Hashindex är en integrerad del av databaser. Om du någonsin har använt en databas är chansen stor att du har sett dem i aktion utan att ens inse det.
Hash-index skiljer sig i arbete från andra typer av index eftersom de lagrar värden snarare än pekare till poster som finns på en disk. Detta säkerställer snabbare sökning och infogning i indexet. Det är därför hashindex ofta används som primärnycklar eller unika identifierare.
Förstå hashindex
Ett hashindex är en indextyp som är vanligast i datahantering. Den skapas vanligtvis i en kolumn som innehåller unika värden, till exempel en primärnyckel eller e-postadress. Den största fördelen med att använda hashindex är deras snabba prestanda.
Konceptet bakom dessa index kan vara sofistikerat att förstå för någon som aldrig har hört talas om dem förut. Det är dock viktigt att förstå hashindex om du behöver förstå hur databaser fungerar. Det är nödvändigt för att lösa vanliga problem relaterade till databaser och deras hastighet.
Den goda nyheten är att med lite tålamod och en avstängd mobiltelefon kan du säkert behärska hashindex! Så låt oss ta en bättre titt.
Snabbt och enkelt
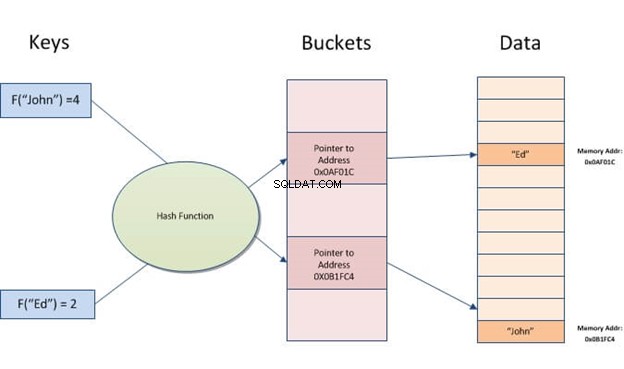
Ett hashindex är en datastruktur som kan användas för att påskynda databasfrågor. Det fungerar genom att konvertera indataposter till en uppsättning hinkar. Varje hink har samma antal poster som alla andra hinkar i tabellen. Således, oavsett hur många olika värden du har för en viss kolumn, kommer varje rad alltid att mappas till en hink.
Hash-index möjliggör snabba uppslagningar av data som lagras i tabeller. De fungerar genom att skapa en indexnyckel från värdet och sedan lokalisera den baserat på den resulterande hashen. Det är användbart när det finns mycket indata med liknande värden eller dubbletter, eftersom det bara behöver jämföra nycklar istället för att titta igenom alla poster.
Var detta varken snabbt eller lätt? För att förstå hur hashindex fungerar och varför de är så kraftfulla måste du förstå vad som menas med hash.
Hashing tar en bit information (en sträng) och förvandlar den till en adress eller pekare för snabb åtkomst senare.
Tanken med hashing är att data tilldelas ett litet antal. När du letar upp data behöver du faktiskt inte sålla bland massor. Slå istället upp den där siffran. Det enklaste exemplet är Ctrl+F-att använda ordet du letar efter i en text istället för att läsa dussintals sidor själv.
Vad är hashindex för?
Ett hashindex är ett sätt att påskynda sökprocessen. Med traditionella index måste du skanna igenom varje rad för att se till att din fråga är framgångsrik. Men med hashindex är detta inte fallet!
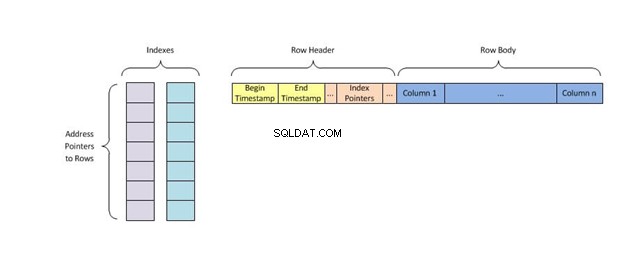
Varje nyckel i indexet innehåller bara en rad med tabelldata och använder indexeringsalgoritmen som kallas hashing som tilldelar dem en unik plats i minnet, vilket eliminerar alla andra nycklar med dubbletter av värden innan de hittar det de letar efter.
Hashindex är ett av många sätt att organisera data i en databas. De fungerar genom att ta input och använda den som en nyckel för lagring på en disk. Dessa nycklar eller hashvärden , kan vara allt från stränglängder till tecken i inmatningen.
Hashindex används oftast när man frågar efter specifika indata med specifika attribut. Det kan till exempel vara att hitta alla A-bokstäver som är högre än 10 cm. Du kan göra det snabbt genom att skapa en hashindexfunktion.
Hash-index är en del av PostgreSQL-databassystemet. Detta system utvecklades för att öka hastigheten och prestanda. Hashindex kan användas tillsammans med andra indextyper, såsom B-tree eller GiST.
Ett hashindex lagrar nycklar genom att dela upp dem i mindre bitar som kallas hinkar, där varje hink ges ett heltals-ID-nummer för att snabbt hämta det när man söker efter en nyckels plats i hashtabellen. Hinkarna lagras sekventiellt på en disk så att data de innehåller snabbt kan nås.
Fler tekniska förklaringar finns på denna sida (högerklicka och välj "Översätt till engelska").
Fördelar
Den största fördelen med att använda hashindex är att de möjliggör snabb åtkomst när posten hämtas med nyckelvärdet. Det är ofta användbart för frågor med ett likhetsvillkor. Att använda hash-riktmärken kräver inte mycket lagringsutrymme. Det är alltså ett effektivt verktyg, men inte utan nackdelar.
Nackdelar
Hashindex är en relativt ny indexeringsstruktur med potential att ge betydande prestandafördelar. Du kan tänka på dem som en förlängning av binära sökträd (BST).
Hash-index fungerar genom att lagra data i hinkar baserat på deras hash-värden, vilket möjliggör snabb och effektiv hämtning av data. De är garanterat i sin ordning.
Det är dock omöjligt att lagra dubbletter av nycklar i en hink. Därför kommer det alltid att finnas några omkostnader. Men än så länge uppväger fördelarna med att använda hashindex nackdelarna.
Hur fungerar allt på lite mer djup?
Låt oss ta en demo aviasales databas för att få en mer djupgående förståelse för hur hashindex fungerar.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Här kan du se hur vi implementerar hashindex genom att sammanställa data till uppsättningar.
Detta är ett enkelt exempel, men observera att begränsningar kommer med mindre kodinfrastruktur. Det kan finnas en brist på WAL-loggåtkomst eller en oförmåga att återställa index (index?) efter en krasch. Dessutom kanske index inte deltar i replikering – det beror på att PostgreSQL är föråldrat. Men precis som med Python får du varningar som ofta gör att du kan förhindra misstag.
Du kan ta en djupare titt i dessa index om du är tillräckligt intresserad. För det skapar vi en sidinspektion tilläggsinstans.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Om du vill inspektera koden fullständigt, börja med README.
Sammanfattning
Hashindex är en datastruktur som påskyndar processen att söka information i stora databaser. De fungerar genom att dela upp data i mindre bitar och sedan sortera dem. Således, när du söker efter något, kan du hitta det mycket snabbare.
Om du vill leta upp fler saker finns det resurser för DYOR. Håll också utkik efter våra nya artiklar, som kommer ut snabbare än du kan Ctrl+F ordet "hash" på den här sidan. Hoppas detta hjälper!