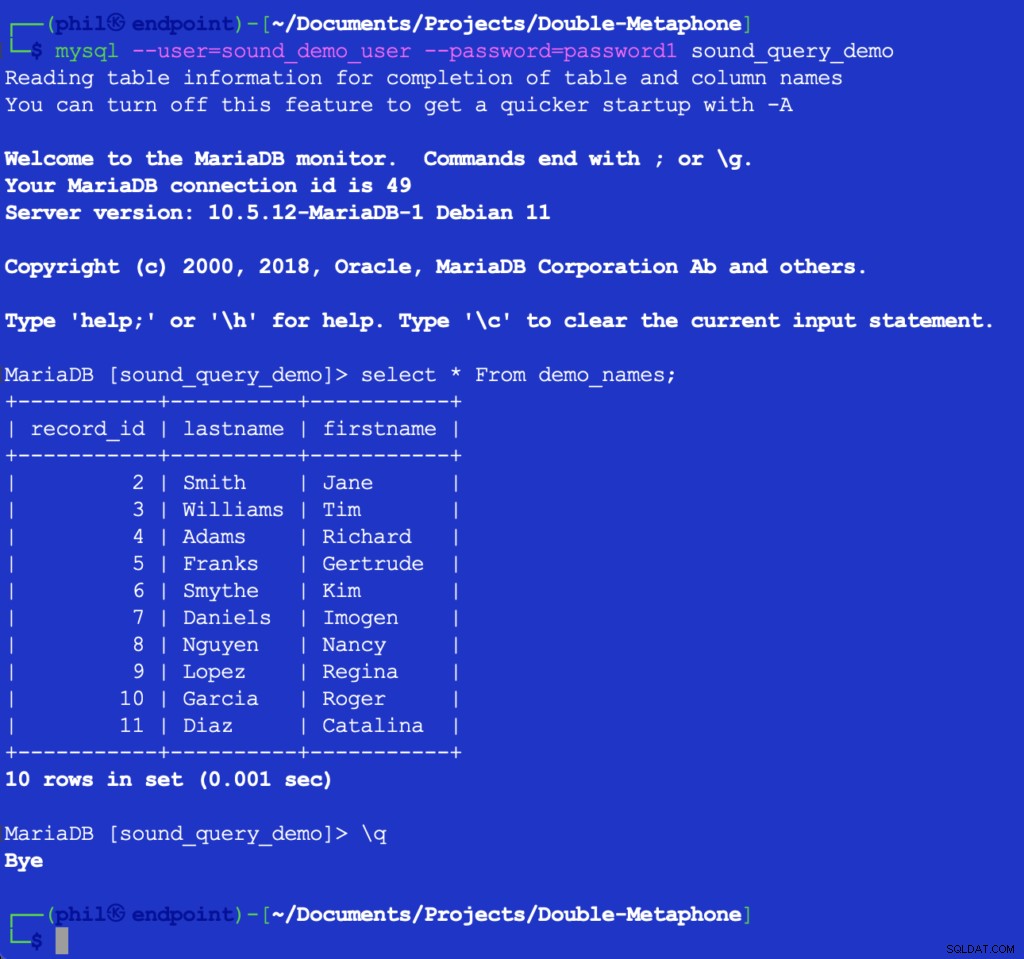
Figur 4- De infogade tabelldata
Koden nedan matar in en del jämförelsedata i tabelldata ovan och utför en närhetsjämförelse mot den:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Genom att köra den här koden får vi utdata nedan:
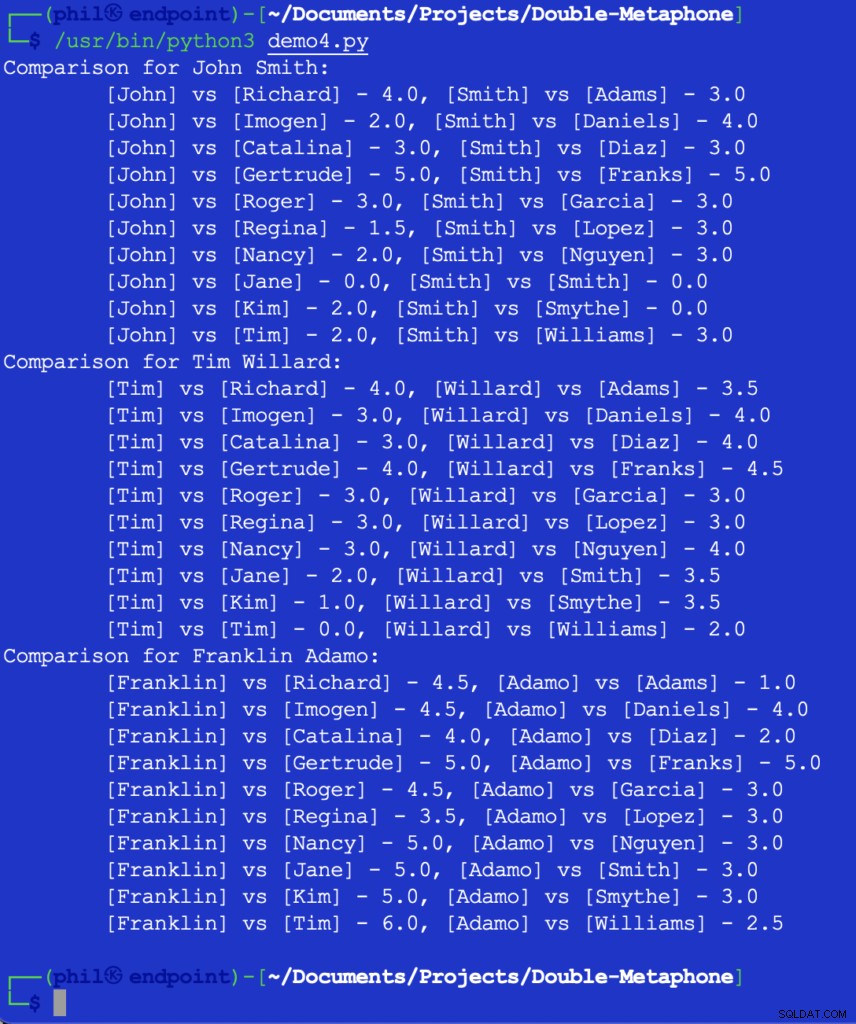
Figur 5 – Resultat av närhetsjämförelsen
Vid det här laget skulle det vara upp till utvecklaren att bestämma vad tröskeln skulle vara för vad som utgör en användbar jämförelse. Vissa av siffrorna ovan kan verka oväntade eller överraskande, men ett möjligt tillägg till koden kan vara ett OM uttalande för att filtrera bort alla jämförelsevärden som är större än 2 .
Det kan vara värt att notera att de fonetiska värdena i sig inte lagras i databasen. Detta beror på att de beräknas som en del av Python-koden och det finns inte ett verkligt behov av att lagra dessa någonstans då de kasseras när programmet avslutas, dock kan en utvecklare hitta värde i att lagra dessa i databasen och sedan implementera jämförelsen funktion inom databasen en lagrad procedur. Den enda stora nackdelen med detta är dock en förlust av kodportabilitet.
Sluta tankar om att söka efter data efter ljud med Python
Att jämföra data med ljud verkar inte få den "kärlek" eller uppmärksamhet som att jämföra en data genom bildanalys kan få, men om en applikation måste hantera flera liknande klingande varianter av ord på flera språk, kan det vara en mycket användbar verktyg. En användbar egenskap hos denna typ av analys är att en utvecklare inte behöver vara en lingvistik eller fonetisk expert för att kunna använda dessa verktyg. Utvecklaren har också stor flexibilitet när det gäller att definiera hur sådan data kan jämföras; jämförelserna kan justeras baserat på applikationens eller affärslogikbehoven.
Förhoppningsvis kommer detta studieområde att få mer uppmärksamhet inom forskningssfären och det kommer att finnas mer kapabla och robusta analysverktyg framöver.