Det finns ingen relevant hårdkodad gräns (65 536 * Nätverkspaketstorlek på 4KB är 268 MB och din skriptlängd är inte i närheten av det) även om det inte är tillrådligt att använda den här metoden för ett stort antal rader.
Felet du ser orsakas av klientverktygen, inte SQL Server. Om du konstruerar SQL-strängen i dynamisk SQL-kompilering kan åtminstone starta framgångsrikt
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Även om jag dödade ovanstående efter ~30 minuters kompileringstid och det fortfarande inte hade producerat en rad. De bokstavliga värdena måste lagras i själva planen som en tabell med konstanter och SQL Server spenderar mycket tid försöker härleda egenskaper om dem också.
SSMS är ett 32-bitars program och skickar en std::bad_alloc undantag vid analys av batchen
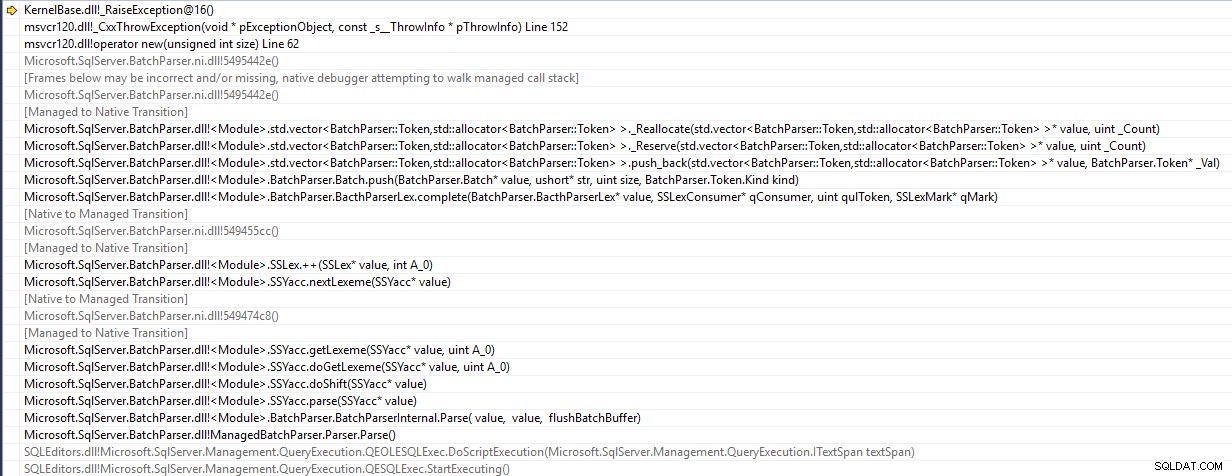
Den försöker trycka in ett element på en vektor av Token som har nått kapacitet och dess försök att ändra storlek misslyckas på grund av att ett tillräckligt stort angränsande minnesområde inte är tillgängligt. Så uttalandet når det aldrig ens så långt som servern.
Vektorkapaciteten växer med 50 % varje gång (dvs. följer sekvensen här ). Kapaciteten som vektorn behöver växa till beror på hur koden är upplagd.
Följande behöver växa från en kapacitet på 19 till 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
och följande behöver bara storleken 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Följande behöver en kapacitet på> 63 och <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
För en miljon rader utlagda som i fall 1 måste vektorkapaciteten växa till 3 543 306.
Du kanske upptäcker att något av följande kommer att tillåta analysen på klientsidan att lyckas.
- Minska antalet radbrytningar.
- Startar om SSMS i hopp om att begäran om stort sammanhängande minne lyckas när det finns mindre fragmentering av adressutrymmet.
Men även om du lyckas skicka den till servern kommer det bara att döda servern under generering av exekveringsplanen, som diskuterats ovan.
Du kommer att bli mycket bättre av att använda importexportguiden för att ladda tabellen. Om du måste göra det i TSQL kommer du att upptäcka att dela upp det i mindre partier och/eller att använda en annan metod som att strimla XML kommer att prestera bättre än Table Valued Constructors. Följande körs på 13 sekunder på min dator till exempel (men om du använder SSMS måste du förmodligen dela upp i flera batcher istället för att klistra in en massiv XML-sträng bokstavligen).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)