Introduktion
Det finns två skolor för att utföra beräkningar i din databas:människor som tycker att det är bra och människor som har fel. Därmed inte sagt att världen av funktioner, lagrade procedurer, genererade eller beräknade kolumner och triggers bara är solsken och rosor! Dessa verktyg är långt ifrån idiotsäkra, och ogenomtänkta implementeringar kan fungera dåligt, traumatisera deras underhållare och mer, vilket i viss mån kan förklara förekomsten av kontroverser.
Men databaser är per definition väldigt bra på att bearbeta och manipulera information, och de flesta av dem gör samma kontroll och makt tillgänglig för sina användare (SQLite och MS Access i mindre grad). Externa databehandlingsprogram börjar på baksidan av att behöva dra information ur databasen, ofta över ett nätverk, innan de kan göra något. Och där databasprogram kan dra full nytta av inbyggda uppsättningsoperationer, indexering, tillfälliga tabeller och andra frukter av ett halvt sekel av databasutveckling, tenderar externa program av vilken komplexitet som helst att involvera en viss nivå av återuppfinning av hjul. Så varför inte få databasen att fungera?
Här är anledningen till att du kanske inte vill programmera din databas!
- Databasfunktioner har en tendens att bli osynliga – utlöser särskilt. Denna svaghet skalar ungefär med storleken på team och/eller applikationer som interagerar med databasen, eftersom färre personer kommer ihåg eller är medvetna om programmeringen i databasen. Dokumentation hjälper, men bara så mycket.
- SQL är ett språk som är specialbyggt för att manipulera datamängder. Den är inte särskilt bra på saker som inte manipulerar datamängder, och den är mindre bra ju mer komplicerad de andra sakerna blir.
- RDBMS-funktioner och SQL-dialekter skiljer sig åt. Enkla genererade kolumner stöds brett, men att portera mer komplex databaslogik till andra butiker tar minst tid och ansträngning.
- Uppgraderingar av databasscheman är vanligtvis mer krävande än programuppgraderingar. Snabbt föränderlig logik bibehålls bäst någon annanstans, även om det kan vara värt en ny titt när saker och ting har stabiliserats.
- Hantera databasprogram är inte så enkelt som man kan hoppas. Många schemamigreringsverktyg gör lite eller ingenting för organisationen, vilket leder till vidsträckta skillnader och betungande kodgranskningar (sqitchs beroendegrafer och omarbetning av enskilda objekt gör det till ett anmärkningsvärt undantag, och migra försöker kringgå problemet helt). Vid testning förbättras ramverk som pgTAP och utPLSQL på black-box-integreringstester men representerar också ett extra support- och underhållsåtagande.
- Med en etablerad extern kodbas tenderar alla strukturella förändringar att vara både ansträngningsintensiva och riskfyllda.
Å andra sidan, för de uppgifter som det lämpar sig för, erbjuder SQL snabbhet, koncision, hållbarhet och möjligheten att "kanonisera" automatiserade arbetsflöden. Datamodellering är mer än att fästa enheter som insekter på kartong, och skillnaden mellan data i rörelse och data i vila är svår. Vila är verkligen långsammare rörelser i finare grad; information flödar alltid härifrån och dit, och databasprogrammerbarhet är ett kraftfullt verktyg för att hantera och styra dessa flöden.
Vissa databasmotorer delar upp skillnaden mellan SQL och andra programmeringsspråk genom att även tillgodose de andra programmeringsspråken. SQL Server stöder funktioner skrivna i alla .NET Framework-språk; Oracle har lagrade Java-procedurer; PostgreSQL tillåter tillägg med C och är användarprogrammerbar i Python, Perl och Tcl, med plugins som lägger till skalskript, R, JavaScript och mer. Avrundar de vanliga misstänkta, det är SQL eller ingenting för MySQL och MariaDB, MS Access är endast programmerbar i VBA, och SQLite är inte alls användarprogrammerbar.
Att använda icke-SQL-språk är ett alternativ om SQL är otillräckligt för någon uppgift eller om du vill återanvända annan kod, men det kommer inte att komma runt de andra problem som gör databasprogrammering till ett mångeggat svärd. Om något, tillgripande av dessa komplicerar driftsättning och interoperabilitet ytterligare. Varning scriptor:låt författaren akta sig.
Funktioner kontra procedurer
Som med andra aspekter av att implementera SQL-standarden varierar de exakta detaljerna lite från RDBMS till RDBMS. I allmänhet:
- Funktioner kan inte kontrollera transaktioner.
- Funktioner returnerar värden; procedurer kan ändra parametrar betecknade
OUTellerINOUTsom sedan kan läsas i anropssammanhanget, men aldrig returnera ett resultat (undantaget SQL Server). - Funktioner anropas inifrån SQL-satser för att utföra en del arbete på poster som hämtas eller lagras, medan procedurer står ensamma.
Mer specifikt tillåter MySQL också rekursion och vissa ytterligare SQL-satser i funktioner. SQL Server förbjuder funktioner från att modifiera data, köra dynamisk SQL och hantera fel. PostgreSQL separerade inte lagrade procedurer från funktioner alls förrän 2017 med version 11, så Postgres-funktioner kan göra nästan allt som procedurer kan, med undantag för transaktionskontroll.
Så vilken ska man använda när? Funktioner är bäst lämpade för logik som tillämpar post för post när data lagras och hämtas. Mer komplexa arbetsflöden som anropas av dem själva och flyttar data internt är bättre som procedurer.
Standardinställningar och generation
Även enkla beräkningar kan göra problem om de utförs tillräckligt ofta eller om det finns flera konkurrerande implementeringar. Operationer på värden i en enda rad - tänk att konvertera mellan metriska och imperialistiska enheter, multiplicera en takt med arbetade timmar för fakturasubtotal, beräkna arean av en geografisk polygon - kan deklareras i en tabelldefinition för att lösa det ena eller det andra problemet :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
De flesta RDBMS erbjuder ett val mellan "lagrade" och "virtuella" genererade kolumner. I det förra fallet beräknas och lagras värdet när raden infogas eller uppdateras. Detta är det enda alternativet med PostgreSQL, från och med version 12, och MS Access. Virtuellt genererade kolumner beräknas när de efterfrågas som i vyer, så de tar inte upp utrymme utan kommer att räknas om oftare. Båda sorterna är hårt begränsade:värden kan inte bero på information utanför raden de tillhör, de kan inte uppdateras och individuella RDBMS kan ha ännu mer specifika begränsningar. PostgreSQL, till exempel, förbjuder partitionering av en tabell på en genererad kolumn.
Genererade kolumner är ett specialiserat verktyg. Allt som behövs är oftare ett standardvärde om ett värde inte anges på insatsen. Funktioner som now() visas ofta som kolumnstandard, men de flesta databaser tillåter anpassade såväl som inbyggda funktioner (förutom MySQL, där endast current_timestamp kan vara ett standardvärde).
Låt oss ta det ganska torra men enkla exemplet på ett partinummer i formatet YYYYXXX, där de fyra första siffrorna representerar det aktuella året och de tre sistnämnda en inkrementerande räknare:det första partiet som produceras i år är 2020001, det andra 2020002, och så vidare . Det finns ingen standardtyp eller inbyggd funktion som genererar ett värde som detta, men en användardefinierad funktion kan numrera varje lot
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Referera till data i funktioner
Sekvensmetoden ovan har en viktig svaghet (och lot_counter kommer fortfarande att ha samma värde som den gjorde den 31 december. Det finns mer än ett sätt att spåra hur många lotter som har skapats under ett år och genom att fråga lots självt next_lot_number funktion kan garantera ett korrekt värde efter att året har rullat över.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Arbetsflöden
Även en funktion med ett påstående har en avgörande fördel jämfört med extern kod:exekvering lämnar aldrig säkerheten för databasens ACID-garantier. Jämför next_lot_number ovan till möjligheterna med en klientapplikation eller till och med en manuell process, exekvering av
Program som lagras med flera påståenden öppnar upp ett enormt utrymme av möjligheter, eftersom SQL innehåller alla verktyg du behöver för att skriva procedurkod, från undantagshantering till räddningspunkter (det är till och med Turing komplett med fönsterfunktioner och vanliga tabelluttryck!). Hela arbetsflöden för databearbetning kan utföras i databasen, vilket minimerar exponeringen för andra delar av systemet och eliminerar tidskrävande rundresor mellan databasen och andra domäner.
Så mycket av programvaruarkitektur i allmänhet handlar om att hantera och isolera komplexitet, vilket förhindrar att den rinner över gränserna mellan delsystem. Om något mer eller mindre komplicerat arbetsflöde innebär att man drar in data till ett programs backend, skript eller cron-jobb, smälter och lägger till det och lagrar resultatet -- är det dags att fråga vad som verkligen kräver att man vågar sig utanför databasen.
Som nämnts ovan är detta ett område där skillnader mellan RDBMS-smaker och SQL-dialekter kommer i förgrunden. En funktion eller procedur som utvecklats för en databas kommer förmodligen inte att köras på en annan utan ändringar, oavsett om det ersätter SQL Servers TOP för en standard LIMIT klausul eller helt omarbeta hur temporärt tillstånd lagras i ett företag Oracle till PostgreSQL-migrering. Att kanonisera dina arbetsflöden i SQL förbinder dig också till din nuvarande plattform och dialekt mer grundligt än nästan alla andra val du kan göra.
Beräkningar i sökfrågor
Hittills har vi tittat på att använda funktioner för att lagra och modifiera data, oavsett om det är bunden till tabelldefinitioner eller hantera flertabellsarbetsflöden. I en mening är det den mer kraftfulla användningen som de kan användas till, men funktioner har också en plats i datahämtning. Många verktyg som du kanske redan använder i dina frågor är implementerade som funktioner, från standardinbyggda program som count till tillägg som Postgres jsonb_build_object , PostGIS' ST_SnapToGrid , och mer. Eftersom de är mer integrerade med själva databasen är de naturligtvis oftast skrivna på andra språk än SQL (t.ex. C i fallet med PostgreSQL och PostGIS).
Om du ofta finner dig själv (eller tror att du kan hitta dig själv) behöver hämta data och sedan utföra en operation på varje post innan det är på riktigt redo, överväg att omvandla dem på väg ut ur databasen istället! Projicerar du ett visst antal arbetsdagar från ett datum? Genererar en skillnad mellan två JSONB fält? Praktiskt taget alla beräkningar som bara beror på informationen du frågar kan göras i SQL. Och det som görs i databasen -- så länge som den har åtkomst konsekvent -- är kanoniskt när det gäller allt som är byggt ovanpå databasen.
Det måste sägas:om du arbetar med en applikationsbackend kan dess dataåtkomstverktygssats begränsa hur mycket körsträcka du får ut av att utöka frågeresultaten med funktioner. De flesta sådana bibliotek kan köra godtycklig SQL, men de som genererar vanliga SQL-satser baserade på modellklasser kan eller kanske inte tillåter anpassning av frågan SELECT listor. Genererade kolumner eller vyer kan vara ett svar här.
Triggers och konsekvenser
Funktioner och procedurer är tillräckligt kontroversiella bland databasdesigners och användare, men saker egentligen ta av med triggers. En utlösare definierar en automatisk åtgärd, vanligtvis en procedur (SQLite tillåter endast en enstaka sats), som ska exekveras före, efter eller istället för en annan åtgärd.
Den initierande åtgärden är vanligtvis en infogning, uppdatering eller borttagning av en tabell, och triggerproceduren kan vanligtvis ställas in för att utföras antingen för varje post eller för satsen som helhet. SQL Server tillåter också triggers på uppdateringsbara vyer, mest som ett sätt att genomdriva mer detaljerade säkerhetsåtgärder; och det, PostgreSQL och Oracle erbjuder alla någon form av händelse eller
En vanlig lågriskanvändning för triggers är som en extra kraftfull begränsning som förhindrar att ogiltiga data lagras. I alla större relationsdatabaser, endast primära och främmande nycklar och UNIQUE begränsningar kan utvärdera information utanför kandidatposten. Det är inte möjligt att i en tabelldefinition deklarera att till exempel bara två lotter kan skapas på en månad -- och den enklaste databas-och-kodlösningen är sårbar för ett liknande rastillstånd som count-sedan-set-metoden för lot_number ovan. För att upprätthålla andra begränsningar som involverar hela tabellen, eller andra tabeller, behöver du en
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
När du börjar köra lots i sig kan vara den sista operationen av en trigger som initieras av en infogning i orders , utan mänsklig användare eller applikationsbackend som har rätt att skriva till lots direkt. Eller som items läggs till många, kan en trigger där hantera uppdatering av current_quantity , och starta någon annan process när den når target_quantity .
Triggers och funktioner kan köras på åtkomstnivån för deras definierare (i PostgreSQL, en SECURITY DEFINER deklaration bredvid en funktions LANGUAGE ), vilket ger annars begränsade användare makten att initiera mer omfattande processer -- och gör det ännu viktigare att validera och testa dessa processer.
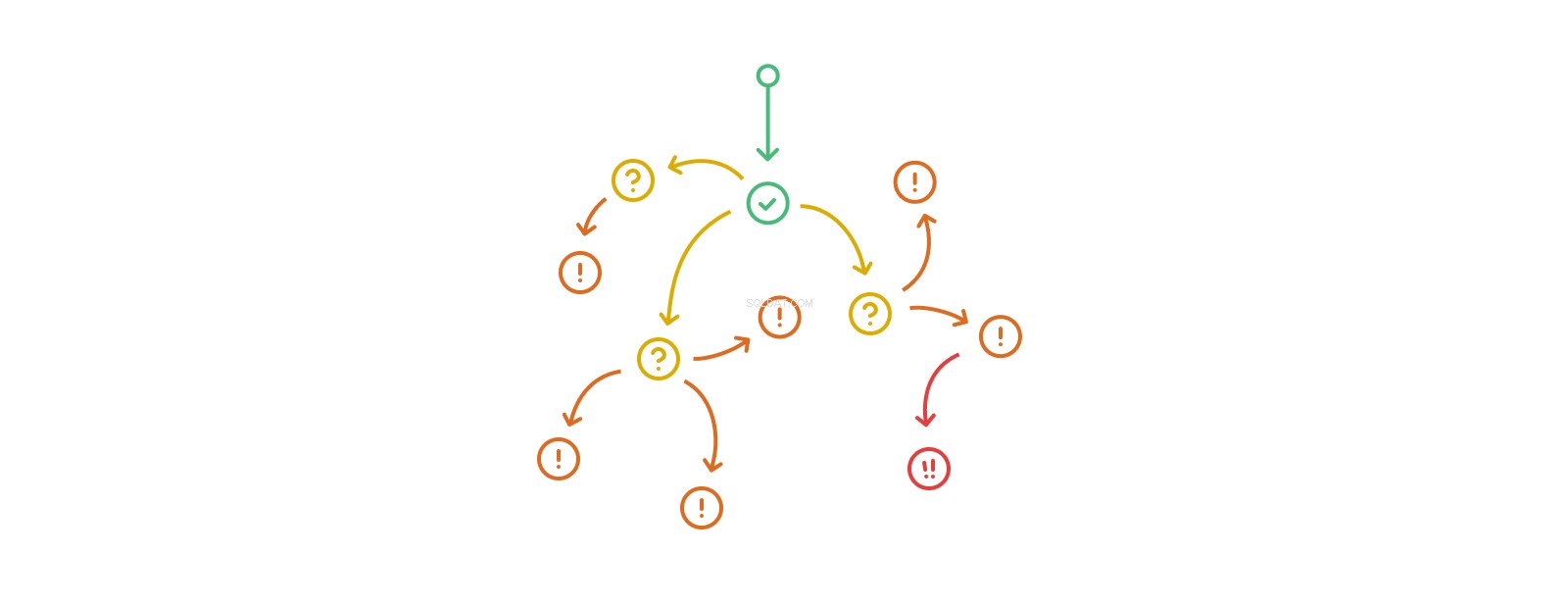
Anropsstacken trigger-action-trigger-action kan bli godtyckligt lång, även om sann rekursion i form av att modifiera samma tabeller eller poster flera gånger i ett sådant flöde är olagligt på vissa plattformar och mer allmänt en dålig idé under nästan alla omständigheter. Triggerhäckning överträffar snabbt vår förmåga att förstå dess omfattning och effekter. Databaser som i hög grad använder kapslade utlösare börjar glida från det komplicerade till det komplexa, och blir svåra eller omöjliga att analysera, felsöka och förutsäga.
Praktisk programmerbarhet
Beräkningar i databasen är inte bara snabbare och mer koncist uttryckta:de eliminerar oklarheter och sätter standarder. Exemplen ovan frigör databasanvändare från att behöva beräkna lotnummer själva, eller från oro över att av misstag skapa fler lotter än de kan hantera. Särskilt applikationsutvecklare har ofta tränats i att tänka på databaser som "dum lagring", endast tillhandahåller struktur och uthållighet, och kan därmed finna sig själva - eller ännu värre, inte inse att de - klumpigt artikulerar utanför databasen vad de skulle kunna göra mer effektivt i SQL.
Programmerbarhet är en orättvist förbisedd egenskap hos relationsdatabaser. Det finns skäl att undvika det och mer för att begränsa dess användning, men funktioner, procedurer och triggers är alla kraftfulla verktyg för att begränsa komplexiteten som din datamodell ålägger systemen där den är inbäddad.