Introduktion
Spolar tillbaka är specifika för operatorer på insidan av en kapslad slinga sammanfoga eller tillämpa. Tanken är att återanvända tidigare beräknade resultat från en del av en genomförandeplan där det är säkert att göra det.
Det kanoniska exemplet på en planoperatör som kan spola tillbaka är den lata Table Spool . Dess raison d’être är att cacha resultatrader från ett planunderträd och sedan spela upp dessa rader vid efterföljande iterationer om några korrelerade loopparametrar är oförändrade. Att spela om rader kan vara billigare än att köra om underträdet som genererade dem. För mer bakgrund om dessa prestandaspolar se min tidigare artikel.
Dokumentationen säger att endast följande operatörer kan spola tillbaka:
- Bordsspool
- Radräkningsspole
- Icke-klusterad indexspool
- Tabellvärderad funktion
- Sortera
- Fjärrfråga
- Förstå och Filter operatorer med ett Startuttryck
De tre första objekten är oftast prestationsspolar, även om de kan introduceras av andra skäl (när de kan vara både ivriga och lata).
Tabellvärderade funktioner använd en tabellvariabel, som kan användas för att cache och spela upp resultat under lämpliga omständigheter. Om du är intresserad av återspolning av tabellvärden, se mina frågor och svar på Database Administrators Stack Exchange.
Med de ur vägen handlar den här artikeln uteslutande om Sorts och när de kan spola tillbaka.
Sortera tillbakaspolningar
Sorter använder lagring (minne och kanske disk om de spills) så de har en kapabel anläggning att lagra rader mellan loop-iterationer. I synnerhet kan den sorterade utmatningen i princip spelas upp igen (spolas tillbaka).
Ändå, det korta svaret på rubrikfrågan, "Spolar sorters tillbaka?" är:
Ja, men du kommer inte att se det så ofta.
Sorteringstyper
Sorter finns i många olika typer internt, men för våra nuvarande syften finns det bara två:
- Sortering i minnet (
CQScanInMemSortNew).- Alltid i minnet; kan inte spilla till disk.
- Använder standardsnabbsortering för bibliotek.
- Maximalt 500 rader och två 8KB-sidor totalt.
- Alla ingångar måste vara körtidskonstanter. Vanligtvis innebär detta att hela sorteringsunderträdet måste bestå av endast Konstant genomsökning och/eller Compute Scalar operatörer.
- Endast explicit särskiljbar i utförandeplaner när omfattande showplan är aktiverad (spårningsflagga 8666). Detta lägger till extra egenskaper till Sortera operator, varav en är "InMemory=[0|1]".
- Alla andra sorter.
(Båda typerna av Sort operatören inkluderar deras Top N Sorter och Distinkt sortering varianter).
Spola tillbaka beteenden
-
Sortering i minnet kan alltid spola tillbaka när det är säkert. Om det inte finns några korrelerade loopparametrar, eller om parametervärdena är oförändrade från den omedelbart föregående iterationen, kan den här typen av sortering spela upp sina lagrade data istället för att köra om operatorer under den i exekveringsplanen.
-
Non-In-Memory Sorts kan spola tillbaka när det är säkert, men bara om Sortera operatorn innehåller högst en rad . Notera en Sortera input kan ge en rad på vissa iterationer, men inte andra. Körtidsbeteendet kan därför vara en komplex blandning av återspolningar och återbindningar. Det beror helt på hur många rader som ges till Sort på varje iteration vid körning. Du kan i allmänhet inte förutsäga vilken Sort kommer att göra på varje iteration genom att inspektera exekveringsplanen.
Ordet "säkert" i beskrivningarna ovan betyder:Antingen inträffade ingen parameterändring eller inga operatorer under Sortera har ett beroende av det ändrade värdet.
Viktig notering om genomförandeplaner
Exekveringsplaner rapporterar inte alltid återspolningar (och ombindningar) korrekt för Sortering operatörer. Operatören kommer att rapportera en återspolning om några korrelerade parametrar är oförändrade, och en ombindning annars.
För sorteringar som inte finns i minnet (oavgjort det vanligaste), kommer en rapporterad återspolning endast att spela upp de lagrade sorteringsresultaten om det finns högst en rad i sorteringsutdatabufferten. Annars kommer sorteringen att rapportera en spola tillbaka, men underträdet kommer fortfarande att köras om helt (en ombindning).
För att kontrollera hur många rapporterade återspolningar som var faktiska återspolningar, kontrollera Antal avrättningar egenskap på operatorer under Sortera .
Historik och min förklaring
Sortera Operatörens bakåtspolningsbeteende kan verka konstigt, men det har varit så här från (åtminstone) SQL Server 2000 till SQL Server 2019 inklusive (liksom Azure SQL Database). Jag har inte kunnat hitta någon officiell förklaring eller dokumentation om det.
Min personliga uppfattning är att Sort återspolningar är ganska dyra på grund av den underliggande sorteringsmaskinen, inklusive spillanläggningar, och användningen av systemtransaktioner i tempdb .
I de flesta fall kommer optimeraren att göra bättre för att introducera en explicit prestandaspool när den upptäcker möjligheten till dubbletter av korrelerade loopparametrar. Spooler är det billigaste sättet att cachelagra delresultat.
Det är möjligt att spela om en Sortera resultatet skulle bara vara mer kostnadseffektivt än en Spool när Sortera innehåller högst en rad. När allt kommer omkring, att sortera en rad (eller inga rader!) innebär faktiskt inte någon sortering alls, så mycket av omkostnaderna kan undvikas.
Ren spekulation, men någon var tvungen att fråga, så där är det.
Demo 1:Felaktiga återspolningar
Detta första exempel innehåller två tabellvariabler. Den första innehåller tre värden duplicerade tre gånger i kolumn c1 . Den andra tabellen innehåller två rader för varje matchning på c2 = c1 . De två matchande raderna särskiljs av ett värde i kolumnen c3 .
Uppgiften är att returnera raden från den andra tabellen med den högsta c3 värde för varje matchning på c1 = c2 . Koden är förmodligen tydligare än min förklaring:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
NO_PERFORMANCE_SPOOL tips finns för att förhindra att optimeraren introducerar en prestationsspool. Detta kan ske med tabellvariabler när t.ex. spårningsflagga 2453 är aktiverad, eller tabellvariabel uppskjuten kompilering är tillgänglig, så att optimeraren kan se den sanna kardinaliteten av tabellvariabeln (men inte värdefördelning).
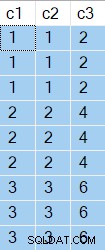
Frågeresultaten visar c2 och c3 returnerade värden är desamma för varje distinkt c1 värde:
Den faktiska genomförandeplanen för frågan är:
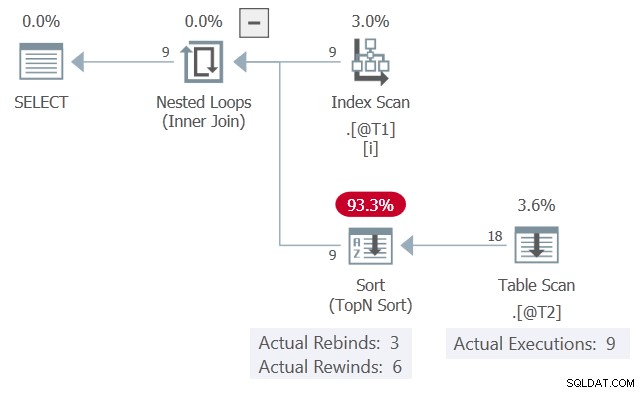
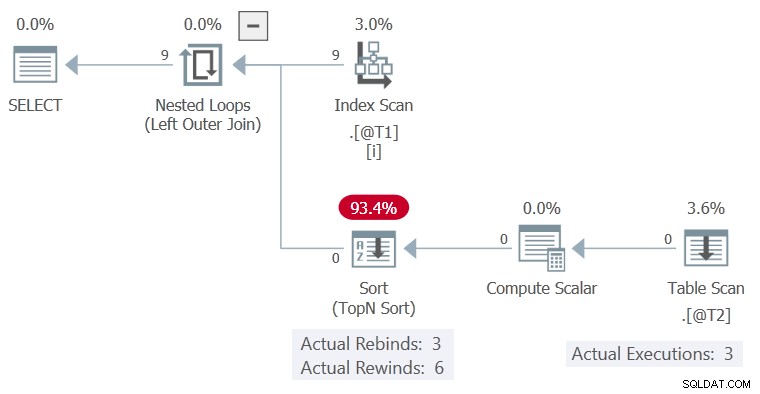
c1 värden, presenterade i ordning, matchar föregående iteration 6 gånger och ändras 3 gånger. Sortera rapporterar detta som 6 rewinds och 3 rebounds.
Om detta var sant, Table Scan skulle bara köras 3 gånger. Sortera skulle spela om (spola tillbaka) sina resultat vid de andra 6 tillfällena.
Som det är kan vi se Table Scan kördes 9 gånger, en gång för varje rad från tabellen @T1 . Inga tillbakaspolningar har skett här .
Demo 2:Sortera tillbakaspolningar
Det föregående exemplet tillät inte Sortera att spola tillbaka eftersom (a) det inte är en In-Memory Sortering; och (b) på varje iteration av slingan, Sortera innehöll två rader. Plan Explorer visar totalt 18 rader från Table Scan , två rader på var och en av 9 iterationer.
Låt oss justera exemplet nu så att det bara finns ett rad i tabellen @T2 för varje matchande rad från @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaten är desamma som tidigare eftersom vi behöll den matchande raden som sorterades högst i kolumn c3 . Utförandeplanen är också ytligt lik, men med en viktig skillnad:
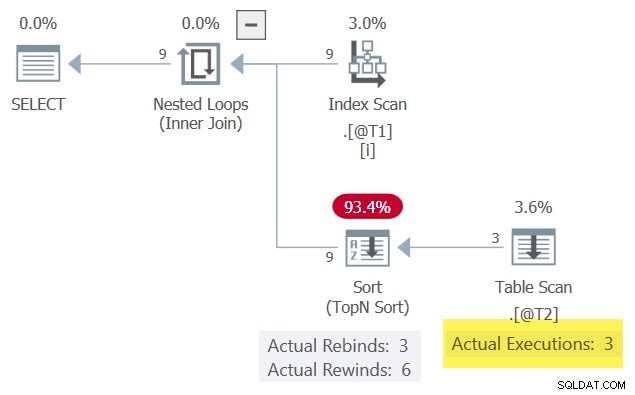
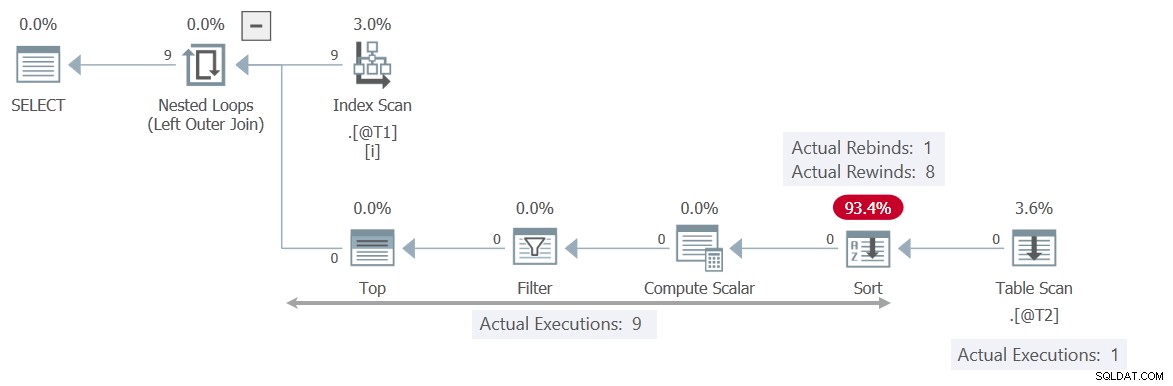
Med en rad i Sortera när som helst kan den spola tillbaka när den korrelerade parametern c1 ändras inte. Table Scan exekveras endast 3 gånger som ett resultat.
Lägg märke till Sorteringen producerar fler rader (9) än den tar emot (3). Detta är en bra indikation på att en Sortera har lyckats cachelagra en resultatuppsättning en eller flera gånger – en lyckad bakåtspolning.
Demo 3:Rewinding Nothing
Jag nämnde tidigare att en Sortera som inte finns i minnet kan spola tillbaka när den innehåller högst en rad.
För att se det i aktion med noll rader , ändrar vi till en OUTER APPLY och lägg inte några rader i tabellen @T2 . Av skäl som kommer att bli uppenbara inom kort kommer vi också att sluta projicera kolumn c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaten har nu NULL i kolumn c3 som förväntat:
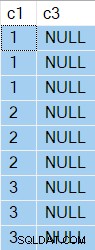
Utförandeplanen är:
Sortera kunde spola tillbaka utan rader i bufferten, så Table Scan kördes endast 3 gånger, varje tidskolumn c1 ändrat värde.
Demo 4:Maximal Rewind!
Liksom de andra operatörerna som stöder återspolning, en Sortera kommer bara att binda om dess underträd om en korrelerad parameter har ändrats och underträdet beror på det värdet på något sätt.
Återställer kolumnen c2 projektion till demo 3 kommer att visa detta i aktion:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaten visar nu två NULL kolumner förstås:
Utförandeplanen är helt annorlunda:
Den här gången Filtret innehåller kryssrutan T2.c2 = T1.c1 , vilket gör Table Scan oberoende av det aktuella värdet på den korrelerade parametern c1 . Sortera kan säkert spola tillbaka 8 gånger, vilket innebär att skanningen endast utförs en gång .
Demo 5:In-Memory Sortering
Nästa exempel visar en Sortering i minnet operatör:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Resultaten du får kommer att variera från exekvering till exekvering, men här är ett exempel:
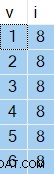
Det intressanta är värdena i kolumn i kommer alltid att vara densamma — trots ORDER BY NEWID() klausul.
Du har förmodligen redan gissat att orsaken till detta är Sorteringen cacheresultat (spolning bakåt). Utförandeplanen visar Konstant skanning körs bara en gång, producerar 11 rader totalt:
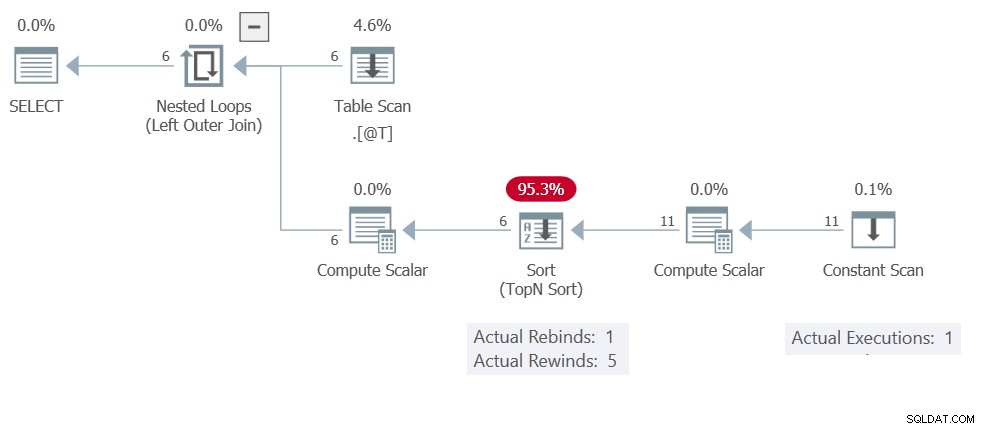
Denna Sortera har bara Compute Scalar och Konstant genomsökning operatorer på dess inmatning så det är en In Memory Sortering . Kom ihåg att dessa inte är begränsade till högst en enskild rad – de kan rymma 500 rader och 16 kB.
Som nämnts tidigare är det inte möjligt att explicit se om en Sortera är I minnet eller inte genom att inspektera en vanlig utförandeplan. Vi behöver omfattande showplan-utdata , aktiverad med odokumenterad spårningsflagga 8666. Med den aktiverad visas extra operatörsegenskaper:
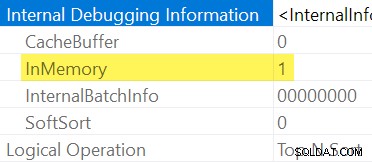
När det inte är praktiskt att använda odokumenterade spårningsflaggor kan du dra slutsatsen att en Sortera är "InMemory" genom dess Input Memory Fraction är noll och Minnesanvändning element som inte är tillgängliga i showplan efter körning (på SQL Server-versioner som stöder den informationen).
Tillbaka till exekveringsplanen:Det finns inga korrelerade parametrar så Sortera är gratis att spola tillbaka 5 gånger, vilket betyder Konstant genomsökning exekveras endast en gång. Ändra gärna TOP (1) till TOP (3) eller vad du vill. Omspolningen innebär att resultaten blir desamma (cachelagrade/återspolade) för varje inmatningsrad.
Du kan störas av ORDER BY NEWID() klausul som inte hindrar återspolning. Detta är verkligen en kontroversiell punkt, men inte alls begränsad till sorter. För en mer utförlig diskussion (varning:möjligt kaninhål) vänligen se denna Q &A. Den korta versionen är att detta är ett medvetet produktdesignbeslut som optimerar för prestanda, men det finns planer på att göra beteendet mer intuitivt över tiden.
Demo 6:Ingen sortering i minnet
Detta är samma som demo 5, förutom att den replikerade strängen är ett tecken längre:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Återigen kommer resultaten att variera per utförande, men här är ett exempel. Lägg märke till i värdena är nu inte desamma:

Det extra tecknet är precis tillräckligt för att skjuta upp den uppskattade storleken på den sorterade datan över 16KB. Detta innebär en In-Memory Sortering kan inte användas, och tillbakaspolningarna försvinner.
Utförandeplanen är:
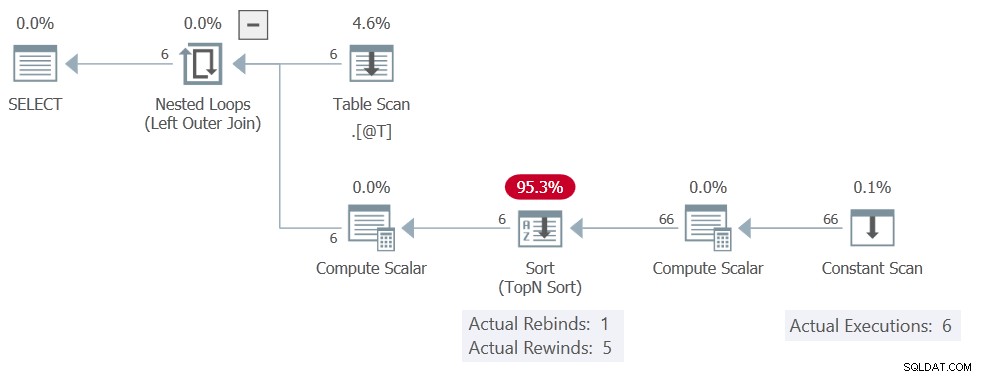
Sortera fortfarande rapporter 5 bakåtspolningar, men Konstant genomsökning exekveras 6 gånger, vilket betyder att inga återspolningar har skett. Den producerar alla 11 rader på var och en av 6 avrättningar, vilket ger totalt 66 rader.
Sammanfattning och slutliga tankar
Du kommer inte att se en Sortering operatör verkligen spola tillbaka väldigt ofta, även om du kommer att se att det sägs att det gjorde det ganska mycket.
Kom ihåg att en vanlig Sortering kan bara spola tillbaka om det är säkert och det finns högst en rad i sorteringen åt gången. Att vara "säker" betyder antingen ingen förändring i slingkorrelationsparametrar eller ingenting under Sort påverkas av parameterändringarna.
En In-Memory Sortering kan arbeta på upp till 500 rader och 16 KB data hämtade från Konstant sökning och Compute Scalar endast operatörer. Den kommer också bara att spola tillbaka när den är säker (produktbuggar åt sidan!) men är inte begränsad till högst en rad.
Dessa kan verka som esoteriska detaljer, och jag antar att de är det. Så att säga, de har hjälpt mig att förstå en genomförandeplan och hitta bra prestandaförbättringar mer än en gång. Kanske kommer du att hitta informationen användbar en dag också.
Håll utkik efter Sorts som producerar fler rader än de har på sin input!
Om du vill se ett mer realistiskt exempel på Sortera spolar tillbaka baserat på en demo som Itzik Ben-Gan tillhandahållit i del ett av hans Closest Match serier, se Närmast matchning med sorteringsbakåt.