Databaser som tjänar affärsapplikationer bör ofta stödja tidsdata. Anta till exempel att ett avtal med en leverantör endast är giltigt under en begränsad tid. Det kan vara giltigt från en specifik tidpunkt och framåt, eller det kan vara giltigt för ett specifikt tidsintervall – från en starttidpunkt till en sluttidpunkt. Dessutom behöver du många gånger granska alla ändringar i en eller flera tabeller. Du kan också behöva kunna visa tillståndet vid en viss tidpunkt eller alla ändringar som gjorts i en tabell under en viss tidsperiod. Ur dataintegritetsperspektivet kan du behöva implementera många ytterligare tidsspecifika begränsningar.
Vi presenterar tidsdata
I en tabell med temporalt stöd representerar rubriken ett predikat med en minst engångsparameter som representerar intervallet när resten av predikatet är giltigt är det fullständiga predikatet därför ett tidsstämplat predikat. Rader representerar tidsstämplade propositioner, och radens giltiga tidsperiod uttrycks vanligtvis med två attribut:från och till , eller börja och slut .
Typer av tidstabeller
Du kanske har märkt under introduktionsdelen att det finns två typer av tidsmässiga problem. Den första är giltighetstiden av propositionen – under vilken period propositionen som en tidsstämplad rad i en tabell representerar faktiskt var sann. Till exempel var ett avtal med en leverantör endast giltigt från tidpunkt 1 till tidpunkt 2. Denna typ av giltighetstid är meningsfull för människor, meningsfull för verksamheten. Giltighetstiden kallas även ansökningstid eller mänsklig tid . Vi kan ha flera giltiga perioder för samma enhet. Till exempel kan ovannämnda kontrakt som gällde från tidpunkt 1 till tidpunkt 2 också vara giltigt från tidpunkt 7 till tidpunkt 9.
Den andra tidsfrågan är transaktionstiden . En rad för kontraktet som nämns ovan infogades vid tidpunkt 1 och var den enda versionen av sanningen som databasen kände till tills någon ändrade den, eller till och med till slutet av tiden. När raden uppdateras vid tidpunkt 2 var den ursprungliga raden känd för att vara sann mot databasen från tidpunkt 1 till tidpunkt 2. En ny rad för samma proposition infogas med tid som gäller för databasen från tidpunkt 2 till tidens slut. Transaktionstiden kallas även systemtid eller databastid .
Naturligtvis kan du också implementera både applikations- och systemversionstabeller. Sådana tabeller kallas bitemporala tabeller.
I SQL Server 2016 får du support för systemet time-out-of-box med systemversionerade tidstabeller . Om du behöver implementera ansökningstid måste du utveckla en lösning själv.
Allen's Interval Operators
Teorin för tidsdata i en relationsmodell började utvecklas för mer än trettio år sedan. Jag kommer att introducera en hel del användbara booleska operatorer och ett par operatorer som arbetar med intervaller och returnerar ett intervall. Dessa operatörer är kända som Allens operatörer, uppkallade efter J. F. Allen, som definierade ett antal av dem i en forskningsartikel från 1983 om tidsintervall. Alla av dem accepteras fortfarande som giltiga och nödvändiga. Ett databashanteringssystem kan hjälpa dig att hantera ansökningstider genom att implementera dessa operatörer direkt.
Låt mig först presentera notationen jag kommer att använda. Jag kommer att arbeta med två intervaller, betecknade i1 och i2 . Starttidpunkten för det första intervallet är b1 , och slutet är e1 ; starttidpunkten för det andra intervallet är b2 och slutet är e2 . Allens booleska operatörer definieras i följande tabell.
[tabell id=2 /]
Förutom booleska operatorer finns det Allens tre operatorer som accepterar intervall som indataparametrar och returnerar ett intervall. Dessa operatorer utgör enkel intervallalgebra . Observera att dessa operatorer har samma namn som relationsoperatorer som du förmodligen redan är bekant med:Union, Intersect och Minus. Men de beter sig inte exakt som sina relationella motsvarigheter. I allmänhet, med någon av de tre intervalloperatorerna, om operationen skulle resultera i en tom uppsättning tidpunkter eller i en uppsättning som inte kan beskrivas med ett intervall, bör operatören returnera NULL. En förening av två intervall är meningsfull endast om intervallen möts eller överlappar varandra. En korsning är meningsfull endast om intervallen överlappar varandra. Minusintervalloperatorn är bara vettig i vissa fall. Till exempel, (3:10) Minus (5:7) returnerar NULL eftersom resultatet inte kan beskrivas med ett intervall. Följande tabell sammanfattar definitionen av operatorerna för intervallalgebra.
[tabell id=3 /]
Överlappande frågor Prestandaproblem En av de mest komplexa operatörerna att implementera är överlappningarna operatör. Frågor som behöver hitta överlappande intervall är inte enkla att optimera. Sådana frågor är dock ganska frekventa på temporala tabeller. I den här och de följande två artiklarna kommer jag att visa dig ett par sätt att optimera sådana frågor. Men innan jag presenterar lösningarna, låt mig presentera problemet.
För att förklara problemet behöver jag lite data. Följande kod visar ett exempel på hur man skapar en tabell med giltighetsintervall uttryckta med b och e kolumner, där början och slutet av ett intervall representeras som heltal. Tabellen är fylld med demodata från tabellen WideWorldImporters.Sales.OrderLines. Observera att det finns flera versioner av WideWorldImporters databas, så du kan få lite olika resultat. Jag använde WideWorldImporters-Standard.bak backup-fil från https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 för att återställa den här demodatabasen på min SQL Server-instans .
Skapa demodata
Jag skapade en demotabell dbo.Intervals i tempd databas med följande kod.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Observera även indexen skapat. De två indexen är optimala för sökningar i början av ett intervall eller i slutet av ett intervall. Du kan kontrollera den minimala början och maximala slutet av alla intervaller med följande kod.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Du kan se i resultaten att den minimala starttiden är 1 och den maximala sluttiden är 1155.
Ge kontext till data
Du kanske märker att jag representerar början och slut tidpunkter som heltal. Nu måste jag ge intervallerna lite tidssammanhang. I det här fallet representerar en enstaka tidpunkt en dag . Följande kod skapar en datumuppslagstabell och befolkar den. Observera att startdatumet är den 1 juli 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Nu kan du sammanfoga tabellen dbo.Intervals till tabellen dbo.DateNums två gånger för att ge kontexten till de heltal som representerar början och slutet av intervallen.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Vi presenterar prestandaproblemet
Problemet med tidsfrågor är att när man läser från en tabell kan SQL Server bara använda ett index och framgångsrikt eliminera rader som inte är kandidater för resultatet bara från en sida, och sedan skannar resten av data. Till exempel måste du hitta alla intervall i tabellen som överlappar ett givet intervall. Kom ihåg att två intervall överlappar varandra när början av det första är lägre eller lika med slutet av det andra och början av det andra är lägre eller lika med slutet av det första, eller matematiskt när (b1 ≤ e2) OCH (b2 ≤ el).
Följande fråga sökte efter alla intervall som överlappar med intervallet (10, 30). Observera att det andra villkoret (b2 ≤ e1) vrids om till (e1 ≥ b2) för enklare avläsning (början och slutet av intervall från tabellen är alltid på vänstra sidan av villkoret). Det givna, eller det sökta intervallet, är i början av tidslinjen för alla intervall i tabellen.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);>
Frågan använde 36 logiska läsningar. Om du kontrollerar exekveringsplanen kan du se att frågan använde indexsöket i idx_b-indexet med sökpredikatet [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) och skanna sedan raderna och välj de resulterande raderna med hjälp av restpredikatet [tempdb].[dbo].[Intervaller].[e]>=(10). Eftersom det sökta intervallet är i början av tidslinjen, eliminerade sökpredikatet framgångsrikt majoriteten av raderna; endast ett fåtal intervall i tabellen har startpunkten lägre eller lika med 30.
Du skulle få en liknande effektiv fråga om det sökta intervallet skulle vara i slutet av tidslinjen, bara att SQL Server skulle använda idx_e-indexet för sökning. Men vad händer om det sökta intervallet är i mitten av tidslinjen, som följande fråga visar?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Den här gången använde frågan 111 logiska läsningar. Med en större tabell skulle skillnaden med den första frågan bli ännu större. Om du kontrollerar exekveringsplanen kan du ta reda på att SQL Server använde idx_e-indexet med [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) sökpredikat och [tempdb].[ dbo].[Intervaller].[b]<=(590) restpredikat. Sökpredikatet exkluderar ungefär hälften av raderna från ena sidan, medan hälften av raderna från den andra sidan skannas och resulterande rader extraheras med restpredikatet.
Förbättrad T-SQL-lösning
Det finns en lösning som skulle använda det indexet för att eliminera raderna från båda sidor av det sökta intervallet genom att använda ett enda index. Följande figur visar denna logik.
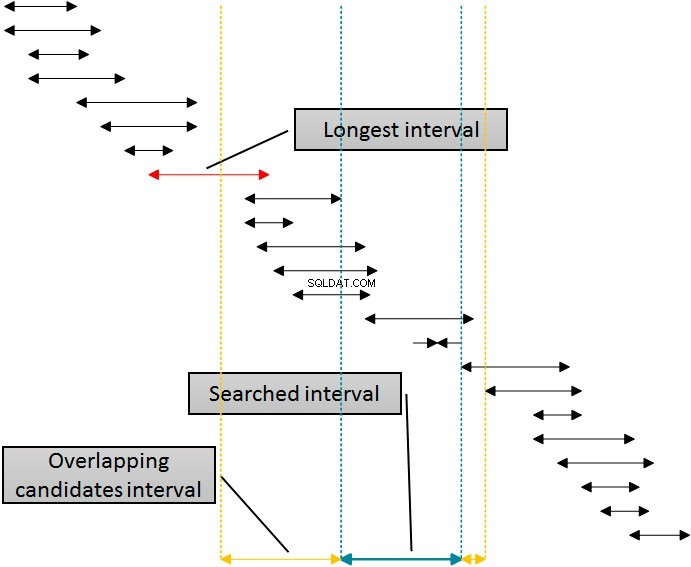
Intervallerna i figuren är sorterade efter den nedre gränsen, vilket representerar SQL Servers användning av idx_b-index. Att eliminera intervall från höger sida av det givna (sökta) intervallet är enkelt:eliminera bara alla intervall där början är minst en enhet större (mer till höger) av slutet av det givna intervallet. Du kan se denna gräns i figuren betecknad med den prickade linjen längst till höger. Att eliminera från vänster är dock mer komplicerat. För att kunna använda samma index, idx_b-indexet för att eliminera från vänster, måste jag använda början av intervallen i tabellen i WHERE-satsen i frågan. Jag måste gå till vänster sida bort från början av det givna (sökta) intervallet åtminstone för längden av det längsta intervallet i tabellen, som är markerat med en förklaring i figuren. Intervallerna som börjar före den vänstra gula linjen kan inte överlappa det givna (blåa) intervallet.
Eftersom jag redan vet att längden på det längsta intervallet är 20, kan jag skriva en utökad fråga på ett ganska enkelt sätt.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Denna fråga hämtar samma rader som den föregående med endast 20 logiska läsningar. Om du kontrollerar exekveringsplanen kan du se att idx_b användes, med sökpredikatet Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , Slut:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), som framgångsrikt eliminerade rader från båda sidor av tidslinjen, och sedan restpredikatet [tempdb].[dbo]. [Intervaller].[e]>=(570) OCH [tempdb].[dbo].[Intervaller].[e]<=(610) användes för att välja rader från en mycket begränsad partiell skanning.
Naturligtvis kan figuren vändas för att täcka de fall då idx_e-indexet skulle vara mer användbart. Med detta index är elimineringen från vänster enkel – eliminera alla intervaller som slutar minst en enhet före början av det givna intervallet. Den här gången är elimineringen från höger mer komplex – slutet av intervallen i tabellen kan inte vara mer till höger än slutet av det givna intervallet plus den maximala längden på alla intervaller i tabellen.
Observera att denna prestanda är en konsekvens av de specifika uppgifterna i tabellen. Den maximala längden på ett intervall är 20. På så sätt kan SQL Server mycket effektivt eliminera intervaller från båda sidor. Men om det bara skulle finnas ett långt intervall i tabellen skulle koden bli mycket mindre effektiv, eftersom SQL Server inte skulle kunna eliminera många rader från en sida, varken vänster eller höger, beroende på vilket index den skulle använda . Hur som helst, i verkligheten varierar intervalllängden inte mycket många gånger, så den här optimeringstekniken kan vara mycket användbar, särskilt för att den är enkel.
Slutsats
Observera att detta bara är en möjlig lösning. Du kan hitta en lösning som är mer komplex, men den ger förutsägbar prestanda oavsett längden på det längsta intervallet i Interval Queries in SQL Server-artikeln av Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-queries). Men jag gillar verkligen den förbättrade T-SQL lösning som jag presenterade i den här artikeln. Lösningen är väldigt enkel; allt du behöver göra är att lägga till två predikat till WHERE-satsen i dina överlappande frågor. Detta är dock inte slutet på möjligheterna. Håll utkik, i de kommande två artiklarna kommer jag att visa dig fler lösningar, så att du kommer att ha en mängd möjligheter i din optimeringsverktygslåda.
Användbart verktyg:
dbForge Query Builder för SQL Server – tillåter användare att snabbt och enkelt bygga komplexa SQL-frågor via ett intuitivt visuellt gränssnitt utan manuell kodskrivning.