
SQL Server-index används för att hjälpa till att hämta data snabbare och minska flaskhalsar som påverkar kritiska resurser. Index på en databastabell fungerar som en prestandaoptimeringsteknik. Du kanske undrar – hur ökar index frågeprestanda? Finns det saker som bra och dåliga index? Anta att du har en tabell med 50 kolumner, är det en bra idé att skapa index på var och en av kolumnerna? Om vi skapar flera index, hjälper det SQL-frågor att köras snabbare?
Alla fantastiska frågor, men innan vi dyker in är det viktigt att veta varför index kan behövas i första hand.
Föreställ dig att du besöker ett stadsbibliotek som har en samling på tusentals böcker. Du letar efter en specifik bok, men hur hittar du den? Om du gick igenom varje bok, i varje ställ, kan det ta dagar att hitta den. Detsamma gäller för en databas när du letar efter en post från de miljontals rader som finns lagrade i en tabell.
Ett SQL Server-index är format i ett B-Tree-format som består av en rotnod överst och lövnod längst ned. För vårt exempel på biblioteksböcker utfärdar en användare en fråga för att söka efter en bok med ID 391. I det här fallet börjar frågemotorn gå från rotnoden och flyttar till bladnoden.
Root Node –> Mellanliggande nod –> Bladnod.
Frågemotorn letar efter referenssidan på mellannivån. I det här exemplet består den första mellannoden av bok-ID:n från 1-500 och den andra mellannoden består av 501-1000.
Baserat på den mellanliggande noden, går frågemotorn genom B-trädet för att leta efter motsvarande mellannod och bladnoden. Denna bladnod kan bestå av faktiska data eller peka på den faktiska datasidan baserat på indextypen. I bilden nedan ser vi hur man går igenom indexet för att leta efter data med hjälp av SQL Server-index. I det här fallet behöver SQL Server inte gå igenom varje sida, läsa den och leta efter ett specifikt bok-ID-innehåll.
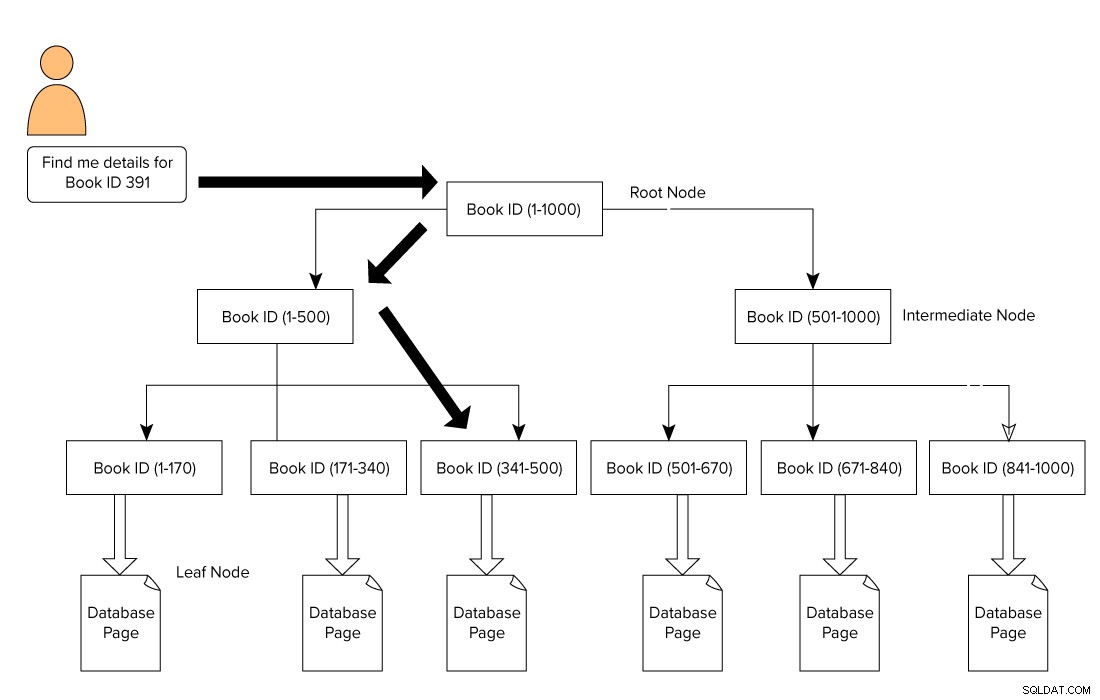
Inverkan av index på SQL Server-prestanda
I det tidigare biblioteksexemplet undersökte vi de potentiella effekterna av indexprestanda. Låt oss titta på frågeprestanda med och utan ett index.
Anta att vi kräver data för [SalesOrderID] 56958 från tabellen [SalesOrderDetail_Demo].
VÄLJ *
FRÅN [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
där SalesOrderID=56958
Den här tabellen har inga index. En tabell utan några index kallas en heap-tabell i SQL Server.
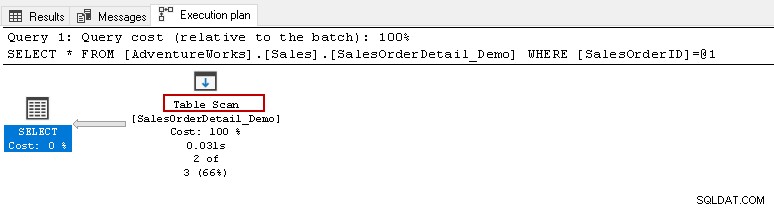
Härifrån skulle du vilja köra ovanstående select-sats och se den faktiska exekveringsplanen. Den här tabellen har 121317 poster. Den utför en tabellsökning, vilket innebär att den läser alla rader i en tabell för att hitta det specifika [SalesOrderID].
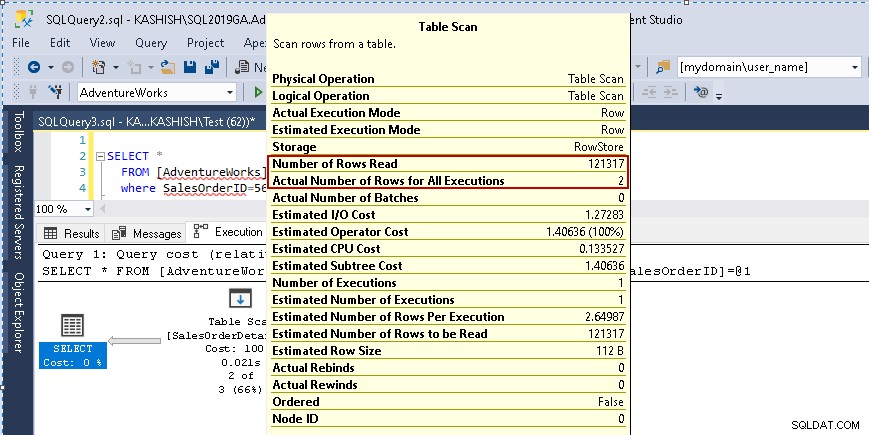
När du håller muspekaren över ikonen Tabellsökning visar den att den faktiska resultatuppsättningen innehåller 2 rader, men för detta ändamål läser den alla rader i den tabellen.
- Antal lästa rader:121317
- Det faktiska antalet rader för körningen:2
Tänk nu på en tabell med miljoner eller miljarder rader. Det är inte bra att gå igenom alla poster i tabellen för att filtrera några rader. I ett omfattande databassystem för onlinetransaktionsbehandling (OLTP) använder det inte serverresurser (CPU, IO, minne) effektivt, därför kan användaren få prestandaproblem.
Låt oss nu köra ovanstående select-sats med tabellen med index. Den här tabellen har ett klustrat primärnyckelindex och två icke-klustrade index på kolumnerna [ProductID] och [rowguid]. Vi kommer att prata senare om de olika typerna av index i SQL Server.
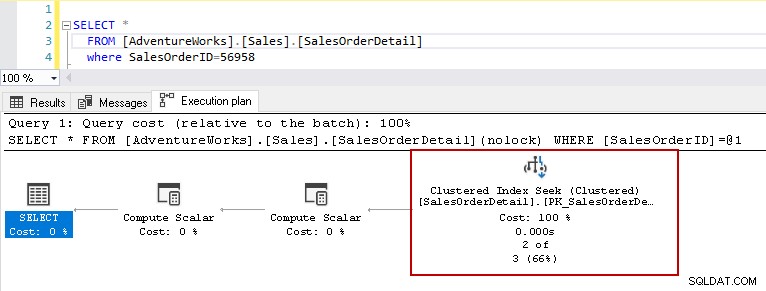
Om du nu kör select-satsen igen med samma predikat visar exekveringsplanen prestandaproblemet. Frågeoptimeraren bestämmer sig för att använda klustrad indexsökning istället för en klustrad indexsökning.
I den klustrade indexsökningsinformationen visar den frågeoptimeraren exakt läsa raderna den gav i utdata.
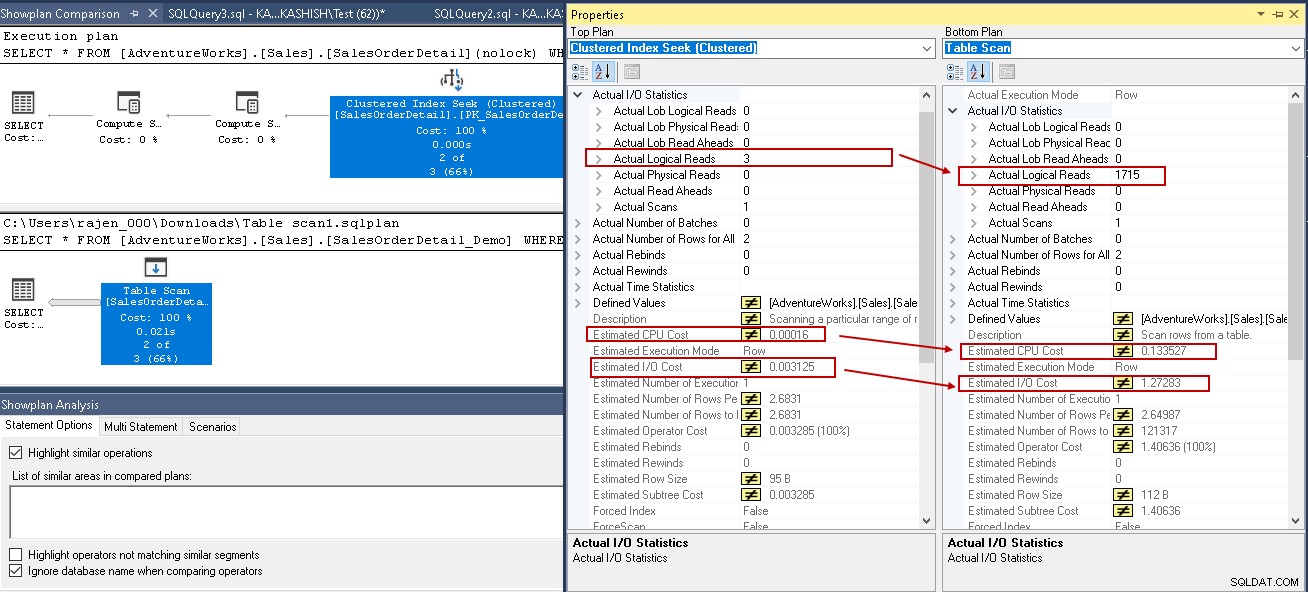
För att ge dig en jämförande analys, låt oss jämföra exekveringsplanen med och utan ett SQL Server-index. Du kan hänvisa till SQL Shacks How to compare query execution plans i SQL Server 2016 artikel för ytterligare insikter.
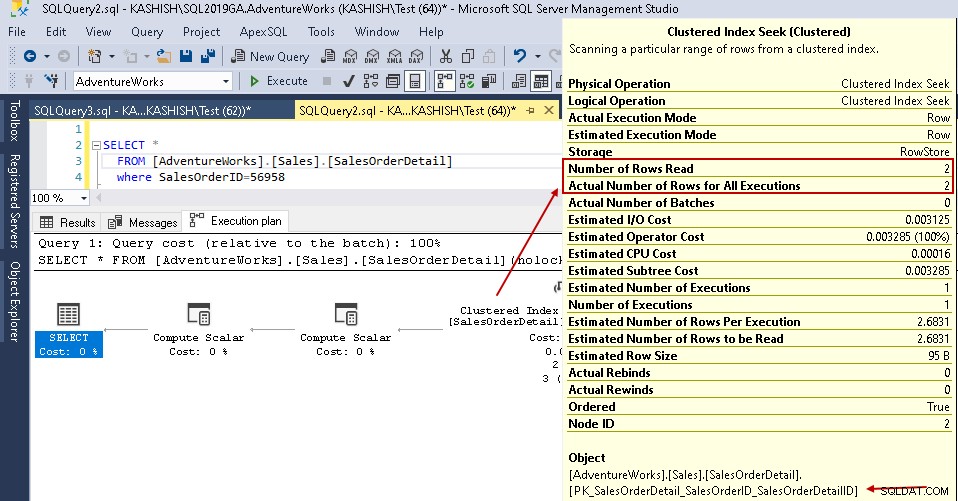
För det här exemplet, titta på de markerade värdena i den klustrade indexsökningen och tabellskanningen:
- Logiska läsningar:SQL Server-databasmotorn läser en sida från buffertcachen och den orsakar en logisk läsning. Nedan ser vi att logiska läsningar reduceras från 1715 till 3 när du väl har skapat indexet.
- Uppskattad CPU-kostnad sjunker också från 0,133527 till 0,00016
- Uppskattade IO-kostnader sjunker från 1,27283 till 0,003125
Bilden nedan visar skillnaden mellan en tabellsökning och en indexsökning.
Bra (användbara) index och dåliga index i SQL Server
Som namnet antyder förbättrar ett bra index frågeprestanda och minimerar resursutnyttjandet. Kan ett index minska prestandan för frågor i SQL Server? Ibland skapar vi indexet på en specifik kolumn, men det används aldrig. Anta att du har ett index på en kolumn och du utför många infogningar och uppdateringar för den kolumnen. För varje uppdatering krävs också motsvarande indexuppdatering. Om din arbetsbelastning har mer skrivaktivitet och du har många index på en kolumn, skulle det sakta ner den övergripande prestandan för dina frågor. Ett oanvänt index kan också orsaka långsam prestanda för utvalda uttalanden. Frågeoptimeraren använder statistik för att skapa en exekveringsplan. Den läser alla index och deras datasampling, och baserat på det bygger den en optimerad frågeexekveringsplan. Du kan spåra din indexanvändning med hjälp av den dynamiska hanteringsvyn sys.dm_db_index_usage_stats och övervaka resurserna, som användargenomsökning, användarsökningar och användarsökningar.
SQL Server indextyper och överväganden
SQL Server har två huvudindex – klustrade och icke-klustrade index. Ett klustrat index lagrar faktiska data i indexets bladnod. Den sorterar fysiskt data inom datasidorna baserat på den klustrade indexnyckeln. SQL Server tillåter ett klustrat index per tabell. Du kan sammanfoga flera kolumner för att bygga en klustrad indexnyckel. Ett icke-klustrat index är ett logiskt index, och det har indexnyckelkolumnen som pekar på den klustrade indexnyckeln.
Vi kan också ha andra index i SQL Server som XML-index, kolumnlagerindex, rumsligt index, fulltextindex, hashindex, etc.
Du bör överväga följande punkter innan du bygger ett index i SQL Server:
- Arbetsbelastning
- Kolumnen där indexet krävs
- Bordstorlek
- Stigande eller fallande ordning för kolumndata
- Kolumnordning
- Indextyp
- Fyllningsfaktor, padindex och TempDB-sorteringsordning
SQL Server-indexfördelar, implikationer och rekommendationer
Index i en databas kan vara ett tveeggat svärd. Ett användbart SQL Server-index förbättrar frågan och systemets prestanda utan att påverka de andra frågorna. Å andra sidan, om du skapar ett index utan några förberedelser eller överväganden, kan det orsaka prestandaförsämringar, långsam datahämtning och kan förbruka mer kritiska resurser som CPU, IO och minne. Index ökar också dina databasunderhållsuppgifter. Med dessa faktorer i åtanke är det alltid bäst att testa ett lämpligt index i en förproduktionsmiljö med motsvarande produktionsbelastning, sedan analysera prestanda och bestämma om det är bäst att implementera det i en produktionsdatabas. Det finns många fler rekommendationer att ta hänsyn till. Kolla in mina bästa 11 bästa metoder för index för ytterligare insikt.