För länge sedan svarade jag på en fråga om NULL på Stack Exchange med titeln "Varför skulle vi inte tillåta NULL?" Jag har min andel av sällskapsdjur och passioner, och rädslan för NULLs är ganska högt upp på min lista. En kollega sa nyligen till mig, efter att ha uttryckt en preferens att tvinga fram en tom sträng istället för att tillåta NULL:
"Jag gillar inte att hantera nollor i kod."
Jag är ledsen, men det är ingen bra anledning. Hur presentationslagret hanterar tomma strängar eller NULLs bör inte vara drivrutinen för din tabelldesign och datamodell. Och om du tillåter en "brist på värde" i någon kolumn, spelar det någon roll för dig från en logisk synvinkel om "brist på värde" representeras av en noll-längd sträng eller en NULL? Eller ännu värre, ett symbolvärde som 0 eller -1 för heltal, eller 1900-01-01 för datum?
Itzik Ben-Gan skrev nyligen en hel serie om NULLs, och jag rekommenderar starkt att gå igenom det hela:
- NULL-komplexitet – del 1
- NULL-komplexitet – del 2
- NULL-komplexiteter – Del 3, Saknade standardfunktioner och T-SQL-alternativ
- NULL-komplexiteter – Del 4, Saknar unik standardbegränsning
Men mitt mål här är lite mindre komplicerat än så, efter att ämnet kom upp i en annan Stack Exchange-fråga:"Lägg till ett automatiskt nu-fält i en befintlig tabell." Där lade användaren till en ny kolumn i en befintlig tabell, med avsikten att automatiskt fylla i den med aktuellt datum/tid. De undrade om de skulle lämna NULL i den kolumnen för alla befintliga rader eller ange ett standardvärde (som 1900-01-01, förmodligen, även om de inte var explicita).
Det kan vara lätt för någon insatt att filtrera bort gamla rader baserat på ett symboliskt värde – trots allt, hur kunde någon tro att någon form av Bluetooth-doodd tillverkades eller köptes 1900-01-01? Tja, jag har sett detta i nuvarande system där de använder ett godtyckligt klingande datum i vyer för att fungera som ett magiskt filter, bara presentera rader där värdet kan lita på. Faktum är att i alla fall jag har sett hittills är datumet i WHERE-satsen datumet/tiden då kolumnen (eller dess standardbegränsning) lades till. Vilket är bra; det är kanske inte det bästa sättet att lösa problemet, men det är ett sätt.
Om du inte kommer åt tabellen via vyn, men detta innebär en känd värde kan fortfarande orsaka både logiska och resultatrelaterade problem. Det logiska problemet är helt enkelt att någon som interagerar med tabellen måste veta att 1900-01-01 är ett falskt, symboliskt värde som representerar "okänt" eller "inte relevant." För ett exempel i verkligheten, vad var den genomsnittliga släpphastigheten, i sekunder, för en quarterback som spelade på 1970-talet, innan vi mätte eller spårade något sådant? Är 0 ett bra symbolvärde för "okänt"? Vad sägs om -1? Eller 100? För att komma tillbaka till datum, om en patient utan ID läggs in på sjukhuset och är medvetslös, vilket ska de ange som födelsedatum? Jag tror inte att 1900-01-01 är en bra idé, och det var verkligen inte en bra idé när det var mer troligt att det var ett riktigt födelsedatum.
Prestandakonsekvenser av tokenvärden
Ur ett prestationsperspektiv kan falska eller "token"-värden som 1900-01-01 eller 9999-21-31 skapa problem. Låt oss titta på ett par av dessa med ett exempel baserat löst på den senaste frågan som nämns ovan. Vi har en widgettabell och efter några garantiåterkomster har vi beslutat att lägga till en EnteredService-kolumn där vi anger aktuellt datum/tid för nya rader. I det ena fallet lämnar vi alla befintliga rader som NULL, och i det andra kommer vi att uppdatera värdet till vårt magiska datum 1900-01-01. (Vi lämnar all form av komprimering utanför konversationen tills vidare.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Nu kommer vi att infoga samma 100 000 rader i varje tabell:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Sedan kan vi lägga till den nya kolumnen och uppdatera 10 % av de befintliga värdena med en fördelning av aktuella datum, och de andra 90 % till vårt tokendatum endast i en av tabellerna:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Slutligen kan vi lägga till index:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Använt utrymme
Jag hör alltid "diskutrymme är billigt" när vi pratar om val av datatyp, fragmentering och tokenvärden kontra NULL. Min oro är inte så mycket med diskutrymmet som dessa extra meningslösa värden tar upp. Det handlar mer om att det slösar minne när tabellen frågas. Här kan vi få en snabb uppfattning om hur mycket utrymme våra tokenvärden förbrukar före och efter att kolumnen och indexet läggs till:
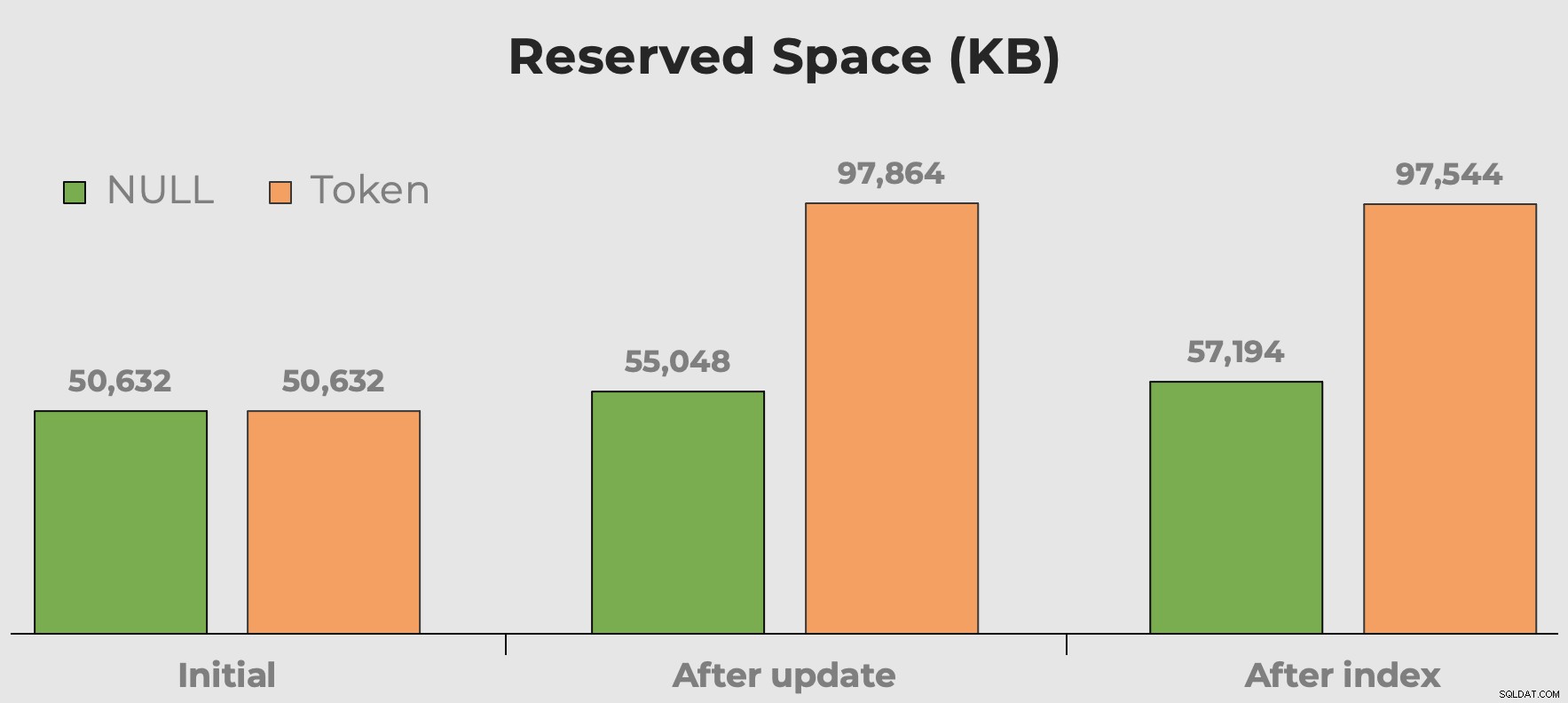 Reserverat tabellutrymme efter att ha lagt till en kolumn och lagt till ett index. Utrymmet fördubblas nästan med tokenvärden.
Reserverat tabellutrymme efter att ha lagt till en kolumn och lagt till ett index. Utrymmet fördubblas nästan med tokenvärden.
Frågekörning
Oundvikligen kommer någon att göra antaganden om data i tabellen och fråga mot kolumnen EnteredService som om alla värden där är legitima. Till exempel:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Tokenvärdena kan störa uppskattningar i vissa fall, men, ännu viktigare, de kommer att ge felaktiga (eller åtminstone oväntade) resultat. Här är exekveringsplanen för frågan mot tabellen med tokenvärden:
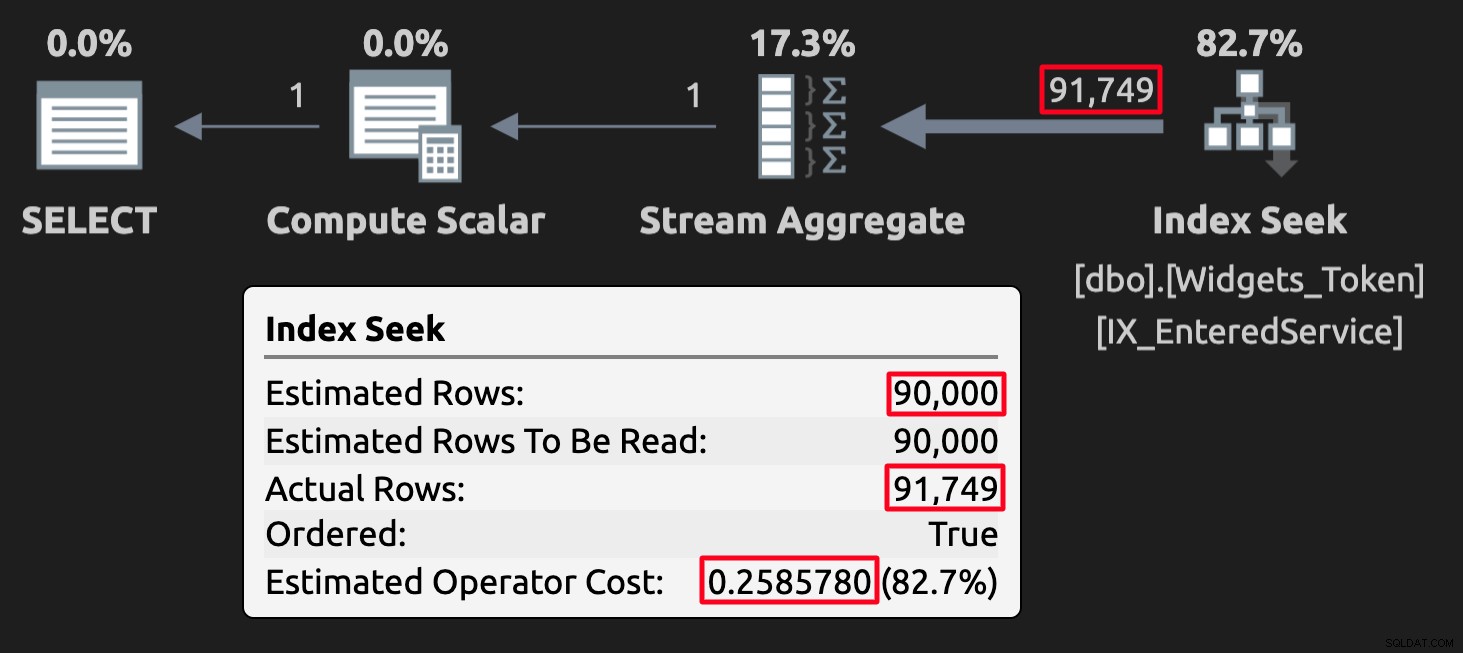 Exekveringsplan för tokentabellen; notera den höga kostnaden.
Exekveringsplan för tokentabellen; notera den höga kostnaden.
Och här är exekveringsplanen för frågan mot tabellen med NULL:
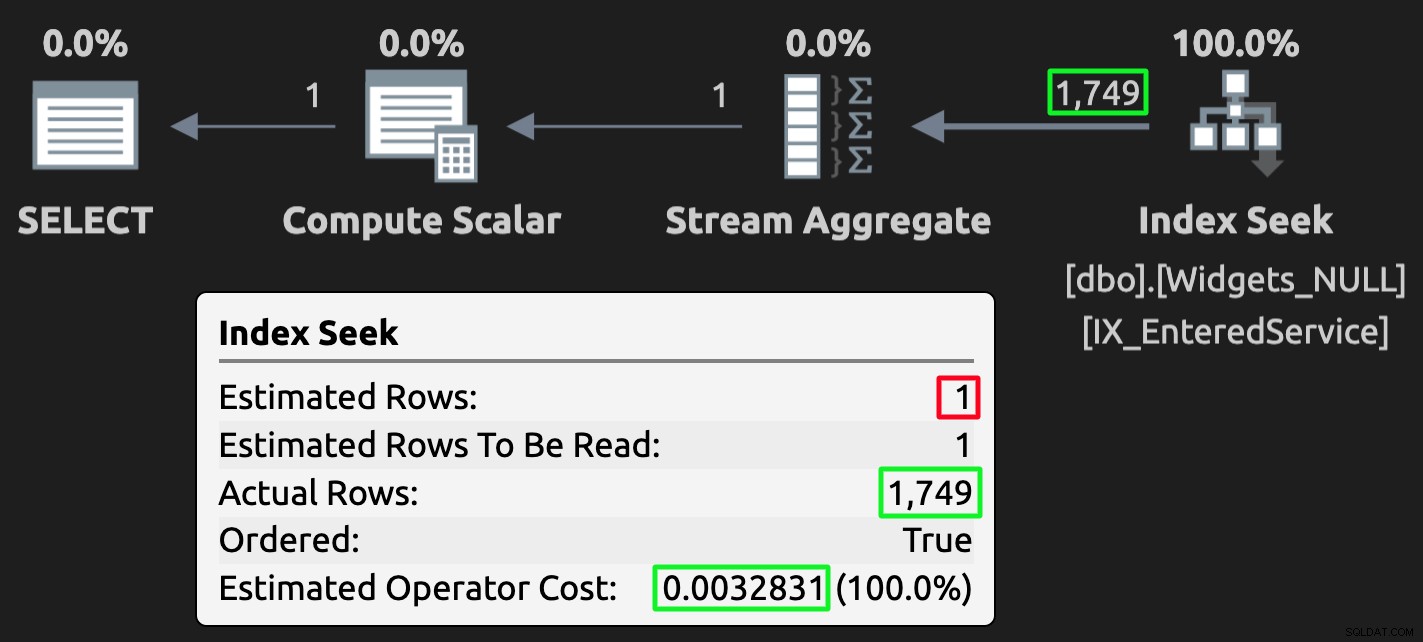 Exekveringsplan för NULL-tabellen; fel uppskattning, men mycket lägre kostnad.
Exekveringsplan för NULL-tabellen; fel uppskattning, men mycket lägre kostnad.
Samma sak skulle hända åt andra hållet om frågan bad om>={någon datum} och 9999-12-31 användes som det magiska värdet som representerar okänt.
Återigen, för de människor som råkar veta att resultaten är felaktiga specifikt för att du har använt symboliska värden, är detta inte ett problem. Men alla andra som inte vet det – inklusive framtida kollegor, andra arvtagare och underhållare av koden, och även framtida dig med minnesproblem – kommer förmodligen att snubbla.
Slutsats
Valet att tillåta NULL i en kolumn (eller att undvika NULL helt) bör inte reduceras till ett ideologiskt eller rädslabaserat beslut. Det finns verkliga, påtagliga nackdelar med att utforma din datamodell för att se till att inget värde kan vara NULL, eller att använda meningslösa värden för att representera något som lätt kunde ha inte lagrats alls. Jag föreslår inte att varje kolumn i din modell ska tillåta NULL; bara att du inte är emot idén av NULL.