
Begränsningar i SQL Server är fördefinierade regler som du kan tillämpa på enstaka eller flera kolumner. Dessa begränsningar hjälper till att upprätthålla integriteten, tillförlitligheten och noggrannheten hos värden som lagras i dessa kolumner. Du kan skapa begränsningar med CREATE TABLE eller ALTER Table-satser. Om du använder ALTER TABLE-satsen kommer SQL Server att kontrollera befintlig kolumndata innan begränsningen skapas.
Om du infogar data i kolumnen som uppfyller villkorsregelkriterierna, infogar SQL Server data framgångsrikt. Men om data bryter mot begränsningen, avbryts insert-satsen med ett felmeddelande.
Tänk till exempel att du har en [Anställd]-tabell som lagrar din organisations personaldata, inklusive deras lön. Det finns några tumregler när det kommer till värden i lönespalten.
- Kolumnen kan inte ha negativa värden som -10 000 eller -15 000 USD.
- Du vill också ange det maximala lönevärdet. Till exempel bör den maximala lönen vara mindre än 2 000 000 USD.
Om du infogar en ny post med en begränsning på plats kommer SQL Server att validera värdet mot de definierade reglerna.
Infogat värde:
Lön 80 000:Insatt framgångsrikt
Lön -50 000: Fel
Vi kommer att utforska följande begränsningar i SQL Server i den här artikeln.
- INTE NULL
- UNIKT
- KONTROLLERA
- PRIMÄRNYCKEL
- UTLANDSNYCKEL
- STANDARD
INTE NULL-begränsning
Som standard tillåter SQL Server lagring av NULL-värden i kolumner. Dessa NULL-värden representerar inte giltiga data.
Till exempel måste varje anställd i en organisation ha ett Emp ID, förnamn, kön och adress. Därför kan du ange en kolumn med NOT NULL-begränsningar för att alltid säkerställa giltiga värden.
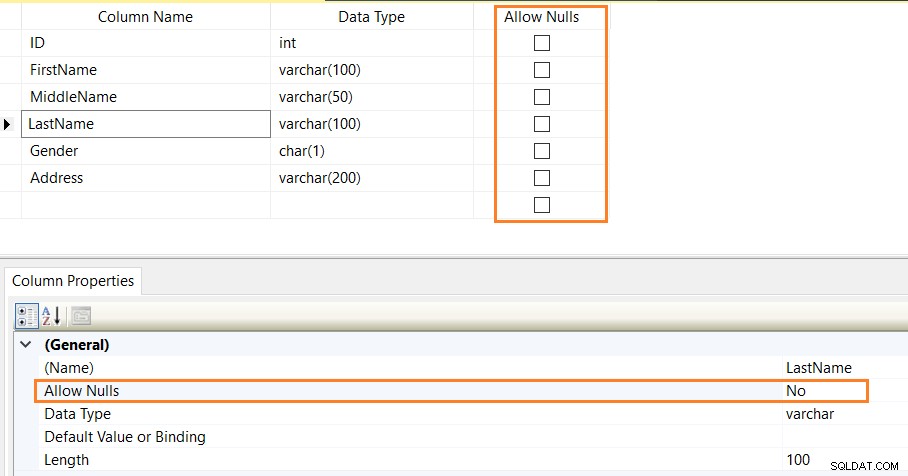
Skriptet CREATE TABLE nedan definierar NOT NULL-begränsningar för kolumnerna [ID],[FirstName],[LastName],[Gender] och [Address].
CREATE TABLE Employees ( ID INT NOT NULL, [FirstName] Varchar(100) NOT NULL, [MiddleName] Varchar(50) NULL, [LastName] Varchar(100) NOT NULL, [Gender] char(1) NOT NULL, [Address] Varchar(200) NOT NULL )
För att validera NOT NULL-begränsningarna, beteendet, använder vi följande INSERT-satser.
- Infoga värden för alla kolumner (NULL och NOT NULL) – Infogar framgångsrikt
INSERT INTO Employees (ID,[FirstName],[MiddleName],[LastName],[gender],[Address]) VALUES(1,'Raj','','Gupta','M','India')
- Infoga värden för kolumner med NOT NULL-egenskapen – Infogar framgångsrikt
INSERT INTO Employees (ID,[FirstName],[LastName],[gender],[Address]) VALUES(2, 'Shyam','Agarwal','M','UK')
- Hoppa över infogning av värden för kolumnen [Efternamn] med NOT NULL-begränsningar – Fails+
INSERT INTO Employees (ID,[FirstName],[gender],[Address]) VALUES(3,'Sneha','F','India')
Den senaste INSERT-satsen gav upphov till felet – Kan inte infoga NULL-värden i kolumnen .

Den här tabellen har följande värden infogade i tabellen [Anställda].
Anta att vi inte kräver NULL-värden i kolumnen [MiddleName] enligt HR-kraven. För detta ändamål kan du använda ALTER TABLE-satsen.
ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Denna ALTER TABLE-sats misslyckas på grund av de befintliga värdena i kolumnen [MiddleName]. För att upprätthålla begränsningen måste du eliminera dessa NULL-värden och sedan köra ALTER-satsen.
UPDATE Employees SET [MiddleName]='' WHERE [MiddleName] IS NULL Go ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Du kan också validera NOT NULL-begränsningarna med hjälp av SSMS-tabelldesignern.
UNIK begränsning
Den UNIKA begränsningen i SQL Server säkerställer att du inte har dubbletter av värden i en enda kolumn eller kombination av kolumner. Dessa kolumner bör vara en del av de UNIKA begränsningarna. SQL Server skapar automatiskt ett index när UNIKA begränsningar definieras. Du kan bara ha ett unikt värde i kolumnen (inklusive NULL).
Till exempel, skapa [DemoTable] med [ID]-kolumnen med UNIK begränsning.
CREATE TABLE DemoTable ( [ID] INT UNIQUE NOT NULL, [EmpName] VARCHAR(50) NOT NULL )
Expandera sedan tabellen i SSMS och du har ett unikt index (icke-klustrade), som visas nedan.
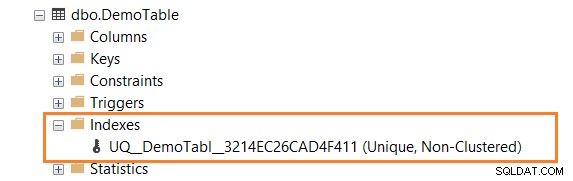
Vänligen högerklicka på indexet och generera dess skript. Som visas nedan använder den ADD UNIQUE NOCLUSTERED nyckelordet för begränsningen.

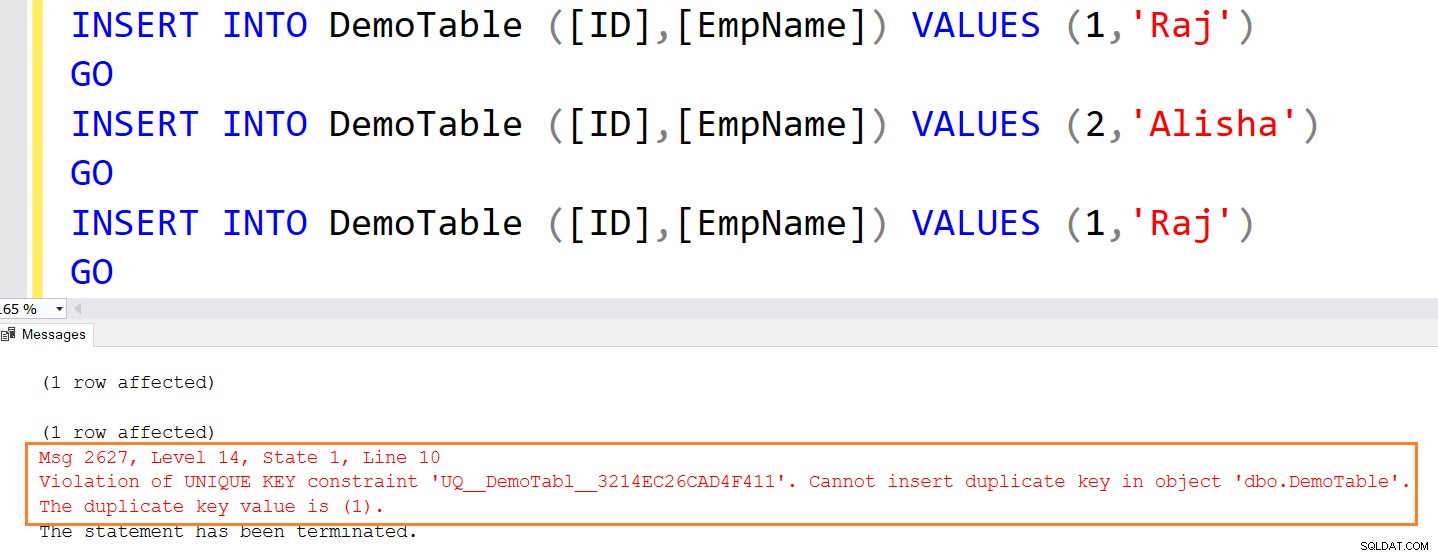
Följande insert-sats ger ett fel eftersom den försöker infoga dubbletter av värden.
INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (2,'Alisha') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO
Kontrollera begränsning
CHECK-begränsningen i SQL Server definierar ett giltigt värdeintervall som kan infogas i specificerade kolumner. Den utvärderar varje infogat eller modifierat värde, och om det är uppfyllt slutförs SQL-satsen framgångsrikt.
Följande SQL-skript sätter en begränsning för kolumnen [Ålder]. Dess värde bör vara större än 18 år.
CREATE TABLE DemoCheckConstraint ( ID INT PRIMARY KEY, [EmpName] VARCHAR(50) NULL, [Age] INT CHECK (Age>18) ) GO
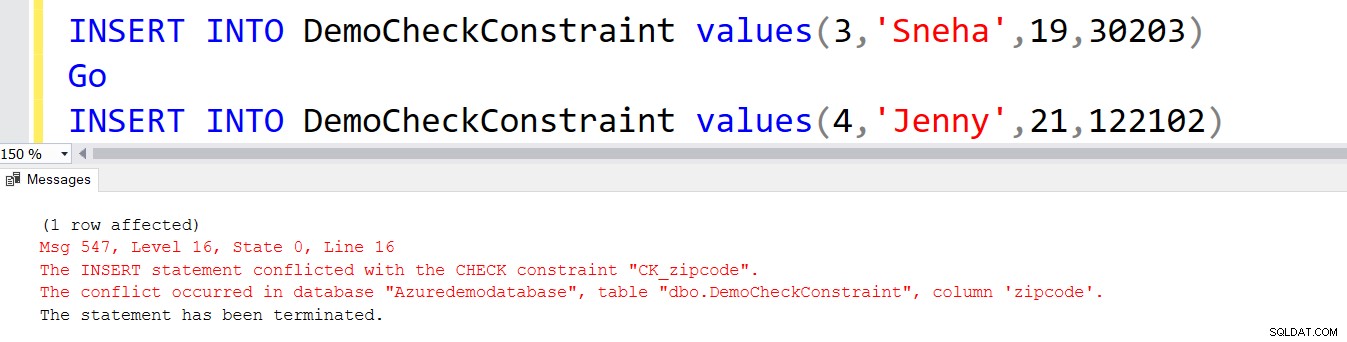
Låt oss infoga två poster i den här tabellen. Frågan infogar den första posten.
INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (1,'Raj',20) Go INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (2,'Sohan',17) GO
Den andra INSERT-satsen misslyckas eftersom den inte uppfyller villkoret CHECK.
Ett annat användningsfall för CHECK-begränsningen är att lagra giltiga värden för postnummer. I skriptet nedan lägger vi till en ny kolumn [ZipCode] och den använder CHECK-begränsningen för att validera värdena.
ALTER TABLE DemoCheckConstraint ADD zipcode int
GO
ALTER TABLE DemoCheckConstraint
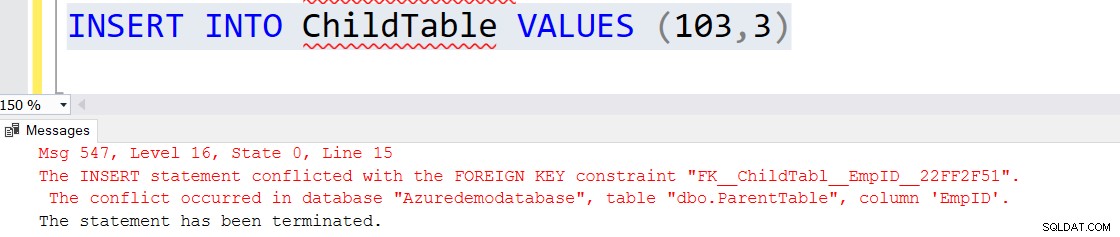
ADD CONSTRAINT CK_zipcode CHECK (zipcode LIKE REPLICATE ('[0-9]', 5)) Denna CHECK-begränsning tillåter inte ogiltiga postnummer. Till exempel genererar den andra INSERT-satsen ett fel.
INSERT INTO DemoCheckConstraint values(3,'Sneha',19,30203) Go INSERT INTO DemoCheckConstraint values(4,'Jenny',21,122102)
PRIMÄR NYCKEL begränsning
PRIMARY KEY-begränsningen i SQL Server är ett populärt val bland databasproffs för att implementera unika värden i en relationstabell. Den kombinerar UNIKA och INTE NULL-begränsningar. SQL Server skapar automatiskt ett klustrat index när vi definierar en PRIMARY KEY-begränsning. Du kan använda en enstaka kolumn eller en uppsättning kombinationer för att definiera unika värden i en rad.
Dess primära syfte är att framtvinga tabellens integritet med hjälp av den unika enheten eller kolumnvärdet.
Den liknar den UNIKA begränsningen med följande skillnader.
| PRIMÄRNYCKEL | UNIKK NYCKEL |
| Den använder en unik identifierare för varje rad i en tabell. | Det definierar unikt värden i en tabellkolumn. |
| Du kan inte infoga NULL-värden i kolumnen PRIMARY KEY. | Den kan acceptera ett NULL-värde i den unika nyckelkolumnen. |
| En tabell kan endast ha en PRIMÄRNYCKEL-begränsning. | Du kan skapa flera UNIKA KEY-begränsningar i SQL Server. |
| Som standard skapar den ett klustrat index för PRIMARY KEY-kolumnerna. | Den UNIK NYCKEL skapar ett icke-klustrat index för primärnyckelkolumnerna. |
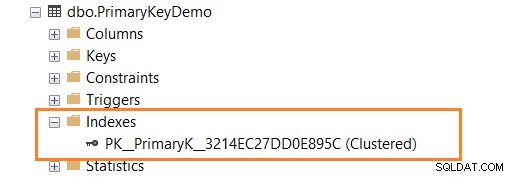
Följande skript definierar PRIMÄRNYCKLEN i ID-kolumnen.
CREATE TABLE PrimaryKeyDemo ( ID INT PRIMARY KEY, [Name] VARCHAR(100) NULL )
Som visas nedan har du ett klustrat nyckelindex efter att ha definierat PRIMÄRNYCKLEN i ID-kolumnen.
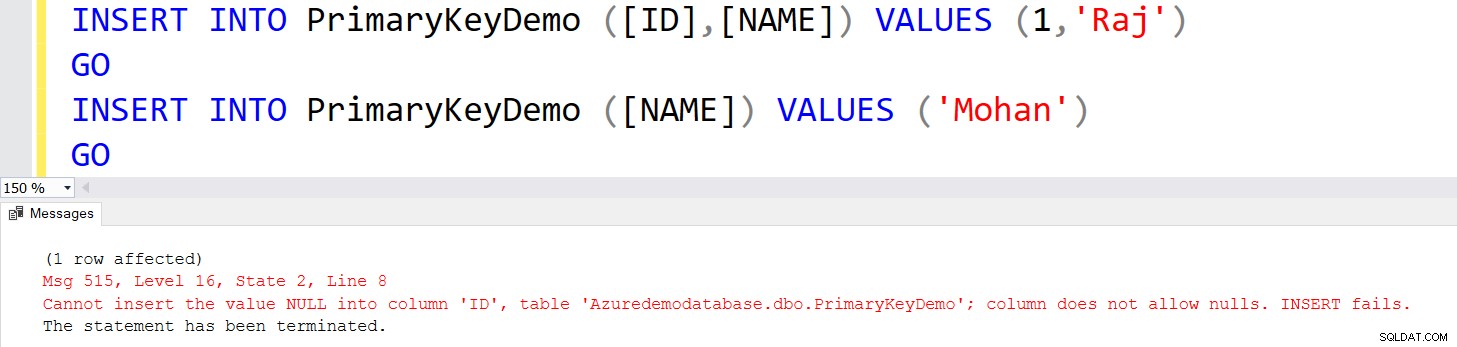
Låt oss infoga posterna i tabellen [PrimaryKeyDemo] med följande INSERT-satser.
INSERT INTO PrimaryKeyDemo ([ID],[NAME]) VALUES (1,'Raj')
GO
INSERT INTO PrimaryKeyDemo ([NAME]) VALUES ('Mohan')
GO Du får ett fel i den andra INSERT-satsen eftersom den försöker infoga NULL-värdet.
På samma sätt, om du försöker infoga dubbletter av värden, får du följande felmeddelande.

FREIGN KEY-begränsning
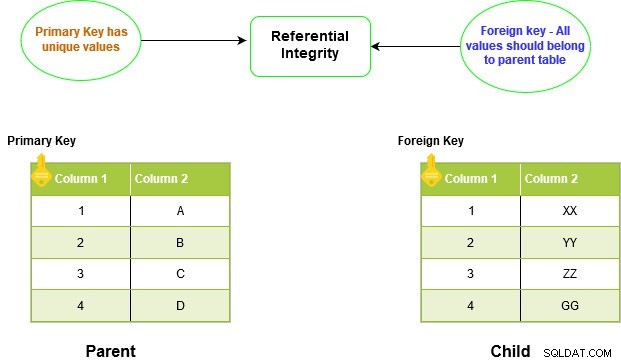
FOREIGN KEY-begränsningen i SQL Server skapar relationer mellan två tabeller. Detta förhållande är känt som förälder-barn-relationen. Den upprätthåller referensintegritet i SQL Server.
Den underordnade tabellens främmande nyckel bör ha en motsvarande post i kolumnen för den överordnade primärnyckeln. Du kan inte infoga värden i den underordnade tabellen utan att först infoga den i den överordnade tabellen. På samma sätt måste vi först ta bort värdet från den underordnade tabellen innan det kan tas bort från den överordnade tabellen.
Eftersom vi inte kan ha dubbletter av värden i PRIMARY KEY-begränsningen tillåter den inte dubbletter eller NULL i den underordnade tabellen också.
Följande SQL-skript skapar en överordnad tabell med en primärnyckel och en underordnad tabell med en primär och främmande nyckelreferens till kolumnen [EmpID] för överordnad tabell.
CREATE TABLE ParentTable ( [EmpID] INT PRIMARY KEY, [Name] VARCHAR(50) NULL ) GO CREATE TABLE ChildTable ( [ID] INT PRIMARY KEY, [EmpID] INT FOREIGN KEY REFERENCES ParentTable(EmpID) )
Infoga poster i båda tabellerna. Observera att den underordnade tabellens främmande nyckelvärde har en post i den överordnade tabellen.
INSERT INTO ParentTable VALUES (1,'Raj'),(2,'Komal') INSERT INTO ChildTable VALUES (101,1),(102,2)
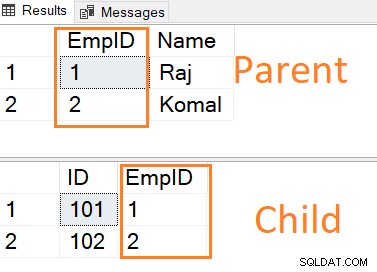
Om du försöker infoga en post direkt i den underordnade tabellen som inte refererar till den överordnade tabellens primärnyckel får du följande felmeddelande.
STANDARD-begränsning
DEFAULT-begränsningen i SQL Server tillhandahåller standardvärdet för en kolumn. Om vi inte anger ett värde i INSERT-satsen för kolumnen med DEFAULT-begränsningen, använder SQL Server sitt tilldelade standardvärde. Anta till exempel att en ordertabell har poster för alla kundorder. Du kan använda funktionen GETDATE() för att fånga beställningsdatumet utan att ange något explicit värde.
CREATE TABLE Orders ( [OrderID] INT PRIMARY KEY, [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() ) GO
För att infoga posterna i den här tabellen kan vi hoppa över att tilldela värden för kolumnen [OrderDate].
INSERT INTO Orders([OrderID]) values (1) GO
VÄLJ * FRÅN Beställningar 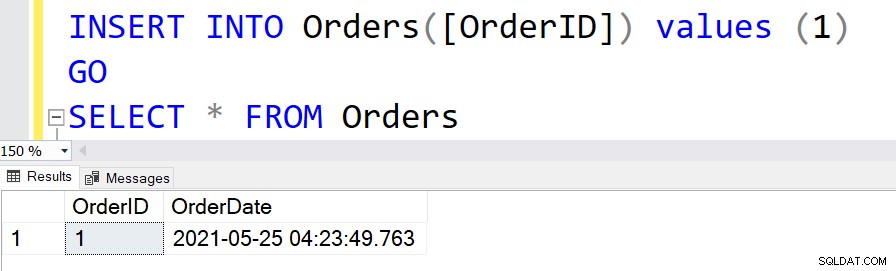
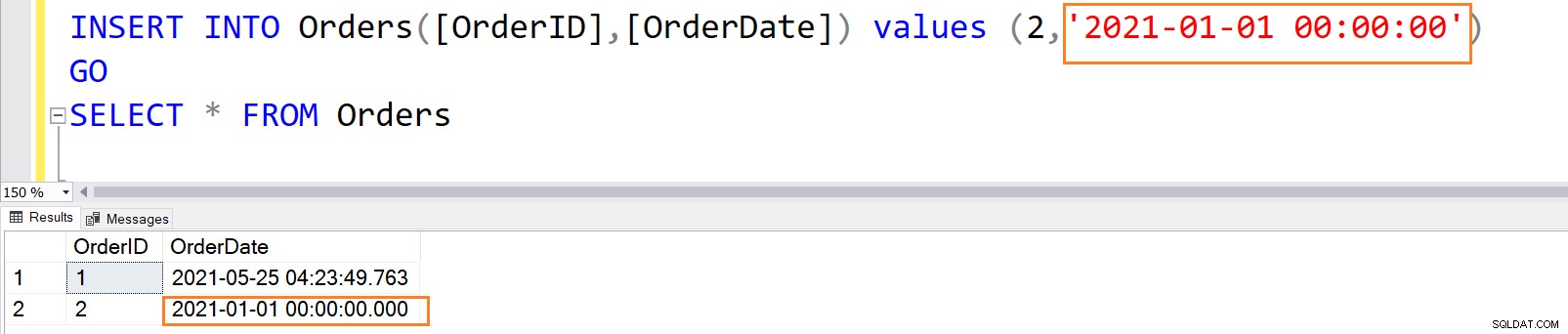
När kolumnen DEFAULT-begränsning anger ett explicit värde, lagrar SQL Server detta explicita värde istället för standardvärdet.
Begränsningsfördelar
Begränsningarna i SQL Server kan vara fördelaktiga i följande fall:
- Tillämpa affärslogik
- Att upprätthålla referensintegritet
- Förhindra lagring av felaktig data i SQL Server-tabeller
- Tillämpa unikhet för kolumndata
- Förbättra frågeprestanda eftersom frågeoptimeraren är medveten om unika data och validerar uppsättningar värden
- Förhindra lagring av NULL-värden i SQL-tabeller
- Skriv koder för att undvika NULL när data visas i programmet