Har du svårt för SQL UNION? Det händer om resultaten du kombinerade stoppar din SQL Server. Eller en rapport som har fungerat tidigare dyker upp en ruta med en röd X-ikon. Ett "Operand typ clash"-fel inträffar som pekar på en linje med UNION. "Elden" börjar. Låter det bekant?
Oavsett om du har använt SQL UNION ett tag eller bara börjat, skadar inte ett fuskblad eller en kortfattad uppsättning anteckningar. Detta är vad du kommer att få idag i detta inlägg. Den här listan erbjuder 10 användbara tips för både nybörjare och veteraner. Det kommer också att finnas exempel och några avancerade diskussioner.

[sendpulse-form id=”11900″]
Men innan vi går in på den första punkten, låt oss förtydliga villkoren.
UNION är en av uppsättningsoperatorerna i SQL som kombinerar 2 eller fler resultatuppsättningar. Det kan vara praktiskt när du behöver kombinera namn, månadsstatistik och mer från olika källor. Och oavsett om du använder SQL Server, MySQL eller Oracle kommer syftet, beteendet och syntaxen att vara väldigt lika. Men hur fungerar det?
1. Använd SQL UNION för att kombinera Unik Rekord
Om du använder UNION för att kombinera resultatuppsättningar tar du bort dubbletter.
Varför är detta viktigt?
För det mesta vill du inte ha resultat med dubbletter. En rapport med dubbla linjer slösar bläck och papper i papperskopior. Och detta kommer att reta upp dina användare.
Hur man använder det
Du kombinerar resultaten av SELECT-satserna med UNION däremellan.
Innan vi börjar med exemplet, låt oss förbereda våra exempeldata.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Vi kommer att använda data som genereras av ovanstående kod tills det tredje tipset. Nu när vi är redo, nedan är exemplet:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Vi har 3 exemplar av samma kunders namn och förväntar oss att unika poster kommer att försvinna. Se resultaten:
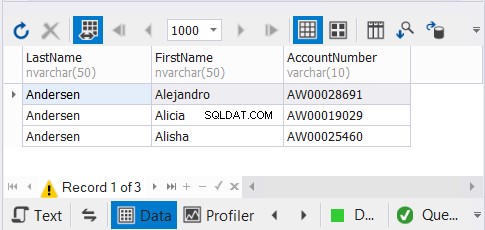
Lösningen dbForge Studio för SQL Server som vi använder för våra exempel visar endast 3 poster. Det kunde ha varit 9. Genom att tillämpa UNION tog vi bort dubbletterna.
Hur fungerar det?
Plandiagrammet i dbForge Studio avslöjar hur SQL Server producerar resultatet som visas i figur 1. Ta en titt:
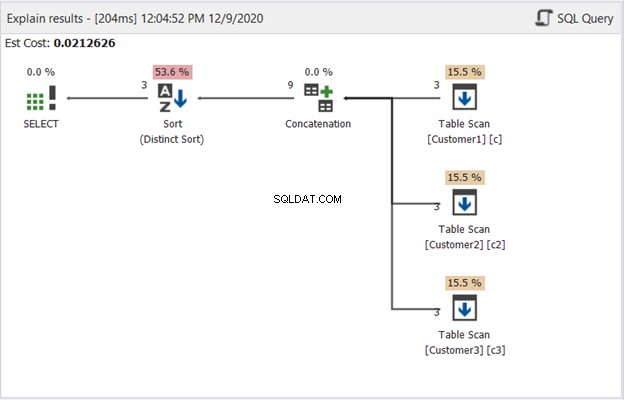
För att tolka figur 2, börja från höger till vänster:
- Vi hämtade 3 poster från varje Table Scan-operatör. Det är de 3 SELECT-satserna från exemplet ovan. Varje rad som går ut visar "3" vilket betyder 3 poster vardera.
- Konkateneringsoperatorn kombinerar resultaten. Raden som går ut visar "9" – en utdata på 9 poster från kombinationen av resultat.
- Operatorn Distinct Sorter säkerställer att unika poster blir slutresultatet. Linjen som går ut visar "3", vilket överensstämmer med antalet poster i figur 1.
Diagrammet ovan visar hur UNION bearbetas av SQL Server. Antalet och typen av operatorer som används kan variera beroende på frågan och den underliggande datakällan. Men sammanfattningsvis fungerar en UNION enligt följande:
- Hämta resultaten av varje SELECT-sats.
- Kombinera resultaten med en sammanfogningsoperator.
- Om de kombinerade resultaten inte är unika, kommer SQL Server att filtrera bort dubbletterna.
Alla framgångsrika exempel med UNION följer dessa grundläggande steg.
2. Använd SQL UNION ALL för att kombinera poster med dubbletter
Genom att använda UNION ALL kombineras resultatuppsättningar med inkluderade dubbletter.
Varför är detta viktigt?
Du kanske vill kombinera resultatuppsättningar och sedan få posterna med dubbletter för bearbetning senare. Den här uppgiften är användbar för att rensa upp dina data.
Hur man använder det
Du kombinerar resultaten av SELECT-satserna med UNION ALL däremellan. Ta en titt på exemplet:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Ovanstående kod matar ut 9 poster som visas i figur 3:
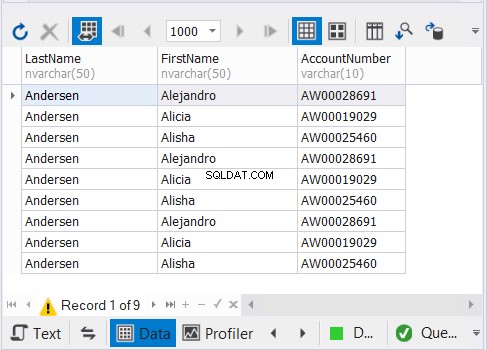
Hur fungerar det?
Liksom tidigare använder vi plandiagrammet för att veta hur detta fungerar:
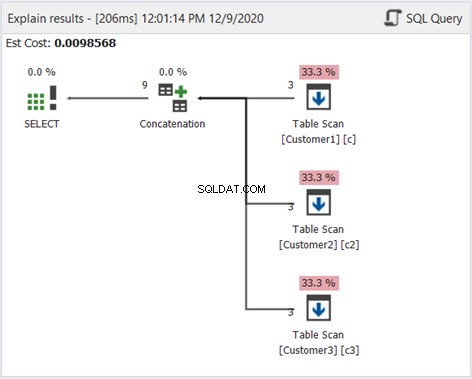
Förutom sorteringen i figur 2 är diagrammet ovan detsamma. Det är passande eftersom vi inte vill filtrera bort dubbletterna.
Diagrammet ovan visar hur UNION ALL fungerar. Sammanfattningsvis är dessa steg som SQL Server kommer att följa:
- Hämta resultaten av varje SELECT-sats.
- Kombinera sedan resultaten med en sammanfogningsoperator.
Framgångsrika exempel med UNION ALL följer detta mönster.
3. Du kan blanda SQL UNION och UNION ALLA utom gruppera dem med parenteser
Du kan blanda användningen av UNION och UNION ALL i minst tre SELECT-satser.
Hur använder man det?
Du kombinerar resultaten av SELECT-satserna med antingen UNION eller UNION ALL däremellan. Parentes grupperar resultaten som kommer samman. Låt oss använda samma data för nästa exempel:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
Ovanstående exempel kombinerar resultaten av de två senaste SELECT-satserna utan dubbletter. Sedan kombinerar den det med resultatet av den första SELECT-satsen. Resultatet är i figur 5 nedan:
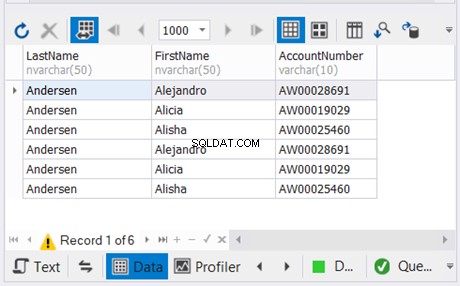
4. Kolumner i varje SELECT-sats bör ha kompatibla datatyper
Kolumner i varje SELECT-sats som använder UNION kan ha olika datatyper. Det är acceptabelt så länge de är kompatibla och tillåter implicit konvertering över dem. Den slutliga datatypen för de kombinerade resultaten kommer att använda datatypen med högst prioritet. Basen för den slutliga datastorleken är också data med störst storlek. När det gäller strängar kommer den att använda data med det största antalet tecken.
Varför är detta viktigt?
Om du behöver infoga resultatet av UNIONs i en tabell kommer den slutliga datatypen och storleken att avgöra om den passar i måltabellkolumnen eller inte. Om inte kommer ett fel att uppstå. Till exempel har en av kolumnerna i UNION en slutlig typ av NVARCHAR(50). Om måltabellkolumnen är VARCHAR(50) kan du inte infoga den i tabellen.
Hur fungerar det?
Det finns inget bättre sätt att förklara det än ett exempel:
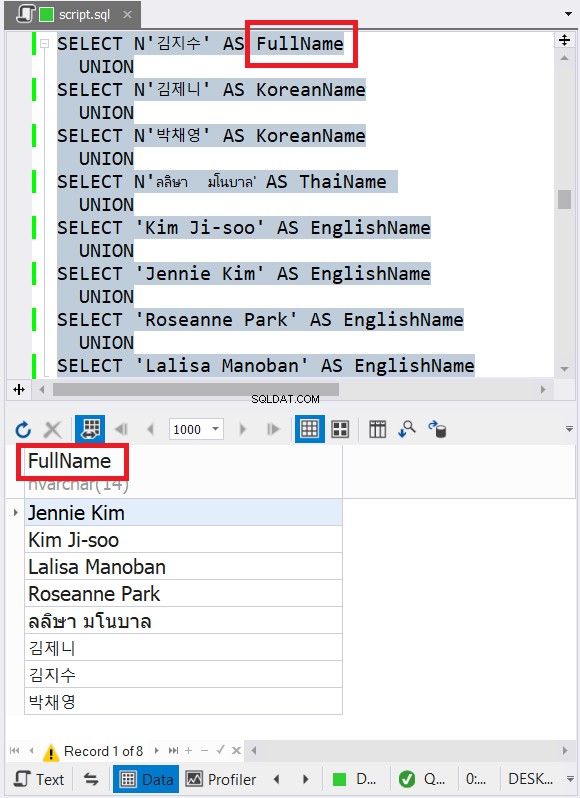
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
Exemplet ovan innehåller data med engelska, koreanska och thailändska teckennamn. Thai och koreanska är Unicode-tecken. Engelska tecken är det inte. Så vad tror du kommer den slutliga datatypen och storleken att bli? dbForge Studio visar det i resultatuppsättningen:
Lade du märke till den slutliga datatypen i figur 6? Det kan inte vara VARCHAR på grund av Unicode-tecken. Så det måste vara NVARCHAR. Samtidigt kan storleken inte vara mindre än 14 eftersom data med det största antalet tecken har 14 tecken. Se bildtexterna i rött i figur 6. Det är bra att inkludera datatypen och storleken i kolumnrubriken i dbForge Studio.
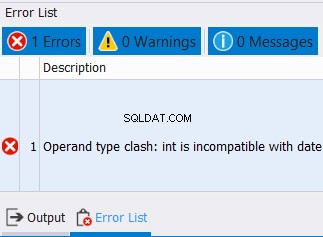
Det är fallet inte bara för strängdatatyper. Det gäller även siffror och datum. Om du försöker kombinera data med inkompatibla datatyper kommer ett fel att uppstå. Se exemplet nedan:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Vi kan inte kombinera datum och heltal i en kolumn. Så förvänta dig ett fel som det nedan:
5. Kolumnnamnen för de kombinerade resultaten kommer att använda kolumnnamnen för den första SELECT-satsen
Denna fråga relaterar till föregående tips. Lägg märke till kolumnnamnen i koden i tips #4. Det finns olika kolumnnamn i varje SELECT-sats. Vi såg dock det sista kolumnnamnet i det kombinerade resultatet i figur 6 tidigare. Grunden är alltså kolumnnamnet för den första SELECT-satsen.
Varför är detta viktigt?
Detta kan vara praktiskt när du behöver dumpa resultatet av UNION i en tillfällig tabell. Om du behöver hänvisa till dess kolumnnamn i de efterföljande påståendena, måste du vara säker på namnen. Såvida du inte använder en avancerad kodredigerare med IntelliSense, är du redo för ett annat fel i din T-SQL-kod.
Hur fungerar det?
Se figur 8 för tydligare resultat av att använda dbForge Studio:
6. Lägg till ORDER BY i den sista SELECT-satsen med SQL UNION för att sortera resultaten
Du måste sortera de kombinerade resultaten. I en serie SELECT-satser med UNION emellan kan du göra det med ORDER BY-satsen i den sista SELECT-satsen.
Varför är detta viktigt?
Användare vill sortera data som de föredrar i appar, webbsidor, rapporter, kalkylblad och mer.
Hur man använder det
Använd ORDER BY i den sista SELECT-satsen. Här är ett exempel:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
Exemplet ovan får det att se ut som att sorteringen bara sker i den sista SELECT-satsen. Men det är inte. Det kommer att fungera för det kombinerade resultatet. Du kommer att få problem om du placerar den i varje SELECT-sats. Se resultatet:
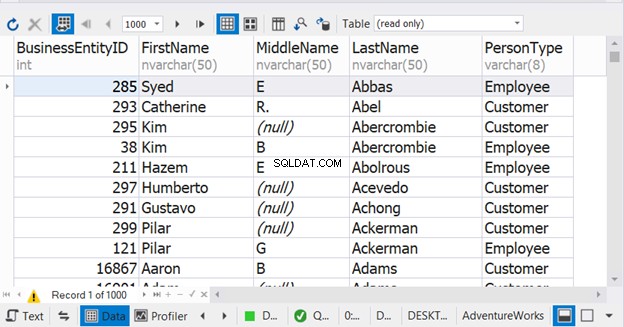
Utan ORDER BY kommer resultatuppsättningen att ha alla anställdas PersonType först följt av alla Customer PersonType . Figur 9 visar dock att namn blir sorteringsordningen för det kombinerade resultatet.
Om du försöker placera ORDER BY i varje SELECT-sats för att sortera, är det här vad som kommer att hända:
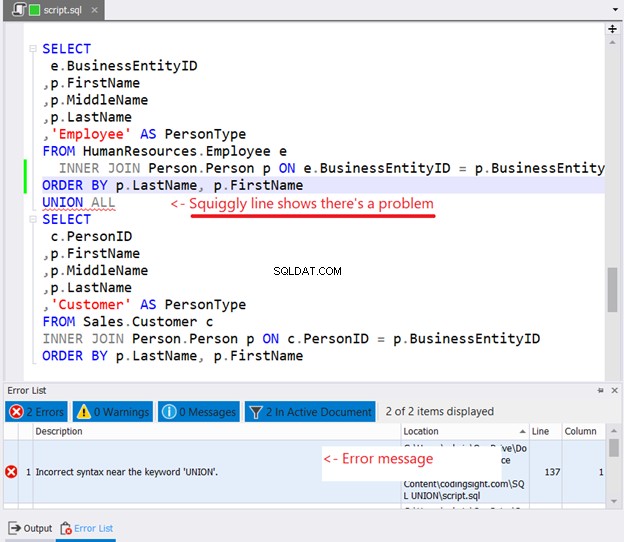
Såg du den snirkliga linjen i figur 10? Det är en varning. Om du inte märkte det och fortsatte, kommer ett fel att visas i fönstret med fellistan i dbForge Studio.
7. WHERE och GROUP BY-satser kan användas i varje SELECT-sats med SQL UNION
ORDER BY-satsen fungerar inte i varje SELECT-sats med UNION emellan. Däremot fungerar WHERE- och GROUP BY-satser.
Varför är detta viktigt?
Du kanske vill kombinera resultaten av olika frågor som filtrerar, räknar eller sammanfattar data. Du kan till exempel göra detta för att få den totala försäljningsordern för januari 2012 och jämföra den med januari 2013, januari 2014 och så vidare.
Hur man använder det
Placera WHERE- och/eller GROUP BY-satserna i varje SELECT-sats. Kolla in exemplet nedan:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Koden ovan kombinerar antalet januariorder under tre på varandra följande år. Kontrollera nu utdata:
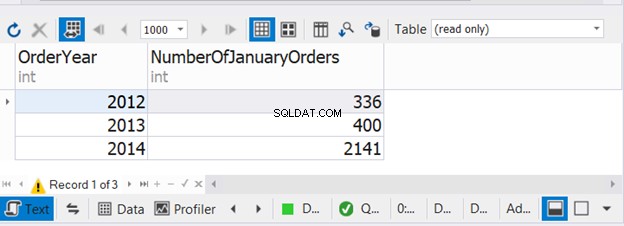
Det här exemplet visar att det är möjligt att använda WHERE och GROUP BY i var och en av de tre SELECT-satserna med UNION.
8. SELECT INTO Fungerar med SQL UNION
När du behöver infoga resultatet av en fråga med SQL UNION i en tabell kan du göra det genom att använda SELECT INTO.
Varför är detta viktigt?
Det kommer att finnas tillfällen då du behöver lägga in resultaten av en fråga med UNION i en tabell för vidare bearbetning.
Hur man använder det
Placera INTO-satsen i den första SELECT-satsen. Här är ett exempel:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Kom ihåg att endast placera en INTO-sats i den första SELECT-satsen.
Hur fungerar det
SQL Server följer mönstret för bearbetning av UNION. Sedan infogar den resultatet i tabellen specificerad i INTO-satsen.
9. Skilj SQL UNION från SQL JOIN
Både SQL UNION och SQL JOIN kombinerar tabelldata, men skillnaden i syntax och resultat är som natt och dag.
Varför är detta viktigt?
Om din rapport eller något krav behöver en JOIN men du gjorde en UNION, blir utdata fel.
Hur SQL UNION och SQL JOIN används
Det är SQL UNION vs. JOIN. Det här är en av de relaterade sökfrågorna och frågorna som en nybörjare ställer på Google när han lär sig om SQL UNION. Här är tabellen över skillnader:
| SQL UNION | SQL JOIN | |
| Vad är kombinerat | Rader | Kolumner (med en nyckel) |
| Antal kolumner per tabell | Samma för alla tabeller | Variabel (noll till alla kolumner/tabeller) |
I alla projekt jag varit med om så gäller SQL JOIN för det mesta. Jag hade bara ett fåtal fall som använde SQL UNION. Men som du har sett hittills är SQL UNION långt ifrån värdelös.
10. SQL UNION ALL är snabbare än UNION
Plandiagrammen i figur 2 och figur 4 tidigare tyder på att UNION kräver en extra operatör för att säkerställa unika resultat. Det är därför UNION ALL är snabbare.
Varför är detta viktigt?
Du, dina användare, dina kunder, din chef, alla vill ha snabba resultat. Att veta att UNION ALL är snabbare än UNION får dig att undra vad du ska göra om du behöver unika kombinerade resultat. Det finns en lösning, som du kommer att se senare.
SQL UNION ALL vs. UNION Performance
Figur 2 och figur 4 gav dig redan en uppfattning om vilken som är snabbare. Men kodexemplen som används är enkla med en liten resultatuppsättning. Låt oss lägga till några fler jämförelser med hjälp av miljontals poster för att göra det övertygande.
Till att börja med, låt oss förbereda data:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Det är 2 miljoner rekord. Jag hoppas att det är tillräckligt övertygande. Låt oss nu ha de två nästa frågeexemplen nedan.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Låt oss undersöka processerna som är involverade i dessa frågor och börja med den snabbare.
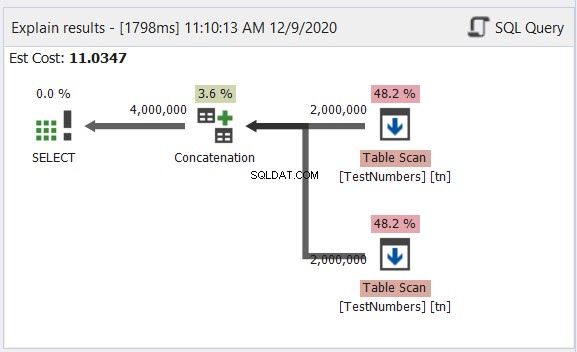
Plandiagramanalys
Diagrammet i figur 12 ser typiskt ut för en UNION ALL-process. Resultatet är dock 4 miljoner sammanlagt resultat. Se pilen som går ut från operatören Sammankoppling. Ändå beror det vanligtvis på att det inte hanterar dubbletterna.
Låt oss nu ha diagrammet över UNION-frågan i figur 13:
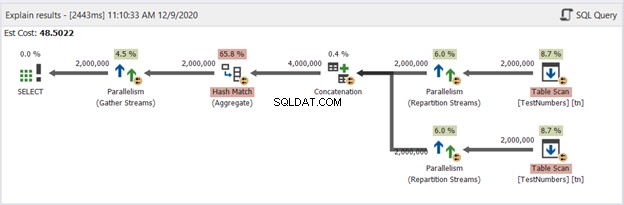
Den här är inte längre typisk. Planen blir en parallell frågeplan för att hantera borttagningen av dubbletter i fyra miljoner rader. Den parallella frågeplanen innebär att SQL Server måste dela processen med antalet tillgängliga processorkärnor.
Låt oss tolka det, med början från de högra operatorerna som går till vänster:
- Eftersom vi kombinerar en tabell till sig själv måste SQL Server hämta den två gånger. Se de två tabellskanningarna med två miljoner poster vardera.
- Ompartitionsströmoperatörer styr fördelningen av varje rad till nästa tillgängliga tråd.
- Konkatenering fördubblar resultatet till fyra miljoner. Detta tar fortfarande hänsyn till antalet processorkärnor.
- En Hash-matchning gäller för att ta bort dubbletterna. Detta är en dyr process med en operatörskostnad på 65,8 %. Som ett resultat slängdes två miljoner poster.
- Gather Streams kombinerar resultaten som gjorts i varje processorkärna eller tråd till en.
Det är för mycket arbete även om processen är uppdelad i flera trådar. Därför kommer du att dra slutsatsen att det kommer att gå långsammare. Men vad händer om det finns en lösning för att få unika poster med UNION ALL men snabbare än så här?
Unika resultat men snabbare fix med UNION ALL – Hur?
Jag kommer inte att få dig att vänta. Här är koden:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Detta kan vara en dålig lösning. Men kolla in dess plandiagram i figur 14:
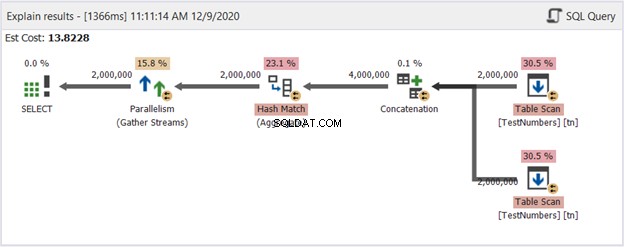
Så vad gjorde det bättre? Om du jämför det med figur 13 ser du att operatörerna för uppdelningsströmmen är borta. Men det använder fortfarande flera trådar för att få jobbet gjort. Å andra sidan innebär det att frågeoptimeraren anser att denna process är enklare att utföra än frågan som använder UNION.
Kan vi säkert dra slutsatsen att vi bör undvika att använda UNION och använda detta tillvägagångssätt istället? Inte alls! Kontrollera alltid utförandeplansdiagrammet! Det beror alltid på vad du vill att SQL Server ska ge dig. Den här visar bara att om du stöter på en prestandavägg måste du ändra din frågemetod.
Vad sägs om I/O-statistik?
Vi kan inte avfärda hur mycket resurser SQL Server behöver för att bearbeta våra frågeexempel. Det är därför vi också måste undersöka deras STATISTICS IO. Om vi jämför de tre frågorna ovan får vi de logiska läsningarna nedan:
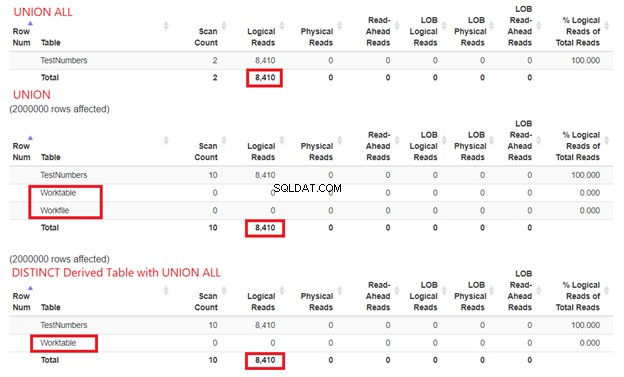
Från figur 15 kan vi fortfarande dra slutsatsen att UNION ALL är snabbare än UNION även om de logiska läsningarna är desamma. Närvaron av Worktable och Arbetsfil visar med tempdb för att få jobbet gjort. Under tiden, när vi använder SELECT DISTINCT från en härledd tabell med UNION ALL, visas tempdb användningen är mindre jämfört med UNION. Detta bekräftar ytterligare att vår analys från plandiagrammen tidigare är korrekt.
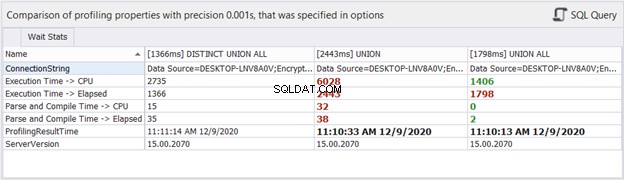
Vad sägs om tidsstatistik?
Även om förfluten tid kan ändras i varje exekvering vi gör för samma frågor, kan det ge oss en uppfattning och lägga till mer bevis till vår analys. dbForge Studio visar tidsskillnaderna för de tre frågorna ovan. Denna jämförelse överensstämmer med den tidigare analysen vi gjorde.
Slutsats
Vi täckte mycket bakgrund för att ge det du behöver för att använda SQL UNION och UNION ALL. Du kanske inte kommer ihåg allt efter att ha läst det här inlägget, så se till att du bokmärker den här sidan.
Om du gillar inlägget får du gärna dela det på sociala medier.